Datos sobre la infraestructura de transporte público de Londres
Input
Se ha trabajado con un conjunto de datos de transporte público de Londres procedente de Transport for London (TfL) en formato GTFS (General Transit Feed Specification). Este tipo de feed contiene información estructurada sobre paradas, conexiones internas y metadatos del servicio, y resulta especialmente útil para análisis espaciales y de accesibilidad.
| Archivo | Descripción | Uso en el análisis |
|---|---|---|
stops.txt |
Paradas, estaciones, accesos y plataformas | Base principal de las entidades espaciales |
pathways.txt |
Conexiones peatonales entre elementos | Enriquecimiento de accesibilidad y conectividad |
levels.txt |
Niveles verticales de estaciones | Referencia de estructura interna |
feed_info.txt |
Metadatos del feed | Contexto temporal y técnico |
La fuente oficial del feed es Transport for London Open Data (https://tfl.gov.uk/info-for/open-data-users/our-open-data). Este dataset es adecuado para estudiar accesibilidad, conectividad y estructura interna de estaciones, pero requiere limpieza y enriquecimiento para su explotación analítica.
Descripción
El objetivo de este trabajo es depurar y enriquecer el feed GTFS para generar un dataset más útil para análisis geoespaciales y de accesibilidad. Para ello, se parte de las paradas de TfL y se incorporan variables derivadas a partir de las conexiones internas entre elementos de una estación.
En concreto, se pretende:
Normalizar el conjunto de paradas y conservar únicamente los registros útiles para análisis espacial.
Transformar la geometría a un sistema proyectado para poder hacer cálculos en metros.
Resumir la conectividad interna a partir de pathways.txt.
Construir indicadores simples de complejidad y accesibilidad de estación.
Exportar el resultado en varios formatos reutilizables para análisis y visualización.
Tratamiento
# Cargar archivos GTFS
stops <- read_csv("../data/2526020003/stops.txt", show_col_types = FALSE)
pathways <- read_csv("../data/2526020003/pathways.txt", show_col_types = FALSE)
levels <- read_csv("../data/2526020003/levels.txt", show_col_types = FALSE)
feed_info <- read_csv("../data/2526020003/feed_info.txt", show_col_types = FALSE)En primer lugar, se normalizan las coordenadas geográficas convirtiéndolas a formato numérico. Este paso es esencial para evitar errores en etapas posteriores de análisis espacial. Además, se filtran únicamente aquellos registros correspondientes a tipos de localización relevantes (paradas, estaciones, accesos y nodos), descartando otros elementos que no aportan valor al análisis.
stops_clean <- stops %>%
mutate(
stop_lat = as.numeric(stop_lat),
stop_lon = as.numeric(stop_lon)
) %>%
filter(location_type %in% c(0, 1, 2, 3))En primer lugar, se normalizan las coordenadas geográficas convirtiéndolas a formato numérico. Este paso es esencial para evitar errores en etapas posteriores de análisis espacial. Además, se filtran únicamente aquellos registros correspondientes a tipos de localización relevantes (paradas, estaciones, accesos y nodos), descartando otros elementos que no aportan valor al análisis.
A continuación, se incorpora información adicional sobre la conectividad interna de las estaciones a partir del archivo pathways.txt. Este fichero describe las conexiones peatonales entre distintos elementos del sistema (como accesos, plataformas o niveles), lo que permite enriquecer el dataset original con variables relacionadas con la accesibilidad y la complejidad estructural de las estaciones.
# Agregamos información de conectividad desde pathways
pathways_summary <- pathways %>%
mutate(
pathway_mode = as.integer(pathway_mode),
has_lift_edge = pathway_mode == 5,
has_ramp_edge = str_detect(str_to_lower(pathway_id), "ramp"),
has_escalator_edge = str_detect(str_to_lower(pathway_id), "escal")
) %>%
group_by(from_stop_id) %>%
summarise(
n_pathways = n(),
has_lift = any(has_lift_edge, na.rm = TRUE),
has_ramp = any(has_ramp_edge, na.rm = TRUE),
has_escalator = any(has_escalator_edge, na.rm = TRUE),
.groups = "drop"
)
# Unión con stops
stops_enhanced <- stops_uk %>%
left_join(pathways_summary, by = c("stop_id" = "from_stop_id")) %>%
mutate(
n_pathways = replace_na(n_pathways, 0),
has_lift = replace_na(has_lift, FALSE),
has_ramp = replace_na(has_ramp, FALSE),
has_escalator = replace_na(has_escalator, FALSE)
)stops_classified <- stops_enhanced %>%
mutate(
service_type = case_when(
str_detect(str_to_lower(stop_name), "underground") ~ "Underground",
str_detect(str_to_lower(stop_name), "overground") ~ "Overground",
str_detect(str_to_lower(stop_name), "dlr") ~ "DLR",
str_detect(str_to_lower(stop_name), "elizabeth") ~ "Elizabeth Line",
str_detect(str_to_lower(stop_name), "tram") ~ "Tram",
str_detect(str_to_lower(stop_name), "rail") ~ "National Rail",
TRUE ~ "Bus/Other"
),
station_complexity = case_when(
n_pathways > 50 ~ "High",
n_pathways > 20 ~ "Medium",
TRUE ~ "Low"
),
accessibility_score = case_when(
has_lift & has_ramp ~ 3,
has_lift | has_ramp ~ 2,
TRUE ~ 1
)
)En particular, se define una clasificación del tipo de servicio en función del nombre de la parada, lo que permite distinguir entre diferentes modos de transporte (metro, tren, tranvía, etc.). Asimismo, se construyen indicadores sintéticos de complejidad de estación y accesibilidad, que resumen de forma sencilla la estructura interna y las condiciones de uso de cada instalación.
