Options for Presentation of Multilingual Text:
Use of the Unicode Standard
by Janet C. Erickson
Prepared for John Price-Wilkin as a
Digital Information Associate Research Project
March 14, 1997
For further information or to give feedback please contact janete@umich.edu.
In the current model of electronic publishing, texts can be delivered
with a cross-application approach using the Standard Generalized Markup
Language (SGML).This same level of cross-platform and cross-application
delivery has not been achieved for all of the characters that these texts
include. An ideal solution to the problems in character representation
would be cross-platform, flexible, and durable. Many in the computing,
publishing, and library worlds have suggested that the Unicode standard
is the wave of the future. The following seeks to demonstrate the frailties
of other options that are considered for text presentation and the success
of Unicode and its sibling standards in addressing these weaknesses.
Introduction
Multilingualism has long been a concern in libraries. Most libraries collect
and catalog items that are not produced in the local language. Cataloging
records for these documents, either cards or OPAC entries, frequently contain
letters or characters that are not found on a standard typewriter or computer
keyboard. Librarians have applied workarounds or local solutions, though
each has its downside. In the past, extended character sets made available
through various means have been sufficient to deal with the problems of
multilingual and foreign text. However, these character set solutions are
often standardized only to a nation, an industry, a profession, or an even
smaller group. Competing standards mean that documents written using one
character set must be modified for use on systems that use another character
set or sets or they cannot be read. Service to a growing international
audience is imperative. Digital libraries are springing up and their communities
span the globe. The world needs to come to an agreement on how the information
that they provide can be understood unambiguously by computer systems of
their newfound audience.
The University of Michigan's Humanities Text Initiative currently delivers
texts with a cross-application approach using the Standard Generalized
Markup Language (SGML) but because of character set limitations cannot
yet provide the same level of cross-platform and cross-application delivery
for all of the characters that these texts include. An ideal solution to
the many problems with character representation would be cross-platform,
flexible, reusable, and durable. Many in the computing, publishing, and
library worlds have suggested that the Unicode standard is the wave of
the future, but does it meet these criteria?
The Unicode standard is intended to provide a 'unique, universal, and
uniform' encoding(1)
for each character in all living languages (plus a few dead ones). In this
report, I intend to investigate whether movement should be made toward
embracing the Unicode standard for presentation of materials on the World
Wide Web and other worldwide media, what other options are available, and
whether the Unicode standard is an effective means for digital libraries
and publishers to provide multilingual information.
Any attempt to provide multilingual information over the Web runs into
problems beyond the choice of character set. These include alphabetization
and sorting, searching, compression and compaction, and the particular
problems of presenting Arabic and the CJK languages (Chinese, Japanese,
and Korean). These will not be dealt with here in any depth. Each of these
is a problem unto itself and deserves an investigation of its own.
Cross-application compatibility is something for which many strive.
The Standard Generalized Markup Language (SGML) has promoted this through
an international standard (ISO 8879) of unambiguous document content and
structure coding. Each facet of a document can be identified and regularized
through user- or organization-defined rules. Each character that does not
come naturally to the local computer can be coded as an entity, a low-level
representation of that character the replacement of which is left to the
underlying system, as directed by the user. For each system (Macintosh,
IBM PC compatible, NeXT, UNIX, etc.), a different manner for replacing
these characters must be made; there is currently little agreement on where
these are placed in character sets, the source of this replacement. When
the different encodings used by other countries is thrown into the mix,
the size of the problem becomes overwhelming. An initial step in resolving
these differences is to agree on where each character should be placed
and to have a place for every character. While this may sound simple, efforts
in this direction have been hampered by the proliferation of the older
standards, which have age and localized use on their side. Each system
(by computer type and locale) has been developed for the needs of a nation,
a language group, or other particular group. Many share the same roots
with ASCII, but variations on its theme abound.
Localized variations complicate efforts to transport information among
these groups. One set of glyphs that has proven useful to a great many
people is from the Greek language. Greek citizens, classical scholars,
philosophers, lexicographers, mathematicians, and physicists are just a
few of the groups who find need of Greek characters. HTI uses Greek in
many ways and in many text collections. We cannot rely upon a common understanding
of the location or presence of the Greek characters in any one character
set on the computers of our user population. Each audience has found their
own way to present Greek. HTI has tried many things to solve the Greek
presentation issue -- a combination of methods has proved most useful,
but still not every user is served.
The solution to our specific problems will assist more than the HTI's
particular audience. It will allow more effective and more efficient communication
with the larger global community. Japan and China will seem closer as the
need to change operating systems to change language is eliminated. The
smooth transitions made possible by the World Wide Web will pale in comparison,
as uniform, barrier-free foreign language support becomes a part of every
computer system.
There are many ways to approach problems of computers and languages.
Solutions range in complexity from transliteration and GIFs that keep all
other aspects of the computer the same, to the Unicode standard, which
involves more widespread changes. An understanding of many of the solutions
requires more knowledge of how characters work on computers.
How Characters on Computers Work
Computers store information in groups of bits that are either 0 or 1, off
or on. Bits are usually stored in groups of eight to form a byte. Since
each bit has two possible values, the number of available combinations
of 1s and 0s is 28 (256) for 8-bit bytes. In 7-bit codes, the
most significant bit is always 0, with the remaining seven bits of the
byte combining 1s and 0s to make 27 or 128 combinations. Computers
have traditionally stored characters in single bytes. The 128 and 256 correspond
to the number of values that a computer can use for characters, based on
how much space is allocated for each.(2)
A character set, also known as a coded character set or code page, is "a
set of characters, each associated with a unique pattern of bits, for use
in representing character data on an electronic digital binary computer."(3)
The terminology used in reference to characters and character sets often
causes difficulties in communicating about them. First, standards organizations
use their own terms for many of the same ideas. Hence, we get 'character
set,' 'coded character set,' and 'code page' all meaning the same thing.
To minimize problems with variant language, a glossary has been included
as a supplement to this paper. The distinction between fonts and character
sets is addressed below in "Font-related solutions." Some of the more essential
terms, bits and bytes, are familiar to many computer users, thought the
accepted measure of eight bits in a byte is imprecise. A byte is formally
defined as "a bit pattern of fixed length."(4)
In the late 1950s, it was estimated that 75 percent of the data processed
by computers was numeric data, which could be represented with only four
bits. Seven bits was determined to be necessary for the remaining graphic
and control characters (letters/symbols and carriage return etc.) for communication
devices. Thus was born what would become ASCII, a 7-bit character set.(5)
In many applications, modern computers use 8-bit bytes. What most of use
on our computers these days is one of a variety of 8-bit extended character
sets based on ASCII.
Another area of confusion regards characters and glyphs. There is a
difference between a character and a glyph -- a character is the more abstract
ideal of a letter, symbol, or number, while glyphs are the representations
of these that appears on-screen and on the printed page. An example of
the difference between these is the character 'a' which can appear as the
glyphs 'a' or .
While this distinction may not mean much in American English, the Arabic
language, for example, uses different glyphs of the same character when
it appears in different parts of a word.(6)
.
While this distinction may not mean much in American English, the Arabic
language, for example, uses different glyphs of the same character when
it appears in different parts of a word.(6)
A Short History of Character Sets
The ASCII (American Standard Code for Information Interchange) character
set is a 7-bit scheme, with the first, all-zero code reserved as a null
code, leaving 127 values for characters. It is the character set that is
probably the most familiar to users as its characters appear on computer
keyboards. ASCII is based on the international standard ISO 646, first
published as ANSI X3.4 in 1968, which is also the basis for similar character
sets in other countries. In 1991, the International Organization for Standardization
(ISO) published a character set that has all of the same graphic characters
as US-ASCII, calling it ISO 646-IRV:1991 (International Reference Version).(7)
IBM created the Extended Binary Coded Decimal Interchange Code (more
commonly known as EBCDIC), an 8-bit character set, in the 1960s. This is
an industry standard, rather than a national or international one.(8)
IBM is said to have an internal register of more than a thousand versions
of EBCDIC(9)
as it has been modified to fit the particular needs of the user population.
