Departament de Química Física - SGI Origin-2000
|
Fecha de actualización: 26 de Marzo 2002
|
Aqui tienes la Página en Acrobat en un
Fichero PDF

Descripción
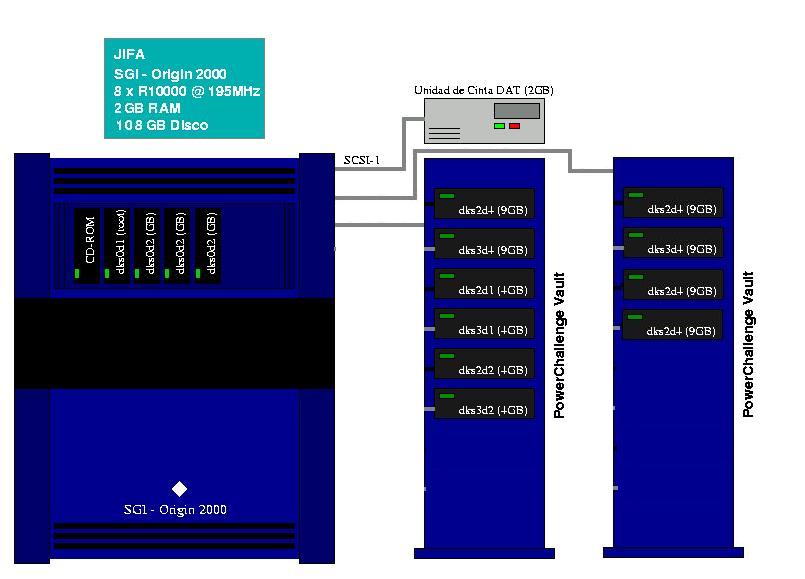
Ordenador SGI Origin-2000, la máquina se denomina jifa
y tiene asignado el número IP
147.156.132.9.
Hardware
Jifa dispone de 8 procesadores MIPS R10000 a 195MHz . La
memoria RAM total del sistema es 2.0GB (512MB por nodo, 2 procesadores por nodo)
y el área de disco es de aproximadamente en los scratch de 81GB en /scr1
y 18 GB en /scr2.
Software
- Versión 6.5.14 del sistema operativo IRIX.
- Los compiladores (C, C++, Fortran 77 y Fortran 90) se incluyen dentro del
paquete SGI Compilers-7.2 (todos ellos debidamente licenciados).
- También se han instalado las herramientas de paralelización
más usuales:
- El paralelizador automático (auto_pp) para todos los compiladores.
- Algunas herramientas de desarrollo de SGI (WorkShop, WorkShop
MPF y Performance CoPilot).
- Las librerías de paso de mensajes PVM y MPI adaptadas
a la arquitectura N2MA de Silicon Graphics.
- En lo que se refiere a software de libre distribución, contamos
con:
- Herramientas de compresión/descompresión (gzip).
- Editor Emacs.
- TeX/LaTeX (sólo para un apuro: no es una de las versiones más
modernas que he visto y no está especialmente bien configurado).
- GhostScript/Ghostview, etc...
- El sistema de colas Cray NQE/NQS (Versión 3.3.0.10).
- Software de Química Computacional:
- Gaussian94 (/u/util/g94/...)
- Gamess96 (/u/util/gamess/...), versiones paralela y secuencial.
- Gaussian98 y GaussView(?)
- Etc...
Acceso al sistema
A jifa sólo se puede (debe) acceder a través
de qfgate (que es bohr visto desde la red del campus). La máquina sólo
proporciona servicios de red a los hosts de la subred de cálculo.
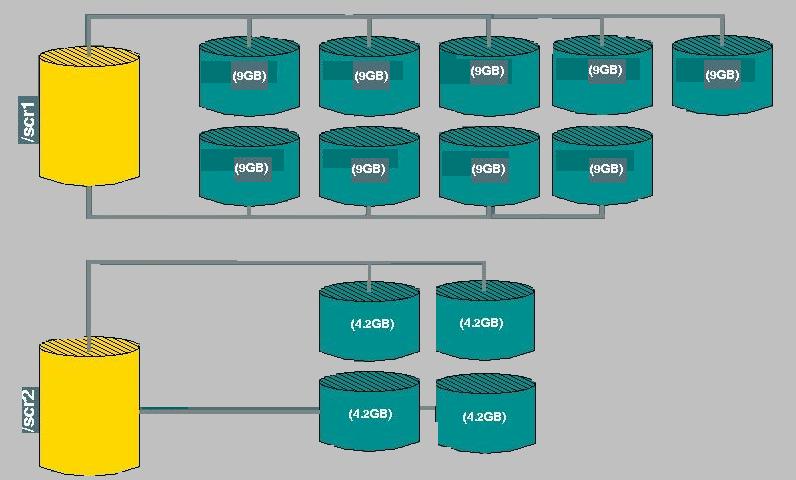
Las áreas de scratch
Disponemos de dos áreas de scratch son 2 una de aproximadamente 81GB
y otra de 18 GB y denominadas /scr1 y /scr2. Estas áreas están
construidas como indica la figura:
Como se ha dicho, las áreas de scratch están
configuradas para obtener velocidad. Esto es incompatible con fiabilidad:
recordad que si falla algún disco, todo el contenido del área
de scratch se pierde y no hay backup...
