![]()
5. Teoremas
Centrales del Límite
Teorema de Moivre
Teorema Central del
límite; Forma de Lyapounov
Teorema
Central del Límite ; Forma Lindeberg-Lévy
Teorema Central del
Límite ; convergencia de la distribución de Poisson
Apéndice 1:Corrección por convergencia discreta-continua.
Apéndice 2. Utilización de convergencias en el caso de Binomial y
Poisson
En este capítulo trataremos de las propiedades asintóticas que se dan en las variables aleatorias , o mejor , en las sucesiones de variables aleatorias. Estas propiedades y teoremas son , y han sido , imprescindibles para el desarrollo de la inferencia estadística
1. Convergencia de sucesiones de variables aleatorias.
Consideramos una sucesión infinita de variables aleatorias {Xn} : {X1,X2,…,Xn,…}
Donde cada Xi es una variable aleatoria con su correspondiente distribución de probabilidad. , puede darse el caso que la sucesión converja a una variable aleatoria (límite) X , con una distribución de probabilidad asociada.
Por ejemplo: {Xn} con Xn ® B(n,p) para n=1,2,….
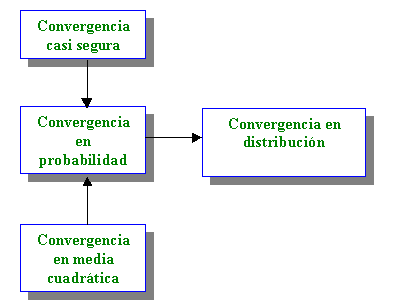
Así, y definidas todas las variables aleatorias que componen la sucesión sobre el mismo espacio probabilístico ; dicha sucesión podrá converger a una variable aleatoria X de distintas maneras o tipos :
Convergencia casi-segura
Convergencia en probabilidad
Convergencia en media cuadrática
Convergencia en ley ( o distribución)
Así :
Una sucesión de variables
aleatorias, {Xn} , converge con probabilidad 1, o de forma casi segura,
a una variable aleatoria X ( que puede degenerar en una constante K) cuando se cumple que:
![]()
Una
sucesión de variables aleatorias, {Xn} , converge en probabilidad ,
a una variable aleatoria X ( que puede degenerar en una constante K) cuando se cumple que:
"e
>0
o bien considerando su complementario

de esta forma interpretaremos que ![]()
cuando en el límite , la probabilidad de que sucesión de variables aleatorias y aquella
a la que converge difieran (en valor absoluto) en un valor mayor e (pequeño) es cero ( o complementariamente).
Ha de tenerse en cuenta en este caso que la
sucesión sólo implica a la sucesión de las probabilidades de los sucesos y no a las
variables en sentido matemático
Una sucesión de variables aleatorias, {Xn} , converge en media cuadrática,
a una variable aleatoria X (que puede degenerar en una constante K) cuando se cumple que:
![]()
de esta forma interpretaremos que ![]()
cuando en el límite , la dispersión de la sucesión de variables aleatorias tomando como
origen de ésta la variable a la que converge , es 0. Es de importancia notar que
pueden plantearse diversos tipos de convergencias en media dependiendo del orden r del
exponente (en este caso 2)
Una sucesión de variables aleatorias, {Xn} , converge en ley o en
distribución
a una variable aleatoria X , cuando se cumpla alguna de las siguientes condiciones , en el
convencimiento de que si se cumple una se cumplirán las restantes :
a) Si para toda función real g se verifica que :
![]()
b)
Si para todo número real t se cumple que : ![]()
c)
Si para todo par de puntos a y b ; tales que b > a se cumple que :
![]()
![]()
de esta forma interpretaremos que ![]()
cuando en el límite el comportamiento de la función de distribución de la sucesión de
variables aleatorias y la de aquella a la que converge son iguales .
Existen relaciones de implicación (demostrables) entre los diversos tipos de convergencia :
Así :
La convergencia en media cuadrática implica la convergencia en probabilidad , no siendo cierto (generalmente) el comportamiento inverso :
Luego ![]()