Use of EBCDIC has declined since its heyday in the 1960s, though mainframe
computers using this character set continue to be serve important functions
in organizations.
The needs of the world have gone beyond the capabilities of the basic
ASCII and EBCDIC character sets. Other character sets will be introduced
below, as that additional layer of complexity is identified. The first
two possible solutions to the problem of multilingual computing, transliteration
and character images, do not require more than the 128 characters of ASCII.
Transliteration
Transliteration is the spelling or representing of characters and words
in one alphabet by using another alphabet. Phonological transliteration
is a common solution for foreign titles and author fields in library catalog
records. This type of transliteration needs to result in words and characters
that are readable. Because of this, simply assigning ASCII characters to
them in some pattern is insufficient, even if that pattern is regular and
otherwise informative. For example, the Chinese characters for the numbers
one, two, and three can be transliterated as YI_1_4E00, ER_4_4E8C, and
SAN_1_4E09, with the parts corresponding to syllable, tone, and Unicode
code value.(10)
For systems that cannot present the necessary glyphs for nonlocal languages,
transliteration is the only way for such information to be presented. For
many languages, the transfer from the original alphabet to another is unambiguous.
Fidelity is not ensured, however, and native speakers of the language are
not properly served by these romanized words.
For non-alphabetic languages, such as Chinese, there are many more ideographic
characters than can be unambiguously represented with the ASCII character
set. Much ambiguity is introduced through transliteration of these languages.
Subtle distinctions in Chinese script are lost in romanization in regard
to its many homophones. In addition, not all countries or groups follow
the same transliteration scheme. Some schemes have proven to be difficult
or impossible to transliterate back to the original language or are unintelligible
in their romanized form, especially to a native speaker. In a library context,
many online catalogs ignore diacritical distinctions as unimportant. Thus,
a search on one transliterated term that varies from another only in its
diacritics would produce many false drops. In all, transliteration of both
alphabetic and ideographic languages is not a sufficient solution to the
world's communication blockage.
Character Images
A second solution involves the use of GIF, PNG, or other images to display
the characters that are not available in the local character set. This
has worked well for presentation of the relatively small portions of Greek
in the Humanities Text Initiative's version of the
English Poetry Database
(Chadwyck-Healey,
Ltd.) where the user is not likely to search for that particular piece
of text. The HTML code is automatically generated from the original SGML,
with a mapping file taking care of what image to show for each desired
character. The sections of Greek in the EPD are typically isolated
lines of poetry, so that positioning of these images within the line of
English text and matching the font are unnecessary. As can be seen in other
attempted applications of this solution, the placement of a single Middle
English character, yogh, within the lines of text, sizing and spacing of
images is of utmost importance for the basic aesthetics of the text. The
current instantiations of Web and SGML browsers are unable to position
the images within lines of text to the degree necessary for invisible incorporation
of character images.
On first glance, images seem the ideal -- most if not all browsers understand
their content and they are fairly simple to produce. However, these images
are not searchable, and what is seen on the screen is what is copied to
a local drive in saving the file. A person saving an image-filled page
receives only a reference to the image, not the image itself. Other options
would need to be provided for saving the file in a format that would include
these characters as something comprehensible to the user's local system.
This leads us back to the question of what format and encoding this saved
file should have. Therefore, while the problems of display may be solved
thus, images in and of themselves do not provide a satisfactory resolution.
Beyond 128 Characters
It may be evident that the 7-bit ASCII standard severely limits the repertoire
of characters available for library bibliographic needs and other multilingual
applications. Three methods have often been used to gain additional characters:
substitution, 8-bit character sets, and escape sequences. Substitution
is the replacement of the 12 allowed characters in ISO 646 IRV:1991 with
locally applicable characters.(11)
We have already seen an 8-bit character set in EBCDIC. ASCII has been modified
to utilize that eighth bit and called extended ASCII by programmers
to distinguish it from the 7-bit form. ISO 646's 7-bit coding was extended
in this manner in the ISO/IEC 8859 standard, the first portion of which
is called Latin-1. Latin-1 served as the basis for the character set used
in Microsoft Windows.(12)
Figure 1, below, shows some of the many versions of extended ASCII for
use in Windows.
Figure 1
Windows 8-bit Character Sets(13)
Even the 256 characters available to an 8-bit character set are insufficient
for some uses. Additional character sets are available through shifting
and escape codes. An escape code (usually ASCII hexadecimal 1B) announces
that another character set, identified in the next bytes, will be used
from this point until an end code is found. ISO 2022 defines the use of
these escape codes; the European Computer Manufacturers' Association (ECMA)
maintains a registry of the character sets accessible in this manner.
The ISO creates international standards, ASCII is a national standard,
and EBCDIC is an industry standard. The library world has utilized another
type of standard: a professional standard. Professional standards are developed
by and for specific groups, such as the Library of Congress and RLIN, rather
than for national or international standardization purposes.(14)
The USMARC character set (formerly the ALA character set) was developed
by the Library of Congress, first published in 1969, and adopted as a U.S.
standard in 1985 (ANSI Z39.47-1985). USMARC is an 8-bit character set,
though it is also usable as a 7-bit set. It is a variable-byte character
set, meaning that non-spacing diacritics such as acute and grave that go
over other letters are transmitted as an additional byte before the byte
containing the character they modify. Due to the complex character needs
in the bibliographic environment, more than one diacritic can be combined
with a letter in USMARC. The USMARC character set was adopted by many countries
and library systems and modified for their uses, leading to UKMARC (United
Kingdom), DANMARC (Denmark), NORMARC (Norway), CANMARC (Canada), IBERMARC
(Spain), ANNAMARC (Italy), MARCAL (Latin America), AUSMARC (Australia),
JAPAN MARC (Japan), SAMARC (South Africa), SWEMARC (Sweden), and INTERMARC
(France and other European countries).(15)
MARBI or Machine-Readable Bibliographic Information oversees the USMARC
character set and other standards for libraries. It is an interdivisional
committee with representatives from LITA, RASD, and ALCST.(16)
An international effort at providing character sets that are useful
for multilingual needs resulted in the ISO 8859 series. These nine character
sets, 8859-1 to 8859-10 (8859-4 was withdrawn for revision),(17)
cover Western European, Central and Eastern European, Arabic, and Greek
languages. ISO 8859-1, the extension to ISO 646 more commonly known as
Latin-1, is sufficient to deal with Western European languages and is the
current official limit on the characters available to the Hypertext Markup
Language (HTML).
Double-byte character sets, or DBCS, encode certain characters using
a single octet and some using two octets. A major problem with this was
that each character has to be tested to see if it is 8 or 16 bits long.
Since the encoding string is interpreted in 8-bit chunks, no single octet
may have the same pattern as a control character (escape, nul, etc.), even
if another interpretion is clearly indicated by the previous octet. This
means that DBCS' can be transmitted with few mis-interpretations. Character
sets for Far Eastern languages have typically used DBCS to accommodate
their larger character repertoire. In its canonical form, the Unicode standard
utilizes 16 bits; unlike DBCS, it includes no 8-bit characters. ISO 10646,
in its canonical form called UCS-4, takes up 32 bits for each character.
These character sets will be discussed in depth below.
Font-Related Solutions: fonts and character sets
Before moving on to font-related solutions, a distinction needs to be drawn
between fonts and character sets. Fonts and character sets are not the
same thing. Fonts contain glyphs, not characters (see above and glossary).