Todavía no se ha establecido una política
de borrado automático de estas áreas. La tolerancia en este aspecto
dependerá en gran medida del comportamiento de los usuarios respecto
a la basura que generan los cálculos. Por favor, borrad
siempre las áreas de scratch al acabar un cálculo,
bien de forma automática en el propio script de submisión,
bien manualmente en el caso de cálculos fallidos. Este aspecto NO
ES RESPONSABILIDAD DEL SISTEMA DE COLAS NI DEL ADMINISTRADOR DEL SISTEMA,
así que el buen funcionamiento depende de la actitud individual de los
usuarios.
El sistema de colas
El sistema de colas es el Cray NQE/NQS. La configuración
es todavía experimental y será necesario tener el sistema en producción
para realizar los ajustes
finos que permitan obtener el máximo rendimiento.
Como en tiberio, sólo existe una cola de submisión
(denominada aquí default). Es necesario, por tanto, especificar
lo más detalladamente posible los recursos que empleará el cálculo.
De este modo el sistema de colas es capaz de ajustar la demanda a los recursos
disponibles, optimizando su uso. Cuanto más detallados estén los
recursos, mayor sera la prioridad intracola de un trabajo (ya que, por omision,
el sistema asigna el máximo aplicable a la cola).
Las colas definidas en este momento son:
|
Nombre Cola
|
CPU Total
|
CPU por PE
|
Memoria
|
Scratch
|
Otros límites
|
|
gran
|
96:00:00.00
|
60:00:00.00
|
1024MB
|
12GB
|
mpp_pe = 4
queue_run = 2
user_run = 1 |
|
mitjana
|
48:00:00.00
|
30:00:00.00
|
512MB
|
8GB
|
mpp_pe = 4
queue_run = 6
user_run = 2 |
|
petita
|
6:00:00.00
|
4:00:00.00
|
256MB
|
4GB
|
mpp_pe = 4
queue_run = 4
user_run = 2 |
Hay también definidos una serie de límites
globales, cuya misión es la de garantizar que el total de trabajos
en ejecución no sobrepase los recursos del sistema:
Límite global de Jobs:
8
Límite de Jobs por usuario:
2
Memoria global:
2GB
Límite global PE:
8 |
Las interacciones entre los límites por cola
y los límites globales pueden dar lugar a comportamientos
'aparentemente' extraños
del sistema de colas, por lo que no es suficiente aplicar la 'lógica
simple' si algún trabajo no entra en ejecución instántaneamente...
En cuanto a la prioridad intracola, se calcula teniendo
en cuenta una serie de factores ponderados (scheduling factors).
En este sistema, los pesos asignados son:
|
Scheduling
|
Peso
|
| Share |
0 |
| CPU |
10 |
| Memory |
50 |
| Time |
30 |
| Mpp_CPU |
10 |
| Mpp_PE |
10 |
| User Priority |
10 |
Factores de pondereación más grandes implican
menor prioridad intracola (excepto el factor Time). En este sistema,
como se puede ver en la tabla, el factor crítico es la demanda de memoria.
¿Cómo se submite un trabajo?
De momento no es posible encaminar los trabajos a jifa desde
LoadLeveler, por lo que es necesario submitirlos desde la propia máquina.
Esto hace que LoadLeveler y NQE/NQS se comporten como sistemas independientes,
cada uno con sus propios límites. Teniendo en cuenta que también
es posible calcular en tiberio (y muy bien), por favor, no
os dediquéis a saturar todos los sistemas de colas disponibles.
Una buena política de uso sería reservar jifa para aquellos trabajos
que tengan un tratamiento más desfavorable en la máquina del SIUV
(trabajos de cola gran multiprocesador).
Algunos puntos imprescindibles a
la hora de submitir un trabajo son:
- Ajustar lo más finamente posible el límite de memoria empleando
la directiva #QSUB -lM xxxmb(límite
por Job). Si el Job consta de más de un proceso, se puede
especificar la memoria máxima que cada uno puede utilizar mediante
la directiva #QSUB -lm xxxmb
(límite por Proceso). El límite per Proc (-lm)
tiene poco sentido dado el tipo de trabajos que corren en esta instalación,
por lo que lo mejor es poner el mismo límite en ambas directivas.
- Especificar el consumo de CPU total mediante la directiva #QSUB
-lT hh:mm:ss. En el caso de que el Job conste de
más de un proceso es posible limitar el tiempo máximo de CPU
por proceso mediante la directiva #QSUB
-lt hh:mm:ss. El funcionamiento de ambos límites
es el siguiente:
- La suma del tiempo consumido por todos los procesos dentro de un Job
nunca superará el límite per Job (-lT).
- Un proceso individual nuncá superará el tiempo especificado
en el límite per Proc (-lt).
Si un proceso alcanza este límite, será interrumpido y el
Job continuará con el siguiente proceso... y así hasta
acabar de forma natural o alcanzar el límite per Job.