![]()
La convergencia casi
segura implica la convergencia en probabilidad , no siendo cierto (generalmente) el
planteamiento inverso :
Luego ![]()
![]()
La convergencia en
probabilidad implica la convergencia en distribución , no siendo cierto (generalmente) el
planteamiento contrario :
Luego ![]()
![]()
Esquemáticamente quedaría :
2. Leyes de los grandes números. Teoremas límite
Reciben el nombre de leyes de los grande números aquellas que parten del comportamiento
asintótico
de la variable ![]() ; que no
es otra cosa que el valor medio de las n variables que componen una
sucesión ;
; que no
es otra cosa que el valor medio de las n variables que componen una
sucesión ;
Así si estamos ante una sucesión {Xn}
establecemos que ![]()
el comportamiento de ![]() da lugar a las denominadas leyes de los grandes
números ; de manera que , si la convergencia que se produce lo es en "probabilidad"
, dará lugar a una ley débil de los grandes números . Si la
convergencia que se da es en forma "casi segura" la ley a la que
de lugar se conocerá como ley fuerte de los grandes números .
Y , por último , si la convergencia a que da lugar el planteamiento lo es en "distribución"
, y además esta es normal , dará lugar a lo que conocemos como teoremas centrales del
límite.
da lugar a las denominadas leyes de los grandes
números ; de manera que , si la convergencia que se produce lo es en "probabilidad"
, dará lugar a una ley débil de los grandes números . Si la
convergencia que se da es en forma "casi segura" la ley a la que
de lugar se conocerá como ley fuerte de los grandes números .
Y , por último , si la convergencia a que da lugar el planteamiento lo es en "distribución"
, y además esta es normal , dará lugar a lo que conocemos como teoremas centrales del
límite.
3. Ley débil de los grandes números
Concretando lo antes citado. Una sucesión de variables aleatorias {Xn}
cumple la ley débil de los grandes números si dada una sucesión de constantes {Cn}
la variable ![]() verifica que
verifica que ![]() es decir se cumpla que :
es decir se cumpla que :

pudiéndose interpretar como que para un valor muy alto de n (en el límite) no deben existir diferencias entre el valor medio de una sucesión y una determinada constante.
Dentro de la ley débil de los grandes números se pueden establecer algunos teoremas importantes y que enunciamos sin demostrar .
Partiendo del planteamiento general , es decir que dada una sucesión {Xn}
en la que concretamos ![]()
el teorema de Chebyshev hace verificar que
:![]() o , lo que es lo mismo
o , lo que es lo mismo ![]()
por lo que podría demostrarse que

Es decir , en el limite , la probabilidad de
que haya diferencias entre la variable valor medio de la sucesión y el valor esperado de
la variable valor medio de dicha sucesión es cero . Como caso particular que ayuda a
comprender mejor esta situación , tendríamos que : si las variables aleatorias de la
sucesión tienen todas la misma distribución , la variable ![]() (valor medio de la sucesión) converge en
probabilidad a la media de la distribución común , m
(valor medio de la sucesión) converge en
probabilidad a la media de la distribución común , m
El teorema se basa en las mismas condiciones de partida que el de Chebyshev , incidiendo además en que las variables que forman la sucesión han de ser independientes y todas con una misma y común distribución de probabilidad ; si así ocurre se puede demostrar que :
![]() siendo m la media común a las variables que forman la sucesión
siendo m la media común a las variables que forman la sucesión
Evidentemente , y por lo enunciado , puede tomarse este teorema como el caso particular (ya citado) del teorema de Chebyshev
Es posible generalizar el teorema de Kintchine para todos los momentos
ordinarios y no sólo para la media con lo que tendremos que : ![]() es decir la variable momento ordinario de orden r
de la sucesión converge en probabilidad al momento de orden r de la
distribución común a todas las variables que forman la sucesión.
es decir la variable momento ordinario de orden r
de la sucesión converge en probabilidad al momento de orden r de la
distribución común a todas las variables que forman la sucesión.
Con el mismo planteamiento que el anterior , es decir ;
Dada una sucesión de variables aleatorias {Xn}
y
estableciendo una nueva variable ![]()
y siendo ,en este caso, las variables que forman la sucesión dicotómicas de parámetro p
El
teorema de Bernouilli plantea que ![]()
o , de otra manera 
Es decir , que la variable media de la sucesión de dicotómicas de parámetro p converge en probabilidad al parámetro p común a todas ellas
De otro modo podríamos plantear la sucesión
de (n) dicotómicas de parámetro p como una binomial y así:
la sucesión {Xn} sería una B(X, n, p)
donde la variable aleatoria anterior ![]() sería ,
ahora , la razón frecuencial de éxitos o frecuencia relativa del suceso , X/n ; de
esta manera el teorema de Bernouilli nos diría que:
sería ,
ahora , la razón frecuencial de éxitos o frecuencia relativa del suceso , X/n ; de
esta manera el teorema de Bernouilli nos diría que:

es decir, "la razón frecuencial de éxitos converge en probabilidad a la probabilidad de éxito de una binomial"
Para demostrarlo partimos de la conocida desigualdad de Chebyshev , así:
![]()
 haciendo
haciendo

y
dado que conocemos que en la binomial m
=p·q y ![]()
tendremos que : 
dividiendo por n (los miembros del primer término) y despejando tendríamos:
 o , lo que
es lo mismo
o , lo que
es lo mismo
 y , dado que el
valor máximo de p·q=0,4
y , dado que el
valor máximo de p·q=0,4
tendremos que:
(1)![]()
 y que evidentemente tiende a 0 cuando n tiende a infinito :
y que evidentemente tiende a 0 cuando n tiende a infinito :
demostrando que ![]()
Como curiosidad ,se ha establecido en (1) una cota de probabilidad que nos permite calcular la probabilidad máxima con la que diferirán en una determinada cantidad la "razón frecuencial de éxitos" y la "probabilidad de éxito" de una binomial .
Así , y como ejemplo , nos planteamos;
Si nos planteamos que la probabilidad sea
inferior a 0,10 , para el hecho de que , al lanzar una moneda con el ánimo de conseguir
caras , la diferencia entre las que han salido y las que debieran haber salido (la mitad)
sea superior al 2% ,
¿Cuántas veces debemos de lanzar la moneda?
Nos planteamos conocer n (número de lanzamientos) , despejando de (1)
Tendremos  veces lanzaremos para que la diferencia entre el número de caras que han de salir (3125)
y las que verdaderamente saldrán , sea mayor del 2% (mas, menos 125 caras) ,con una
probabilidad inferior a 0,1.
veces lanzaremos para que la diferencia entre el número de caras que han de salir (3125)
y las que verdaderamente saldrán , sea mayor del 2% (mas, menos 125 caras) ,con una
probabilidad inferior a 0,1.
Es conveniente , por último , precisar , que el teorema de Bernouilli demuestra la estabilidad de las frecuencias relativas de éxito entorno a la probabilidad de éxito , no asegurando que sea la verdadera probabilidad de éxito la derivada de las frecuencias relativas de éxito
4. Ley fuerte de los grandes números
Una sucesión {Xn}![]() se
comporta u obedece la ley fuerte de los grandes si :
se
comporta u obedece la ley fuerte de los grandes si :
existiendo dos sucesiones de constantes {a n} y {b n}
La nueva variable ![]()
en combinación con las sucesiones de
constantes , cumple 
Relevantemente , sea ![]() la suma de constantes cada una de ellas la media de cada
una de las variables de la sucesión {Xn}
la suma de constantes cada una de ellas la media de cada
una de las variables de la sucesión {Xn}![]()
y : ![]()
tenemos , además
, que 
Dado que ![]() y
y ![]() tendremos que :
tendremos que :