The code positions of the glyphs are not important, as are the positions
of characters in a character set. A Times font may have the same general
style whether it's on a Macintosh or IBM-compatible computer, but the code
positions of the underlying characters on these systems are significantly
different. This difference is invisible for the first 128 characters, as
both the Macintosh and Windows character sets incorporate the ASCII character
set.
Of the 128 remaining positions in an 8-bit character set, only 11 are
in the same position in basic Macintosh and Windows fonts.(18)
When a transformation format such as Microsoft's Rich Text Format is selected
in saving a word processed document, many of the character set differences
are dealt with by the underlying system. This is not currently true in
the Internet environment. HTML-encoded documents may be created on any
computer system and read by any other. It is in this cross-platform environment
that differences between the basic character sets of computers show through.
The following table shows the areas of commonality between the Windows
and Macintosh character sets and selected positions where they differ.
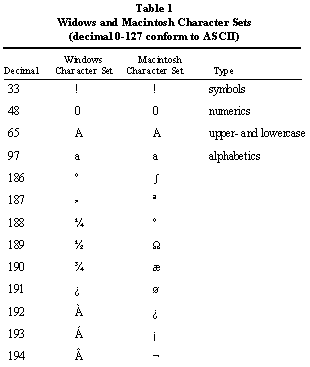
Many companies produce fonts for Windows and for Macintosh with nonroman
characters placed in the positions usually reserved for roman characters.
In these fonts, what appears when you type an 'a' might be a Greek alpha
or Cyrillic R. This circumvents the need to use escape codes to switch
character set encodings for nonroman texts. With these fonts in hand, it
is a simple task to write a multilingual word-processed document -- simply
change the local font when you want other glyphs. The initial problem with
this is that you cannot use it on another computer of the same type unless
it has the same nonroman fonts installed and available.
Unfortunately, not all fonts follow the same character set; the character
you intend to include may appear in a different position in another same-language
font so that an incorrect glyph would be displayed if you substituted fonts.
For example, scholars use many varieties of Greek fonts, such as SGreek
and Attika. Attika's encoding is the same in both its Macintosh and Windows
versions (character at decimal position 145 produces the same glyph on
each system). While this is a step in the right direction, this cross-platform
uniformity is the exception rather than the rule. This cross-platform ability
also requires the procurement of a particular commercial add-on. While
the price of an add-on may be insignificant compared to the benefits it
brings, those without access to the product will not be served. For this
reason, a standard, non-proprietary solution is preferable.
As mentioned above, cross-platform character set incompatibilities show
up when using Netscape or other Web browser. In general, browsers allow
the use of two fonts in display of an HTML document: a proportional font
for general text and a fixed font for editable fields and preformatted
paragraphs. One or both of these can be changed to a nonroman font, giving
access to two fonts in a document. Again, a font based on the same character
set needs to be used on each end; otherwise, the correct language may show
up but with the wrong glyph. This is due to the fact that most HTML content
does not identify the encoding used in creating the document, nor do most
HTTP servers transmit this information when it is available. As a result,
browsers need to either guess at the encoding used or use a default value.
Even if the encoding is specified and transmitted, browsers are limited
in what they can do to present the document correctly. Encoding translation
tables and suitable font resources are both necessary for proper interpretation
and display of documents.(19)
There is also the limitation to two fonts, making presentation of material
in multiple languages difficult through this means. Microsoft's browser,
Internet Explorer, and Netscape Navigator 3.0 have addressed the fonts
issue by adding the face attribute to the font tag in HTML (<font face=Attika>).
There is still the expectation that the end user will have the fonts specified
in this tag present on their computer.
Another reason that switching fonts to get new characters is an inadequate
way to bring multilingual capabilities to life is that it solves only the
display portion of the problem. When the text is viewed in another font,
it appears as gibberish. For example, the following three sentences were
typed using the same keystrokes, but the results are vary significantly:

There is no distinction made between a glyph in position 156 in a Greek
font and a glyph in the same position in a Cyrillic font. Changing the
fonts used in a document allows display of an almost unlimited array of
glyphs, but these glyphs cannot be searched, result in nonsense if switched
to another font, are highly system-dependent, and are not present on every
computer.
Character Set Switching
Unambiguous communication of text is much simpler when some recognized
standard is followed within a document. Mapping tables can be used to convert
from one character set to another, assuming no changes have been made to
the source character set locally. This is especially useful in an international
environment, such as the Web, where no assumption can be made that others
are using the same character set that you are.
There are many ways to switch character sets. Users can utilize the
local character set and have all incoming documents changed to it by a
mediating server. This limits the characters that can be understood locally
to those available in the local character set. Another option is to have
all computers understand all local character sets. This requires an enormous
amount of upkeep, as character set standards are added, changed, or deleted.
There are many character sets that include characters for presentation
of the Greek language. ISO 8859-7 covers modern Greek and English. 8859-7
includes all of the basic Greek characters, alpha through omega, plus the
diacritics diereses, tonos, and a combined diereses/tonos character. This
character set was developed by ISO/TC97/SC2, Character Sets and Information
Coding, and adopted by ELOT as a Greek national standard, ELOT 928. Classical
or polytonic Greek cannot be produced with only these diacritics. In contrast,
ISO 5428 is designed for bibliographic use. It does not match the Greek
national standard, but it does include the diacritics necessary for Classical
Greek: acute, grave, rough, smooth, circumflex, and diereses. The 1980
version of ISO 5428 also differs from the 1976 version that was used as
the basis for INTERMARC's Greek portions.(20)
There has been a proliferation of code pages, so a document may indicate
a switch to a code page that is unavailable to or not present on one's
computer. While the ECMA registers character sets that can be accessed
through methods defined in ISO 2022, this process of registration slows
the implementation of them in various contexts. For example, the Research
Libraries Group implemented Arabic, Hebrew, and East Asian character sets
that are considered privately defined and not registered with ECMA so that
the RLG could use these sets.(21)
Standardization and registration of these sets is desirable for the additional
certainty of support that such registry implies. From here, we can imagine
moving from standard, registered code pages to a single character set that
includes all of the characters that had been contained in each of the separate
character sets.
Unicode
The best of the previous character sets solutions presented many obstacles
to library and publishing efforts toward multilingual computing. Software
engineers make up another affected group. International software development
was impaired by many things, including stateful encoding, variable-length
encoding, and overloaded font systems.(22)
Stateful encoding is a problem with shifting character sets, as the character
represented by a particular value depends on knowing another value that
was indicated earlier in the text stream. This is much like DBCSs (double
byte character sets), which contain characters represented by either one
or two bytes so each character has to be examined to determine where it
ends. Another problem is that character sets have tended to include glyph
variants, such as ligatures, that are more presentation forms than different
characters. This means that fonts are asked to do more work than they are
able to do, keeping track of multiple versions of a character to use in
different contexts. In addition, specific language fonts have been used
to enable the display of more characters than are available through a single
character set.
In response to these problems, Joseph Becker of Xerox PARC, along with
Lee Collins and Mark Davis of Apple Computer, began work on a new character
encoding. Becker named it "Unicode" for its aim to be three things: universal,
covering all modern written languages; unique, with no duplication of characters
even if they appear in more than one language; and uniform, with each character
being the same length in bits. The Unicode Consortium was incorporated
in 1991 as Unicode, Inc., with members Research Libraries Group, Metaphor
Computer Systems, Microsoft, IBM, Sun Microsystems, DEC, Adobe, Claris,
NeXT, Pacific Rim Connections, Aldus, Go Corp., Lotus, WordPerfect, and
Novell. Unicode is defined as "a world-wide character encoding standard
based on a 16-bit unit of encoding developed by Unicode, Inc."(23)
Unicode did not evolve on its own. In 1983, the ISO began work on the
ISO 10646 character standard, or Universal Multiple-Octet Coded Character
Set (UCS) 4 (for the four octets that make up each character's value).