En el caso de cálculos paralelos, también puede ser interesante
especificar el tiempo de CPU por PE (Proccesor Element, es decir,
CPU) mediante la directiva #QSUB -l
p_mpp_t=hh:mm:ss, junto con el tiempo de CPU total de todos
los PE's mediante la directiva #QSUB
-l mpp_t=hh:mm:ss. Más abajo se indica en detalle
cómo calcular estos valores mediante un ejemplo.
- Utilizar la directiva #QSUB -ro
para que funcione correctamente el Checkpoint/Restart de NQE/NQS. También
es adecuado utilizar la directiva #QSUB
-eo (que redirecciona el Standard Output y el Standard
Error al mismo fichero). El Checkpoint funciona en todas
las aplicaciones secuenciales y paralelas (incluyendo Gaussian94).
- Para cálculos paralelos, es necesario especificar el número
de PE's que se quiere utilizar mediante la directiva #QSUB
-l mpp_p=n (2 <= n
<= 4). Observad que en esta configuración no existe la distinción
entre colas paralelas y secuenciales, por lo que en cálculos paralelos
es necesario solicitar el número de procesadores que se quiere utilizar.
Si no se especifica ningún límite, el sistema considerará
que el Job es secuencial y sólo le asignará un procesador (Nota:
este punto ha cambiado desde la última revisión del sistema
de colas). Recordad que vuestro Job no utilizará n
procesadores sólo por el hecho de que hagáis la correspondiente
reserva de PE's en el sistema de colas: es responsabilidad de la aplicación
(y del usuario) hacer uso del paralelismo.
A continuación, dos ejemplos:
|
Ejemplo 1: Script de submisión
de Gaussian94 - secuencial
#!/bin/ksh
#
# Memoria total.
#QSUB -lM 90mb
# Memoria por proceso.
#QSUB -lm 90mb
# Limite de CPU global.
#QSUB -lT 18:00:00.00
# Limite de CPU por proceso.
#QSUB -lt 18:00:00.00
# Para garantizar que funcione
el CheckPoint.
#QSUB -ro
#QSUB -eo
# Fichero de incidencias.
#QSUB -o tests.out
# Espacio máximo en
disco, total y por fichero.
#QSUB -lF 2gb
#QSUB -lf 2gb
# Enviar e-mail cuando acabe
el calculo.
#QSUB -me
#
# Definimos el fichero input
y el
# directorio donde se encuentra
WDIR=/u/$USER/test
FILE="test5"
#
# Incluimos definiciones
de Gaussian94
# si no lo hicimos antes...
. /util/g94/private/g94.profile
#
# Define donde esta el area
de scratch
SCR=`/u/loadl/macros/get_files`
#
# Ejecutamos el programa
cd $SCR
runG94 -s $SCR $WDIR/$FILE
#
# Recuperamos ficheros y
borramos el scratch.
cd /scr1/$USER
cp $SCR/$FILE.log /scr1/$USER
cp $SCR/$FILE.chk /scr1/$USER
rm -fr $SCR
exit
|
|
Ejemplo 2: Script de submisión de
Gaussian94 - paralelo
#!/bin/ksh
#
# Solicitamos cuatro procesadores.
#QSUB -l mpp_p=4
# Memoria total del Job.
#QSUB -lM 240mb
# Memoria maxima por proceso.
#QSUB -lm 240mb
# Tiempo de CPU total del
Job*.
#QSUB -lT 45:00:00
# Tiempo de CPU maximo por
proceso.
#QSUB -lt 45:00:00
# Tiempo de CPU total de
los PE.
#QSUB -l mpp_t=45:00:00.00
# Tiempo maximo de CPU por
PE*.
#QSUB -l p_mpp_t=17:00:00.00
# Para garantizar que funcione
el CheckPoint.
#QSUB -ro
#QSUB -eo
# Fichero de incidencias
#QSUB -o tests.out
# Espacio máximo en
disco, total y por fichero
#QSUB -lF 6gb
#QSUB -lf 6gb
# Enviar e-mail cuando acabe
el calculo.
#QSUB -me
#
# Definimos el fichero input
y el
# directorio donde se encuentra
WDIR=/u/$USER/ptest
FILE="ptest4_p4"
#
# Incluimos definiciones
de Gaussian94
# si no lohicimos antes...
. /util/g94/private/g94.profile
#
# Define donde esta el area
de scratch
SCR=`/u/loadl/macros/get_files`
#
# Ejecutamos el programa
cd $SCR
runG94 -s $SCR $WDIR/$FILE
#
# Recuperamos ficheros y
borramos el scratch.
cd /scr1/$USER
cp $SCR/$FILE.log /scr1/$USER
cp $SCR/$FILE.chk /scr1/$USER
rm -fr $SCR
exit
|
(*) ¿Por qué
estos números? Veamos una explicación detallada:
La configuración del sistema puede cambiar
sin previo aviso, por lo que la información contenida
en este documento puede ser obsoleta. La descripción
exacta de la configuración del
sistema de colas se puede obtener utilizando
el comando qstat.
(más información: man
qstat).
|
{kind=link}