Y así 
explicitándose , de esta manera más simple , la ley fuerte de los grandes números.
Dentro de la ley fuerte de los grandes números se pueden establecer algunos teoremas importantes y que enunciamos sin demostrar .
Dada una sucesión de variables aleatorias
independientes {Xn}![]() con medias
con medias ![]() y varianza
y varianza ![]()
estableciendose ![]() y
y 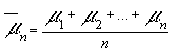
se cumple que existe ley fuerte de los grandes números ; así
![]() ó bien .
ó bien .
![]()
Por lo que la variable aleatoria media de una sucesión converge de manera casi segura a la media de las medias de las variables que forman la sucesión .
Si consideramos una muestra
como una sucesión de variables aleatorias {Xn}![]() que procede de ser un subconjunto
de la población , tomada ésta como otra sucesión de tamaño mayor
(máximo-completa-segura) . Evidentemente con la misma función de probabilidad para todas
las variables de la sucesión (muestra) ; el teorema de Glivenko-Cantelli nos indica que
la función de distribución de probabilidad común a las variables de la sucesión
muestra , convergen de manera "casi segura" a la verdadera función de
distribución de la población , así :
que procede de ser un subconjunto
de la población , tomada ésta como otra sucesión de tamaño mayor
(máximo-completa-segura) . Evidentemente con la misma función de probabilidad para todas
las variables de la sucesión (muestra) ; el teorema de Glivenko-Cantelli nos indica que
la función de distribución de probabilidad común a las variables de la sucesión
muestra , convergen de manera "casi segura" a la verdadera función de
distribución de la población , así :
Si denominamos DI a las máximas diferencias que pueden existir entre los valores que proporciona una función de distribución (muestra-sucesión) y otra (función de distribución de la población)
![]()
tendremos que se cumple que  luego
luego ![]()
5. Teoremas Centrales del Límite
La que podemos denominar familia de los teoremas límite tiene como punto de partida la siguiente situación :
Si estamos ante una sucesión de variables aleatorias {Xn} ![]()
y establecemos que ![]() se cumplirá que:
se cumplirá que:
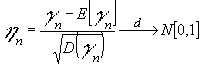 en donde
en donde ![]() es la desviación
típica y tiene carácter finito :
es la desviación
típica y tiene carácter finito :
de otra manera, podemos decir que la tipificada de la variable aleatoria suma de variables aleatorias de una sucesión converge en "distribución" a una normal 0,1.
Es el primer teorema central del límite , históricamente hablando(1756).
Dada una sucesión de variables aleatorias {Xn} ![]() de manera que cada una de ellas tenga una distribución
de manera que cada una de ellas tenga una distribución ![]() donde
p=q=0,5 (Moivre introdujo la restricción p=q=0,5 , que no es necesaria tras la
generalización del teorema por Laplace)
donde
p=q=0,5 (Moivre introdujo la restricción p=q=0,5 , que no es necesaria tras la
generalización del teorema por Laplace)
se establece que la nueva variable sucesión 
Lo demostraremos mediante la convergencia de la F.G.M.
Así la F.G.M de las variables de la sucesión (binomiales) Xn serán del tipo:
![]() en consecuencia
la F.G.M. de la sucesión
en consecuencia
la F.G.M. de la sucesión ![]() será :
será :

Pudiéndose probar que  que es la F.G.M. de la N[0,1]
que es la F.G.M. de la N[0,1]
Del teorema de Moivre-Laplace se deduce
fácilmente que una distribución binomial puede aproximarse a una distribución normal de
media n·p y desviación típica ![]() cuando n tienda a infinito
cuando n tienda a infinito
Se trata de la primera (1901) demostración rigurosa de un teorema central del límite ,aunque como dijimos antes la forma de Moivre es anterior es solo válida para el caso de distribuciones binomiales. Así
dada una sucesión de variables aleatorias {Xn}![]() independientes de manera que las variables tendrán de medias y varianzas :
independientes de manera que las variables tendrán de medias y varianzas : ![]() y
y ![]() tendremos que:
tendremos que:
la sucesión ![]() definida como :
definida como : 
converge en distribución a una N[0,1]
En cierto modo es un caso particular de la forma de Lyapounov dado que las premisas previas son más restrictivas ; así
dada una sucesión de variables aleatorias {Xn}![]() independientes y con la misma distribución , de manera que las variables tendrán la
misma media y varianza :
independientes y con la misma distribución , de manera que las variables tendrán la
misma media y varianza : ![]() y
y ![]() tendremos que:
tendremos que:
La
sucesión ![]() definida como
:
definida como
:
converge en distribución a una N[0,1]
de donde  : es decir ;
: es decir ;
que si sumamos un gran número de variables aleatorias
independientes e igualmente distribuidas , con la misma media y varianza ; esta suma se
distribuirá normalmente con media n veces la media común y , desviación
típica raíz cuadrada de n veces la desviación típica común.
Para demostrar este teorema vamos aprobar que la F.G.M . de ![]() tiende a la F.G.M. de una
distribución Normal reducida cuando n tiende a infinito ; esto es :
tiende a la F.G.M. de una
distribución Normal reducida cuando n tiende a infinito ; esto es :
 para ello consideramos las nuevas variables
tales que :
para ello consideramos las nuevas variables
tales que :
![]() para i = 1,2,3,......n .
de manera que :
para i = 1,2,3,......n .
de manera que :
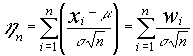 como todas las X son estocásticamente independientes y están idénticamente distribuidas
, las
como todas las X son estocásticamente independientes y están idénticamente distribuidas
, las ![]() también serán
independientes y en consecuencia tendrán la misma distribución ; así y en consecuencia
la F.G.M. de
también serán
independientes y en consecuencia tendrán la misma distribución ; así y en consecuencia
la F.G.M. de ![]() será:
será: por lo que debemos obtener primero :
por lo que debemos obtener primero :