ISO 10646, so named to remind us of ASCII's ISO 646, was initially designed
with 16-bit characters. The need to retain control codes from other character
sets and opposition from Japan and Korea to unification of the Chinese/Japanese/Korean
character set meant that 32 bits were needed to hold everything. The standard
was criticized for its size, though many schemes of sending only the pertinent
bits were suggested to make it workable.(24)
The first edition of the Unicode standard was near completion in 1991
when, at the urging of many in the computer industry, developers of Unicode
and ISO 10646 met to join their efforts. Their combined standard was accepted
as an international character code standard in spring 1992.(25)Unicode,
Inc. published the first volume of the Unicode Standard Version 1.0 in
October 1991, and the second volume in June 1992.(26)
Unicode is now a 16-bit form of the larger 10646 32-bit standard. The 32-bit
pattern is interpreted as four octets: the group octet, plane octet, row
octet, and cell octet. The combination of these indicates a unique character.(27)
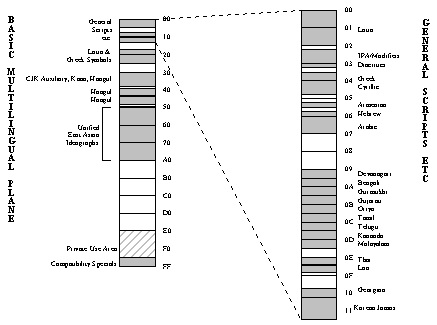
Unicode occupies the Basic Multilingual Plane of 10646, as shown in Figure
2, below.(28)
Figure 2
Map of the Basic Multilingual Plane
The Unicode standard includes tables of cell octet values and the characters
represented by these values. An example chart is shown below in Figure
3.
Figure 3
Unicode Block Chart (0000 to 00FF)
This table shows how ASCII can be fit into ISO Latin-1 by adding an
initial zero. In the same way, Latin-1 with an initial octet of zeros fits
into Unicode and Unicode with two initial octets of zeros fits into 10646.
With the unification of Unicode and ISO 10646, the question arises of how
to transmit data in either format. Sending all four octets of UCS often
is not feasible and not all applications can utilize even the 16 bits of
Unicode. Several schemes have been developed for these situations: UTF-7,
UTF-8, and UTF-16, to accompany the canonical UCS-2 (Unicode) and UCS-4
(10646). The UTF in each of these stands for UCS Transformation Format,
followed by the number of bits of transparency required by the transmission
channel.(34)
UTF-7 is a mail-safe transformation format of Unicode.(35)
It allows transmission of Unicode text through mail and news systems in
which characters beyond 7-bit ASCII would be interpreted incorrectly. Characters
from 128 and above (decimal values) are accessed through shift sequences;
UTF-7 also contains provisions for systems using EBCDIC, which cannot handle
all of ASCII's characters.
The 8-bit UTF-8 supplanted the earlier UTF-1 (one octet), also called
File System Safe UTF.(36)Characters
in UTF-8 are represented by a series of 1, 2, 3, 4, 5, and 6 octets; the
number of octets needed for a character is indicated by the number of 1s
in the initial octet. UTF-8 can be converted to UCS-4 efficiently, but
cannot be directed transformed to UTF-16 (Extended Unicode, see below).
UTF-8 is designed so that null bytes and the ASCII slash (/) are protected
so that systems for which these characters have additional meaning will
not misinterpret their use.
UTF-16 has also been referred to as Extended UCS-2, an extension of
Unicode. It allows access to characters outside the Basic Multilingual
Plane (BMP) of UCS-4 (ISO 10646) in a UCS-2 encoded string.(37)
UTF-16 reserves 1024 codes from the BMP for the high-half zone code and
1024 from the BMP for the low-half zone code. When these codes are combined,
they add 917,504 code positions for new characters and 131,072 additional
spaces for private use. In this scheme, some characters are represented
by one 16-bit UCS-2 code value and some by two 16-bit UCS-2 code values,
making this in essence a variable length encoding much like the double-byte
character sets (DBCS) mentioned earlier. As in a DBCS, each character in
a string has to be examined to determine whether it will be followed by
the second half of the character or by a different character. This adds
overhead to processing of the character data. It also violates the design
goal of Unicode that Unicode will use only one 16-bit code for each character.
An alternative is the remapping of non-BMP ISO 10646 characters to the
private use area when a file using these characters is imported. This limits
the number of non-BMP characters to the size of the private use area (6,400
character spaces). As the non-BMP characters have yet to be assigned, it
is unknown if this is a serious hindrance to use of UCS-4.
These transformation formats are important for many reasons. They can
be used to send all of the characters of 10646 or Unicode in forms that
are not likely to be misinterpreted by historic systems. Byte-order problems,
the order in which the multiple octets of Unicode are sent, are avoided
in the UTF-8 and UTF-7.(38)
Most importantly, UTF-8 in particular is being adopted in the computing
community. UTF-8 can be used to represent Unicode and its superset ISO/IEC
10646. Because the characters of the BMP in 10646 are Unicode characters
with two all-zero octets added on the front, UTF-8 can be said to convert
cleanly to Unicode as well. Characters used in UTF-8 outside the BMP are
not available in canonical Unicode -- UTF-16 adds this capability. The
compatibility of UTF-8, which is used in Microsoft Office 97, and 16-bit
Unicode used in NT, provides access points between these operating systems.
Implementation of the Unicode Standard
Unicode/10646 and the UTFs have been hailed by many in the computing and
library communities as an ideal solution to the problems of multiplatform
internationalization. "Unicode is the worldwide character-encoding standard
destined to replace ASCII and the multitude of other single- and multibyte
character sets currently in existence."(39)
"Unicode makes so much sense, it seems inevitable."(40)
"Once multiscript universal systems are widely available....at long last,
cataloging rules and machine-readable cataloging will be in harmony."(41)
Despite its obvious benefits, implementation of Unicode has progressed
slowly. Most U.S. computer users do not stretch the capabilities of the
256-character Windows character set and have no apparent need for a larger
set.
For those PC users who do need multilingual capabilities, many software
companies have been forward-thinking in their use of Unicode. As early
as 1991, Microsoft, IBM, and Apple Computer indicated their intention to
incorporate Unicode into the latest release of their products.(42)Microsoft
is a good example, as use of its products is widespread. Windows NT 4.0
was built to use full 16-bit Unicode to store internal information and
process strings. Windows 95 has a more limited capability with Unicode.
It still uses the Windows 3.x code base and is tied to the local character
set, so that internal processing is done in the local character set. Applications
that run on Windows 95 can, however, utilize Unicode if the strings are
translated to the local character set before internal processing is done.
This adds overhead to programs that need the multilingual support.
On Windows NT, programs that utilize local character sets rather than
the characters in Unicode also need to be translated before processing,
though the structure of NT makes the overhead required to do this much
less than in Windows 95.(43)
The Office 97 version of Microsoft Word (Word 97) will allow files to be
saved as UTF-8 and in HTML format.(44)
Microsoft's FrontPage Web page editor/manager and Notepad utility allow
users to save files in UTF-8 format. UTF-8 is also available in Netscape
Navigator 3.0 under Windows 95 and NT 4.0.(45)
The Spyglass Mosaic browser supports UTF-8 on Windows 95, as do Alis Tango
and AccentSoft's Accent, both based on Spyglass technology.(46)
The Apple Macintosh OS does not currently use the Unicode standard in
basic operations. Such support has been planned since the announcement
of Unicode, but was not included in the subsequent OS update, System 7.