Con el objetivo de evaluar la calidad del dataset resultante, se genera un informe de validación que resume algunos indicadores clave, como el número total de paradas, la disponibilidad de coordenadas o la presencia de información de conectividad. Este paso permite detectar posibles problemas en los datos y asegurar la consistencia del resultado final.
# Comprobar que todas las estaciones tengan coordenadas válidas
validation_report <- stops_classified %>%
st_drop_geometry() %>%
summarise(
total_stops = n(),
stops_with_coords = sum(!is.na(stop_lat_wgs84) & !is.na(stop_lon_wgs84)),
stops_with_pathways = sum(n_pathways > 0, na.rm = TRUE),
stops_with_lift = sum(has_lift, na.rm = TRUE),
stops_with_ramp = sum(has_ramp, na.rm = TRUE),
avg_pathways = mean(n_pathways, na.rm = TRUE)
)
dir.create("output", showWarnings = FALSE, recursive = TRUE)
write_csv(validation_report, "output/validation_report.csv")files <- c(
"output/london_transit_enhanced.gpkg",
"output/london_transit_enhanced.rds",
"output/london_transit_enhanced.csv",
"output/london_transit_enhanced.geojson"
)
file.remove(files)[1] TRUE TRUE TRUE TRUEWriting layer `london_transit_enhanced' to data source
`output/london_transit_enhanced.gpkg' using driver `GPKG'
Writing 4083 features with 19 fields and geometry type Point.# Exportar RDS
write_rds(
stops_classified %>% select(-matches("^buffer_")),
"output/london_transit_enhanced.rds"
)
# Exportar CSV
stops_classified %>%
st_drop_geometry() %>%
write_csv("output/london_transit_enhanced.csv")
# Exportar GeoJSON (visualización web)
st_write(
stops_classified %>% select(-matches("^buffer_")),
"output/london_transit_enhanced.geojson",
driver = "GeoJSON",
overwrite = TRUE
)Writing layer `london_transit_enhanced' to data source
`output/london_transit_enhanced.geojson' using driver `GeoJSON'
Writing 4083 features with 19 fields and geometry type Point.Output
Se ha obtenido un conjunto de datos limpio y enriquecido con geometría válida, metadatos de servicio, conectividad interna y un índice simple de accesibilidad y complejidad de estación.
Además, se genera un reporte de validación para comprobar cuántas paradas conservan coordenadas y cuánta conectividad aporta el feed.
Los ficheros generados con este procedimiento son:
output/validation_report.csv
output/london_transit_enhanced.gpkg
output/london_transit_enhanced.rds
output/london_transit_enhanced.csv
output/london_transit_enhanced.geojson
Visualización
1. Mapa de estaciones con plataformas codificadas
london_transit_enhanced <- read_csv("output/london_transit_enhanced.csv")Rows: 4083 Columns: 19
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): stop_id, stop_name, parent_station, level_id, service_type, station...
dbl (7): stop_lat, stop_lon, location_type, stop_lat_wgs84, stop_lon_wgs84, ...
lgl (6): stop_code, stop_desc, platform_code, has_lift, has_ramp, has_escalator
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.london_transit_enhanced %>%
filter(!is.na(stop_lat), !is.na(stop_lon)) %>%
leaflet() %>%
addTiles() %>%
addProviderTiles(providers$CartoDB.Positron) %>%
addCircleMarkers(
lat = ~stop_lat,
lng = ~stop_lon,
radius = 2.5,
color = "#2b8cbe",
fillOpacity = 0.6,
stroke = TRUE,
weight = 1,
opacity = 0.8,
popup = ~stop_name,
label = ~stop_name
) %>%
setView(lng = -0.1278, lat = 51.5074, zoom = 10.5) %>%
addScaleBar(position = "bottomleft") %>%
addMiniMap(
tiles = providers$CartoDB.Positron,
position = "topright",
width = 200,
height = 150,
toggleDisplay = TRUE
)Este mapa nos muestra la distribución geográfica completa de 4.583 paradas del sistema de transporte público de Londres extraídas del feed GTFS. Se observa una concentración radial en el centro de Londres con extensiones hacia los boroughs periféricos, evidenciando la cobertura multimodal del sistema.