desarrollando en serie tendremos:
 dado que :
dado que :
![]() y
y
![]() tendremos que
tendremos que

si
tomamos límites cuan n tiende a infinito la función ![]() es un infinitésimo de orden superior a
es un infinitésimo de orden superior a ![]() y por tanto :
y por tanto :

que es la expresión de la F.G.M. de la Normal (0;1).
Esta demostración es sólo valida para el caso en el que las F.G.M. existan ; si no fuera así utilizaríamos de manera análoga las funciones características.
Del propio teorema central del límite en forma Lindeberg-Lévy se infiere , lo que
podríamos denominar su versión en media ; así , dada una sucesión de variables
aleatorias {Xn}![]() independientes y con la misma distribución
de manera que las variables tendrán la misma media y varianza :
independientes y con la misma distribución
de manera que las variables tendrán la misma media y varianza : ![]() y
y ![]() y tenemos la sucesión :
y tenemos la sucesión :
 es decir, la media de la sucesión ; y dado que conocemos por
Lindeberg-Lévy que : La sucesión
es decir, la media de la sucesión ; y dado que conocemos por
Lindeberg-Lévy que : La sucesión ![]() definida como : converge en distribución a una N[0,1] luego para la
nueva sucesión
definida como : converge en distribución a una N[0,1] luego para la
nueva sucesión ![]() tendremos que:
tendremos que:
la sucesión ![]() definida como :
definida como : converge en distribución a
una N[0,1]
converge en distribución a
una N[0,1]
de donde  : es decir , que la media aritmética de un
gran número de variables aleatorias independientes e igualmente distribuidas , con la
misma media y varianza ; se distribuirá normalmente con media la media común y ,
desviación típica , la desviación típica común dividida por raíz de n.
: es decir , que la media aritmética de un
gran número de variables aleatorias independientes e igualmente distribuidas , con la
misma media y varianza ; se distribuirá normalmente con media la media común y ,
desviación típica , la desviación típica común dividida por raíz de n.
La gran importancia de esta convergencia y forma del teorema , radica en su aplicabilidad en la relación muestra-población , y así podemos establecer que : "sea cual fuere la distribución de la población, si extraemos una muestra aleatoria de suficiente tamaño, y de forma que las extracciones sean independientes entre sí; la media de esta muestra tiende a una normal, con media la media de la población, y desviación típica, la desviación típica de la población dividida por la raíz del tamaño muestral".
Realmente se trata de un caso particular de aplicación del T.C.L. forma Lindeberg-Lévy ; la particularidad reside en que las variables aleatorias que forman la sucesión son o se distribuyen según una Poisson de parámetro l . El hecho de que lo tratemos aquí radica en su utilidad y practicidad , y así:
Dada una sucesión de variables aleatorias {Xn} ![]()
![]() donde Xi ® Poisson(l ) por lo que la media común
es l y su varianza común , también
donde Xi ® Poisson(l ) por lo que la media común
es l y su varianza común , también
En aplicación del TCL tendremos que
La sucesión ![]() definida