Copeland, soon to become System 8, should add full support for the Unicode
character set. Inclusion of multilingual sorting rules should also be part
of Copeland.(47)
In addition to operating systems, fonts and font systems are being developed
to complement Unicode. The Unicode standard defines only a character set
encoding; it does not address issues of sorting, glyph selection, and other
high-level text manipulations. These need to be taken care of by the applications
and systems built on top of it. On the Apple end, QuickDraw GX and its
associated Line Layout Manager currently provider users of MacOS 7.5 with
functionality that enhances fonts. These utilities provide automatic kerning
and on-the-fly ligature choices, linking characters into combined glyphs
where necessary. This glyph selection is important in languages such as
Arabic and Hebrew where the position of the character in a word often determines
its glyph shape. Worldscript, another Macintosh exclusive, allows text
to flow from right to left as in Arabic and Hebrew.(48)
Microsoft has answered Apple's glyph manipulation functionality with
TrueType Open. TrueType fonts used in the Windows and Windows NT environments
compatible and are based on what they call 8-bit ANSI. According to Microsoft,
most Windows TrueType fonts already use Unicode coding internally so they
are prepared for the change to Unicode. TrueType Open provides glyph substitution,
positioning, and script and language information. It has been available
only in the Middle East and Far East versions of Windows 95 with plans
in the works for extension to other versions.(49)
For all of these applications of the Unicode Standard, fonts must be
created that are compatible with the standard. Windows NT comes with a
font called Lucida Sans Unicode, which contains glyphs for 1,752 characters
in Unicode. CJK support is notably absent from this font, though it serves
other needs respectably. The NT 4.0 CD-ROM does include three additional
fonts for CJK that are installed in a separate step. Bitstream is planning
to provide a free Unicode-based font, Cyberbit, that includes characters
for use in several languages. Additional languages and typefaces will be
available for purchase from Bitstream. Fonts for use with Gamma UniType
are included in language volumes. If the text's needs extend beyond these
glyphs, fonts can be created with such programs as Macromedia Fontographer,
available in both Macintosh and PC versions. The latest version of Fontographer,
4.1, allows the creation of fonts with glyphs in their Unicode positions.
The Macintosh version has 2,147 prenumbered slots for such characters;
the Windows version has 1,267 spaces available.(50)
For those unwilling to wait for Microsoft and Apple to implement Unicode
fully, there are many other options. Two useful add-on products com from
Gamma Productions and the Institute of Systems Science at the National
University of Singapore.(51)
Gamma Productions' Gamma UniType integrates with programs running under
Microsoft Windows, allowing the user to select languages and appropriate
keyboard layouts for producing multi-language documents.(52)Multilingual
Application Support Service (MASS), from the Institute of Systems Science,
focuses its support on the CJK languages. The Institute offers their product
in many flavors of UNIX; a beta version for Microsoft Windows has been
available since Oct. 1995. WinMASS adds Chinese, Japanese, Korean, and
Tamil capabilities to most Windows applications. Other languages, such
as Arabic, Cyrillic, and Greek are planned for the final release version
and are already available in the Unix versions. The 16-, 8-, and 7-bit
forms of Unicode/10646 are supported in MASS products.(53)
Barriers to Adoption
Changing over to the Unicode/10646 standard will be no simple feat. Many
technical and political barriers, as well as simple bigotry, must be overcome
before it can take the place of ASCII as the lingua franca of computing.
After almost 30 years, the use of ASCII is firmly ingrained in our psyche
and in our computer programs. Computing systems in the West are designed
to use 7-bit and 8-bit character sets. These character sets have proven
quite useful to the groups and nations for which they were created. Software
has been hard-coded for use with smaller character sets. Not all computer
systems are able to use the larger character size of canonical Unicode
or 10646 and network transmission of 16- or 32-bit characters cannot be
done without changing to a transformation format. A choice also needs in
the form of 10646 to implement: UTF-8, UCS-2, or UCS-4. A font with the
full thirty-thousand characters of the BMP would be unmanageable. Smart
font system are still needed for glyph substitution and presentation forms
of Arabic and other context-sensitive languages.
Pre-Unicode data and data systems also put up barriers. Mapping of old
character set to the Unicode set allows the old information to be usable
in new environments. In some cases, should that data need to be returned
to its original form, the many-to-one problem appears. The USMARC character
sets contain more than one instantiation of what have been dubbed "ASCII
clones," digits and punctuation that appear separately in the Latin, Cyrillic,
Hebrew, and Arabic character sets. Each of these duplicate characters map
to a single location in Unicode. On the return trip, mapping back to the
original character set, the single Unicode character contains no additional
information about where it came from. There is no indication as to which
of the two or more possible spaces in the old character set it should go.(54)
A more salient difficulty relates to SGML document access. HTI texts
are queried through the OpenText search engine (OT5) formerly known as
Pat. OT5 understands only 7-bit characters, 8-bit characters, and EUC.
Although OT5 can search on 8-bit characters, there is no way to input them
unambiguously across platforms (see Table 1: Windows and Macintosh Character
Sets). Most search engines, OT5 included, are used in a crossplatform environment.
The lack of a standard interpretation of 8-bit characters is a significant
hindrance to the ability of search engines to retrieve documents and text.
Characters beyond the initial 128 are removed when searched, regardless
of the search engine.
SGML and Character Sets
While the document character set may need to be 7-bit, 8-bit, or EUC so
that OT5 can search the text, Unicode and its transformation formats can
be used for communicating the results of a OT5 query across the Internet.
The HTI is already using a similar dichotomy to encode and display Greek
in the Bryn Mawr Classical Reviews.(55)
The articles have been encoded in SGML using the Text Encoding Initiative
DTD (TEILite) and are searched using OT5. The results of searches can be
presented in SGML or HTML form. Using SGML, there are many options for
display of the Greek text. For example, stylesheets can describe the font
that has the needed glyphs; character entity references (é)
can be mapped or linked to GIFs or font glyphs.
For HTML display, users are given the choice of three mechanisms: beta
code, fonts, or GIF images of the Greek glyphs. The underlying character
set and text representation in beta code is invisible to users who select
either of the other options. The variety of presentation options the HTI
can offer is extended with Unicode/10646 and its transformation formats.
Many of the characters in HTI texts are ASCII, which fits neatly within
UTF-8 in particular (see above). Latin-1 is included via character entity
references, which are also mapped to other display formats when necessary.
Text sections in Greek are mapped from the original beta code to the display
formats described above. A similar strategy has been used by the Perseus
Project at Tufts University in offering display options to meet user needs.(56)
If the collections created and supported by the Humanities Text Initiative
were only for in-house use, the problems associated with character sets
and glyph representations would be nonexistent. HTI texts are often encoded
using the Text Encoding Initiative Document Type Definition (DTD), which
provides methods for utilizing characters in and outside of the local character
set. For needs within the local set, the applicable local character can
be inserted in the text directly. Characters not in this character set
should be presented as SGML entity references. Suggested names for these
entities have been published by the ISO and others, including the TEI.
For example, a small 'e' with acute accent may be referenced as é
with the semicolon optional in some circumstances. Entity sets must be
declared before characters in that set are used; the é is part of
the ISO Latin-1 set, which is declared as follows:
<!ENTITY %ISOLat1 PUBLIC "ISO 8879-1986//ENTITIES
Added Latin 1//EN">
%ISOLat1;
Individual characters with no standard entity name can be declared individually.
These characters can be associated with printer commands, which makes them
highly situation-specific. Character entity references are typically created
using ISO 646:IRV characters; ISO 646 is the simplest form of computer
characters and is not likely to be garbled in transit.
The transmission of HTI texts over the Internet complicates this process.
With local-use, the variables are all known: the local character set, other
available sets, fonts to represent the glyphs, etc. The HTI sends SGML
out over the net with character entity references mapped to specified fonts,
mostly relying on the commonality of Latin-1 fonts. When only a few non-Latin-1
characters are included, GIFs are sufficient and unambiguous for representation.