2. Distribución espacial. Paradas por zona de Londres
london_transit_enhanced %>%
filter(!is.na(stop_lat), !is.na(stop_lon)) %>%
mutate(
zona = case_when(
stop_lat > 51.58 ~ "Norte",
between(stop_lat, 51.48, 51.58) ~ "Centro",
TRUE ~ "Sur/Sureste"
)
) %>%
count(zona) %>%
ggplot(aes(x = reorder(zona, n), y = n, fill = zona)) +
geom_col(alpha = 0.8, width = 0.7) +
geom_text(aes(label = n), vjust = -0.3, size = 5, fontface = "bold") +
coord_flip() +
labs(title = "Número de paradas por zona geográfica",
subtitle = "Distribución Norte-Centro-Sur de Londres") +
scale_fill_brewer(palette = "Set2", guide = "none") +
theme_minimal() +
theme(axis.title.y = element_blank())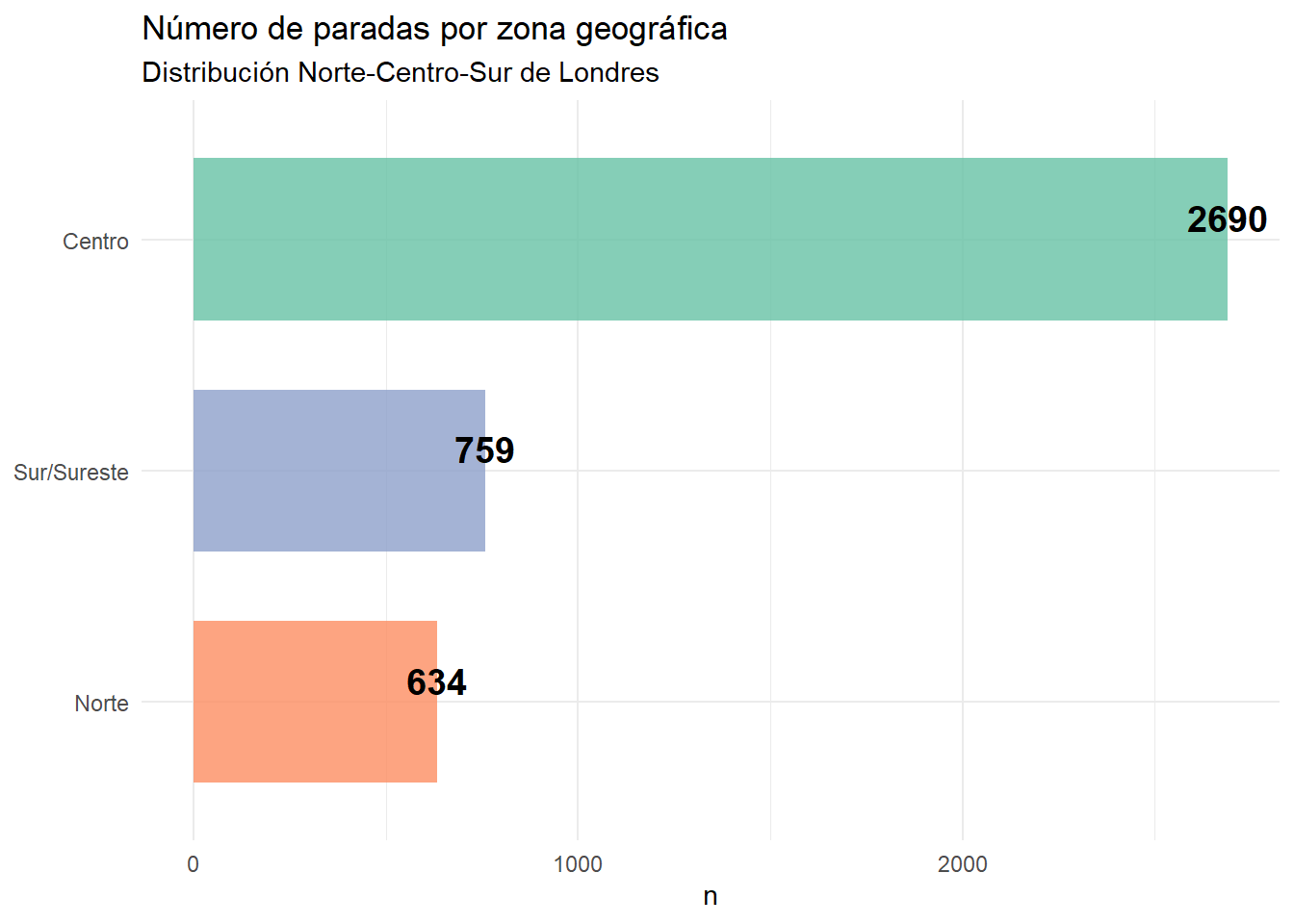
Este segundo gráfico revela una concentración del 62% de las paradas en la zona Centro (2.690 paradas), frente al 15% en Norte (634) y 17% en Sur/Sureste (759). Esta distribución refleja la centralidad del sistema de transporte londinense
El/los fichero(s) generados con este procedimiento/técnica/metodología se puede descargar de aquí.
![]()
Proyecto de Innovación Educativa Emergente (PIEE-2737007)