como :
definida
como :
converge en distribución a una N[0,1]
Dado que la distribución de Poisson cumple el teorema de adición para el parámetro l , tendremos que:
 de donde conoceremos que
de donde conoceremos que ![]()
y la desviación típica será ![]()
por lo que 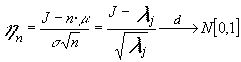
De donde se deduce que una distribución de Poisson cuando l tiende a infinito converge a una normal con media l y desviación típica raíz de l
Corrección por convergencia discreta-continua
Hemos comprobado cómo es posible que ciertas distribuciones discretas (binomial , Poisson, etc..) converjan a otra distribución , principalmente la normal ,que es de carácter continuo. El hecho de utilizar la distribución normal (función de distribución continua) para la consecución de probabilidades que parten de un escenario real discreto hace que ,en ocasiones , las probabilidades calculadas no se ajusten , o aproximen , correctamente a las que hubiésemos obtenido sin aplicar la convergencia. Es , por ello ,que es necesario realizar unas pequeñas correcciones que denominamos de convergencia discreta -continua. Ilustremos dichas correcciones con un ejemplo:
Supongamos que la variable aleatoria X sigue una Poisson de parámetro l =100 y pretendemos calcular la probabilidad de que X tome valores inferiores o iguales a 95 ; sería
![]() ¿
¿  siendo dicho resultado
realizado directamente el valor 0,33119174
siendo dicho resultado
realizado directamente el valor 0,33119174
dado que nos encontramos con una Poisson de l =100 podemos aplicar la convergencia Poisson-Normal y así
![]()
por lo que la probabilidad pedida, quedaría :
![]() cuyo valor es 0,309
cuyo valor es 0,309
se observa que ambos valores discrepan ; si bien , claro está , estamos utilizando una aproximación, las diferencias entre valores parecen excesivas y pueden mejorarse.
El error cometido parece estar en la diferencia de utilización discreta-continua. En la utilización de la distribución de Poisson estaba incluido el valor 95 , en el caso de la normal no se llegaba a dicho valor, precisamente por su carácter continuo.
Supongamos en una gráfico ambas actuaciones :
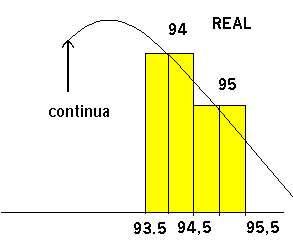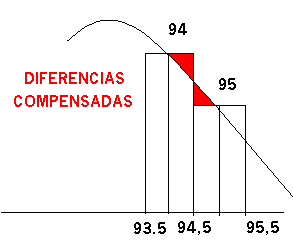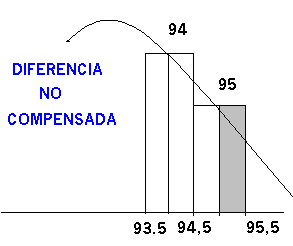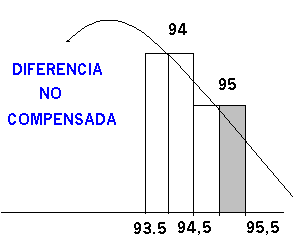
Queda , como se observa , una zona que no contempla la función continua por ello ,en este caso , es conveniente ampliar la zona para la que se va a calcular su superficie(probabilidad) tomando no 95 si no 95,5 , de esta manera quedaría incluida la probabilidad hasta el valor 95 inclusive , así:
![]() cuyo resultado es
0,326 , mucho más próximo al verdadero valor sin aplicar convergencia.
cuyo resultado es
0,326 , mucho más próximo al verdadero valor sin aplicar convergencia.
Utilización de convergencias en el caso de Binomial y Poisson
Para aclarar la utilización de las convergencias en los casos de distribuciones de Poisson y Binomial ; ya que conocemos el teorema de Moivre , la convergencia de la distribución de Poisson y la anteriormente conocida Binomial-Poisson , establecemos los siguientes criterios y posibilidades.