Providing multiple options for users to view Humanities Text Initiative
materials is the most effective way to ensure that everyone with access
to the materials will be able to use them. The flexibility of the systems
underlying the text collections and the SGML in which they are stored make
multiple display options feasible. Until the Unicode standard has complete
support within our user population, it cannot be the only option available
to them. This fits with the HTI's efforts to provide HTML versions of its
texts while keeping the dynamism and power of the underlying SGML intact.
Conclusion
I expect that the use of Unicode/10646 will increase dramatically in the
coming few years for many reasons. Use of the Internet has increased awareness
of the problems inherent in the use of multiple character set standards.
It has also increased the potential audience for HTI-created texts. The
standard was created by and has been embraced in the computer industry.
Many products have come on the market with support for some or all of the
standard; Microsoft's use of UTF-8 and Unicode, especially in Windows NT,
is a boost to the mainstreaming of such products. Fonts to allow display
of all characters in Unicode have been slow to arrive. The announced release
date for Bitstream's free Cyberbit font has been pushed back over the past
year, though Microsoft's Lucida Sans Unicode has sufficient glyphs for
most Western languages.
Support and use of the Unicode/10646 standard is the best way for the
Humanities Text Initiative to move toward its goals of a completely cross-platform,
flexible, and durable method for distributing multilingual text. The Standard
is cross-platform, with character codes that return the same glyph in compliant
fonts whether a Macintosh, PC, or UNIX computer is used for sending and
receiving the text. No one computer type or computer company has control
over the content of the character set. There is no need to change the positioning
of characters or the basic character repertoire, as the Unicode standard
is designed to incorporate all of these characters. If there is a need
to add characters that may not be of use to the wider Unicode audience,
the standard has the flexibility to allow the additions in the User Defined
Area. Durability of Unicode is provided through its transformation formats,
which offer safe transit of character data through many intermediate systems.
Of particular interest, Unicode/10646 works well for Greek. Characters
necessary for the Greek language have been agreed upon by scholars and
are included in Unicode, both the Ancient and monotonic versions of the
language are stable and generally unchanging, and there are few context-sensitive
glyphs like sigma to complicate the rendering process. More generally,
the solution to the problem of displaying Greek is the solution to problems
in displaying French, Cyrillic, and even Chinese.
The Unicode standard provides a much more satisfying and practical solution
than any other option available. GIF images, character set switching, transliteration,
and font changes are not able to support all of the characters needed in
the HTI in a way that is useful and comprehensive to the end user. The
implementation of the Unicode standard in Internet- and SGML-related computing
applications brings us closer to true document fidelity worldwide.
Postscript
Since this paper was researched and written, many changes have taken place
in both SGML and Unicode. One of the more salient changes has been the
introduction of XML, Extensible Markup Language. XML was designed by a
group of SGML experts to crate a simpler SGML for the Internet. The base
character set for XML is Unicode. More details on XML and its use of Unicode
can be found at http://www.textuality.com/sgml-erb/WD-xml.html. Other technologies
that deserve mention here include Bitstream's TrueDoc (http://www.bitstream.com/truedoc.htm)
and WebFonts (http://reality.sgi.com/grafica/webfonts/). Internationalization
is a dynamic area and changes take place too rapidly for any discussion
to be completely up-to-date. A periodic search of Internet sites and monitoring
of newsgroups and listservs is necessary for a more thorough understanding
of the current solutions and controversies. The of the Web sites linked
to in this paper have been verified as correct as of March 14, 1997. There
is, of course, no guarantee that these sites will remain at their current
locations.
Acknowledgements
I would like to thank my advisor John Price-Wilkin for guiding me through
the process of completing this project, offering critiques and ideas along
the way. I would also like to thank Glenn Adams for his clarifications
of the complex issues involved in character sets and Unicode.
Bibliography
Abramson, Dean. "Globalization of Windows." Byte vol. 19, no. 11.
Nov. 1994.
Adams, Glenn. "Character Set Terminology, SC2 vs. SC18 vs. Internet
Standards." April 7, 1995. Available at http://www.stonehand.com/glenn/csetterm1.txt.
Adams, Glenn. "Unicode and Internationalization Glossary." 1993. Available
at http://www.stonehand.com/unicode/glosscnt.html.
Aliprand, Joan. "Nonroman Scripts in the Bibliographic Environment."
Information
Technology and Libraries. vol. 11, no. 2, June 1992.
Aliprand, Joan. "Unicode and ISO/IEC 10646: An Overview" in
Automated
Systems for Access to Multilingual and Multiscript Library Materials.
IFLA Publications 70, 1994.
Andreessen, Marc. "The *World Wide* Web." Jan. 13, 1997. Available at
http://home.netscape.com/comprod/columns/techvision/international.html.
Bettels, Jürgen and F. Avery Bishop. "Unicode: A Universal Character
Code." Digital Technical Journal. Summer 1993. Available at http://www.digital.com/info/DTJB02/DTJB02SC.TXT.
Butcher, Roger "Multi-lingual OPAC developments in the British Library."
Program:
Automated Library and Information Systems vol. 27 no. 2 April 1993.
Cain, Jack. "Linguistic Diversity, Computers and Unicode." Paper presented
at "Networking the Pacific: An International Forum," in Victoria, BC, Canada,
May 5-6, 1995. Available at http://www.idrc.ca/library/document/netpac/abs21.html.
Carrasco Benitez, Manuel Tomas. "Web Internationalization." Available
at http://www.crpht.lu/~carrasco/winter/inter.html.
Carrasco Benitez, M.T. "On the Multilingual Normalization of the Web."
Presented at the Third International World-Wide Web Conference, Darmstadt,
Germany, April 10-14, 1995. Available at http://www.crpht.lu/~carrasco/winter/poster.html.
Clews, John. Language Automation Worldwide: The Development of Character
Set Standards. British Library R&D Reports; 5962. Harrogate, North
Yorkshire: SESAME Computer Projects, 1988.
Connolly, D. "Character Set Considered Harmful." MIT/WC3. HTML
Working Group Internet Draft. May 2, 1995. Available at
http://www.w3.org/pub/WWW/MarkUp/html-spec/charset-harmful.html.
"Countdown to System 8." MacUser. July 1995. Available from http://www.zdnet.com/macuser/mu_0795/feature/feature1.html.
Davis, Mark. "UCS Transformation Format 8 (UTF-8)." ISO/IEC JTC1/SC2/WG2
N 1036. August 1, 1994. Available at http://www.stonehand.com/unicode/standard/wg2n1036.html
and http://www.stonehand.com/unicode/standard/fss-utf.html.
Everson, Michael. "Today's BMP of ISO/IEC 10646-1." December 12, 1996.
Available at http://www.indigo.ie/egt/standards/iso10646/bmp-today-table.html.
Fayen, Emily Gallup. "The ALA Character Set and Other Solutions for
Processing the World's Information." Library Technology Reports.
vol. 25 no. 2, March-April 1989.
Gamma Productions. "Gamma Productions On-Line Catalog of Products and
Services." No date. Available at http://www.gammapro.com/products.html.
Gaylord, Harry E. "Character Entities and Public Entity Sets: Report
No. TEI TR1 W4." Jan. 9, 1992.
Gaylord, Harry E. "Character Representation." in Text Encoding Initiative:
Background and Context. edited by Nancy Ide and Jean Veronis. Durdrecht,
(The Netherlands: Kluwer Academic Publishers, 1995): 51-61. reprinted from
Computers
and the Humanities, vol. 29, pp. 51-73, 1993.
Gaylord, Harry. Email communication of Nov. 11, 1996.
Goldsmith, David, and Mark Davis. "UTF-7: A Mail-Safe Transformation
Format of Unicode." Network Working Group Internet Draft. March 11, 1997.
Available at ftp://ietf.org/internet-drafts/draft-goldsmith-utf7-02.txt.
Institute of Systems Science, National University of Singapore. "Multilingual
Application Support Service." Available at http://www.iss.nus.sg/RND/MLP/Projects/MASS/MASS.html.
ISO/IEC. "Amendment 1: UCS Transformation Format 16 (UTF-16)." ISO/IEC
JTC1/SC2/WG2 N 1035. August 1, 1996. Available at http://www.stonehand.com/unicode/standard/wg2n1035.html.
ISO/IEC, Subcommittee 2 and Subcommittee 18 of JTC 1, Information technology.
"Character/Glyph Model." Available at http://www.dk.net/JTC1/SC2/WG2/docs/N1411.doc.
Kano, Nadine. "TrueType Open Extends Support for International Typography."
Going
Global. Available from http://www.microsoft.com/globaldev/gbl-gen/codesets/truetype.htm.
Reproduced from the November/December 1995 issue of the Microsoft Developer
Network News.
Kano, Nadine. "Yes, Virginia, Windows 95 Does Do Unicode!"
Going
Global. July/Aug. 1995. Available from http://www.microsoft.com/globaldev/gbl-gen/codesets/unicw95c.htm.
Reproduced from the July/August 1995 issue of the Microsoft Developer
Network News.
Lazinger, Susan S. and Judith Levi. "Multiple Non-Roman Scripts in ALEPH
-- Israel's Research Library Network." Library Hi Tech. vol. 14
no. 1, 1996.
Library of Congress. "About MARBI." Jan. 1, 1996. Additional information
is available at http://lcweb.loc.gov/marc/marbi.html.
Library of Congress. "UCS and USMARC Mapping." MARBI Discussion Paper
No. 73. Dec. 6, 1993. Available via Gopher at gopher://marvel.loc.gov:70/00/.listarch/usmarc/dp73.doc.
Mackenzie, Charles. Coded Character Sets, History and Development.
Reading, Mass.: Addison-Wesley Publishing Co., 1980.
Macromedia. Fontographer User's Guide. Version 4.1. 1996.
MARBI Character Set Subcommittee. "USMARC Character Set Issues and Mapping
to Unicode/UCS." Proposal No. 96-10. Revised July 22, 1996. Available via
Gopher at gopher://marvel.loc.gov:70/00/.listarch/usmarc/96-10.doc.
McClure, Wanda L. and Stan A. Hannah. "Communicating Globally: The Advent
of Unicode." Computers in Libraries. vol. 15 no. 5, May 1995.
Microsoft. "Character Sets." Going Global. April 1996. Available
from http://www.microsoft.com/globaldev/gbl-gen/codesets/charsets.htm.
Microsoft. Microsoft Word User's Guide, Appendix A: Character
Sets.
Miller, L. Chris. "Transborder Tips and Traps." Byte. vol. 19
no. 6, pp. 93-102.
Nichol, Gavin T. "The Multilingual World Wide Web." June 1994. Available
at http://www.ebt.com/docs/multling.html.
Peruginelli, Susanna, Giovanni Bergamin, and Pino Ammendola. "Character
sets: towards a standard solution?" Program: Automated Library and Information
Systems. vol. 26 no. 3, July 1992.
Petzold, Charles. "Move Over, ASCII! Unicode Is Here." PC Magazine.
v. 12, no. 18, Oct. 26, 1993.
Pratley, Chris. Microsoft, Inc. Quoted in Misha Wolf's message to the
Unicode listserv dated Nov. 7, 1996.
Sheldon, Kenneth M. "ASCII Goes Global." Byte. vol. 16 no. 7,
July 1991, pp. 110-11.
Text Encoding Initiative Guidelines for Electronic Text Encoding
and Interchange.
Tresman, Ian. The Multilingual PC Directory. 2nd edition. Borehamwood,
Herts., UK: Knowledge Computing, 1994.
Unicode, Inc. "General Information." Available at http://www.stonehand.com/unicode/standard/general.html.
Unicode, Inc. "Unicode and Internationalization Glossary." Available
at http://www.stonehand.com/unicode/glosscnt.html.
Unicode, Inc. The Unicode Standard, Version 1.0, Volume 1. 1991;
The
Unicode Standard, Version 1.0, Volume 2. 1992.
Unicode, Inc. The Unicode Standard, Version 2.0, 1995.
Vacca, John. "Unicode Breaks the ASCII Barrier."
Datamation.
vol. 27, no. 15. Aug. 1, 1991.
Yergeau, F. et. al. "Internationalization of the Hypertext Markup Language."
IETF Draft html-i18n-05. Network Working Group, Internet Draft, Aug. 7,
1996. Available from http://www.alis.com:8085/ietf/html/draft-ietf-html-i18n-05.txt.
Notes
1. A character encoding is a description of the scheme
of assigning codes to individual characters. The term also applies in an
SGML context, but has a slightly different meaning there. [BACK]
2. Discussion derived from Emily Gallup Fayen, "The ALA Character Set
and Other Solutions for Processing the World's Information," Library
Technology Reports (March-April 1989): 257. [BACK]
3. Harry E. Gaylord, "Character Representation." in Text Encoding
Initiative: Background and Context, ed. Nancy Ide and Jean Veronis
(Durdrecht, The Netherlands: Kluwer Academic Publishers, 1995), 60, ftn
4. Gaylord indicates a preference for the term "coded character set" in
international and national standards. I will use "character set" in this
report for brevity. [BACK]
4. Charles Mackenzie, Coded Character Sets, History and Development.
(Reading, MA: Addison-Wesley Publishing Co., 1980), 497. [BACK]
5. Mackenzie, Coded Character Sets, 211-17. See below for more
on ASCII. [BACK]
6. More information on glyphs and characters can be found in the Character/Glyph
Model document at http://www.dk.net/JTC1/SC2/WG2/docs/N1411.doc.
[BACK]
7. Gaylord, "Character Representation," 53. [BACK]
8. For a history of character sets and the activities of standards bodies,
see Mackenzie, Coded Character Sets. [BACK]
9. John Clews, Language Automation Worldwide: The Development of
Character Set Standards. (Harrogate, North Yorkshire: SESAME Computer
Products, 1988), 36. Others have places this figure at around 450. [BACK]
10. Glenn Adams, Correspondence of Jan. 24, 1997. [BACK]
11. The replaceable characters are #, $, @, [, \, ], ^, `, {, |, },
and ~. Clews, Language Automation Worldwide, 24. The dollar sign
replaced the international currency symbol in ISO 646 IRV:1991. Gaylord,
"Character Representation," 53. [BACK]
12. Joan Aliprand, "Nonroman Scripts in the Bibliographic Environment,"
Information
Technology and Libraries 11, no. 2 (June 1992): 112.
[BACK]
13. Microsoft. "Character Sets." Going Global (April 1996). Available
from http://www.microsoft.com/globaldev/gbl-gen/codesets.htm.
[BACK]
14. There is an additional type of standard, the de facto standard.
De facto standards are utilized by a large user group but do not have any
formal means of standardization. Clews lists the USMARC character set as
de facto, though it has a formal standardization channel in the MARBI Working
Group of the American Library Association. [BACK]
15. Clews, Language Automation Worldwide, 31-35. This section
includes discussion of and charts for several of these national MARC character
sets. [BACK]
16. Library of Congress. "About MARBI" (Jan. 1, 1996). Additional information
is available at http://lcweb.loc.gov/marc/marbi.html.
[BACK]
17. Harry Gaylord, Email communication of Nov. 11,1996. The status of
ISO 8859-4 is confusing: parts of the standard have been incorporated in
8859-10 and an alternative 8859-13 has been proposed for the languages
that were covered by 8859-4. [BACK]
18. For complete tables of each character set, see Microsoft Word
User's Guide, Appendix A: Character Sets, 785-94. [BACK]
19. Adams, Correspondence of Jan. 24, 1997. [BACK]
20. Clews, Language Automation Worldwide, 88-91. [BACK]
21. Aliprand, "Nonroman Scripts in the Bibliographic Environment," 110.
[BACK]
22. Jürgen Bettels and F. Avery Bishop, "Unicode: A Universal Character
Code," Digital Technical Journal (Summer 1993). Available at http://www.digital.com/info/DTJB02/DTJB02SC.TXT.
[BACK]
23. Unicode, Inc. "Unicode and Internationalization Glossary." Available
at http://www.stonehand.com/unicode/glosscnt.html.
[BACK]
24. Kenneth M. Sheldon, "ASCII Goes Global,"
Byte 6 no. 7 (July
1991): 110-11. [BACK]
25. Information Technology -- Universal Multiple-Octet Coded Character
Set (UCS), ISO/IEC 10646. [BACK]
26. The Unicode Standard, Version 1.0, Volume 1. 1991; The
Unicode Standard, Version 1.0, Volume 2. 1992. [BACK]
27. Details of these octets are not presented here; Unicode's group
and plane octets both have the value of 00. See Joan Aliprand's "Unicode
and ISO/IEC 10646: An Overview" in
Automated Systems for Access to Multilingual
and Multiscript Library Materials. IFLA Publications 70, 1994. pp.
87-102. [BACK]
28. Based on a graphic in Joan Aliprand's article "Unicode and ISO/IEC
10646: An Overview" in Automated Systems for Access to Multilingual
and Multiscript Library Materials. IFLA Publications 70, 1994. This
is the BMP as it was in Unicode 1.0, not in version 2.0, and some changes
have been made in the allocation of space. Michael Everson has created
a more current version of the BMP, "Today's BMP of ISO/IEC 10646-1," available
at http://www.indigo.ie/egt/standards/iso10646/bmp-today-table.html.
[BACK]
29. Unicode, Inc. "General Information." Available at http://www.stonehand.com/unicode/standard/general.html.
In Unicode 2.0, a total of 47,399 of the 65,536 codes have been assigned.
Of these, 38,885 are graphic, formatting, or special character, 64 are
controls, 2 are non-use specials, 6400 are private use, and 2048 are for
use with UTF-16. An additional 9410 characters have been approved and are
in the balloting stage. (Adams, Correspondence of Jan. 24, 1997.) [BACK]
30. The Unicode Standard, Version 1.0, Volume 1, 4. [BACK]
31. ISO 6937 was designed for text communication of current European
languages. Clews, Language Automation Worldwide, 52-5. [BACK]
32. MARBI Character Set Subcommittee, "USMARC Character Set Issues and
Mapping to Unicode/UCS," Proposal No. 96-10, revised July 22, 1996. Available
via Gopher at gopher://marvel.loc.gov:70/00/.listarch/usmarc/96-10.doc.
See also "UCS and USMARC Mapping," Discussion Paper No. 73, Dec. 6, 1993.
Available via Gopher at gopher://marvel.loc.gov:70/00/.listarch/usmarc/dp73.doc.
[BACK]
33. The Unicode Standard, Version 1.0, Volume 2, 2. [BACK]
34. Adams, Correspondence of Jan. 24, 1997. [BACK]
35. David Goldsmith and Mark Davis, "UTF-7: A Mail-Safe Transformation
Format of Unicode," Network Working Group Internet Draft (October 14, 1996).
Available at ftp://ietf.org/internet-drafts/draft-goldsmith-utf7-02.txt.
[BACK]
36. Mark Davis, "UCS Transformation Format 8 (UTF-8)," ISO/IEC JTC1/SC2/WG2
N 1036 (August 1, 1994). Available at
http://www.stonehand.com/unicode/standard/wg2n1036.html
and http://www.stonehand.com/unicode/standard/fss-utf.html.
[BACK]
37. ISO/IEC, "Amendment 1: UCS Transformation Format 16 (UTF-16)," ISO/IEC
JTC1/SC2/WG2 N 1035 (August 1, 1996). Available at http://www.stonehand.com/unicode/standard/wg2n1035.html.
[BACK]
38. F. Yergeau et. al., "Internationalization of the Hypertext Markup
Language," IETF Draft html-i18n-05. Available from http://www.alis.com:8085/ietf/html/draft-ietf-html-i18n-05.txt,
18. [BACK]
39. Dean Abramson, "Globalization of Windows,"
Byte 19, no. 11
(Nov. 1994): 178. [BACK]
40. Charles Petzold, "Move Over, ASCII! Unicode Is Here," PC Magazine
12, no. 18 (Oct. 26, 1993): 374. [BACK]
41. Aliprand, "Nonroman Scripts in the Bibliographic Environment," 117.
[BACK]
42. John Vacca, "Unicode Breaks the ASCII Barrier," Datamation
27, no. 15 (Aug. 1, 1991): 56. [BACK]
43. Nadine Kano, "Yes, Virginia, Windows 95 Does Do Unicode!" Going
Global (July/Aug. 1995). Available from http://www.microsoft.com/globaldev/gbl-gen/codesets/unicw95c.htm.
[BACK]
44. Chris Pratley, Microsoft, Inc. Quoted in Misha Wolf's message to
the Unicode listserv dated Nov. 7, 1996. [BACK]
45. The registry needs to modified for Navigator to be able to use UTF-8.
This encoding option is greyed out otherwise. Instructions for changing
the registry are included as Appendix A. For Netscape's latest statement
on internationalization, see Marc Andreessen's piece at http://home.netscape.com/comprod/columns/techvision/international.html.
[BACK]
46. Adams, Correspondence of Jan. 24, 1997. Spyglass Mosaic - http://www.spyglass.com/products/smosaic/;
Alis Tango - http://www.alis.com/tango/tango.en.html;
AccentSoft Accent - http://www.accentsoft.com/press/homepage.htm.
[BACK]
47. "Countdown to System 8," MacUser (July 1995). Available from
http://www.zdnet.com/macuser/mu_0795/feature/feature1.html.
[BACK]
48. Ibid. [BACK]
49. Nadine Kano, "TrueType Open Extends Support for International Typography,"
Going
Global. Available from
http://www.microsoft.com/globaldev/gbl-gen/codesets/truetype.htm.
[BACK]
50. Macromedia. Fontographer User's Guide. Version 4.1 (1996):
198. [BACK]
51. A listing of additional products that support the Unicode Standard
is available at http://www.stonehand.com/unicode/products.html.
[BACK]
52. Gamma Productions. "Gamma Productions On-Line Catalog of Products
and Services." No date. Available at http://www.gammapro.com/products.html.
[BACK]
53. Institute of Systems Science, National University of Singapore,
"Multilingual Application Support Service." Available at http://www.iss.nus.sg/RND/MLP/Projects/MASS/MASS.html.
[BACK]
54. MARBI Character Set Subcommittee, "USMARC Character Set Issues and
Mapping to Unicode/UCS." Proposal No. 96-10, revised July 22, 1996. Available
via Gopher at gopher://marvel.loc.gov:70/00/.listarch/usmarc/96-10.doc.
[BACK]
55. HTI's online version of Bryn Mawr Classical Reviews is not
yet available to the public. [BACK]
56. The Perseus Project can be found at http://medusa.perseus.tufts.edu/index.html.
[BACK]
 Página creada y actualizada
por grupo "mmm".
Para cualquier
cambio, sugerencia,etc. contactar con: fores@uv.es
©
a.r.e.a./Dr.Vicente Forés López
Universitat de València Press
Creada: 15/09/2000
Última Actualización: 18/06/2001
Página creada y actualizada
por grupo "mmm".
Para cualquier
cambio, sugerencia,etc. contactar con: fores@uv.es
©
a.r.e.a./Dr.Vicente Forés López
Universitat de València Press
Creada: 15/09/2000
Última Actualización: 18/06/2001