library(readr)
library(dplyr)
library(tidyr)
library(sf)
library(janitor)
library(ggplot2)
# Creamos rutas genéricas dentro del proyecto
#ruta_arbolado <- file.path("data", "raw", "arbratge-arbolado.csv")
#ruta_distritos <- file.path("data", "raw", "districtes-distritos.geojson")
# Leemos el CSV de arbolado
arbolado_csv <- read_csv2(
"../data/2526020016/arbratge-arbolado.csv",
locale = locale(encoding = "UTF-8"),
show_col_types = FALSE
) %>%
clean_names()
# Separamos coordenadas
arbolado_csv <- arbolado_csv %>%
separate(geo_point_2d, into = c("lat", "lon"), sep = ",") %>%
mutate(
lat = as.numeric(lat),
lon = as.numeric(lon)
)
# Creamos el objeto espacial del arboaldo
arbolado <- st_as_sf(
arbolado_csv,
coords = c("lon", "lat"),
crs = 4326,
remove = FALSE
)
# Leemos los distritos
distritos <- st_read(
"../data/2526020016/districtes-distritos.geojson",
quiet = TRUE
) %>%
clean_names()
# Y ahora nos aseguramos que sea el mismo CRS
if (st_crs(arbolado) != st_crs(distritos)) {
distritos <- st_transform(distritos, st_crs(arbolado))
}
# Seleccionamos variables útiles del arbolado
arbolado_limpio <- arbolado %>%
select(
objectid,
unidad_de_gestion,
tipo_situacion,
barrio,
lugar,
id_arbol,
nombre_botanico,
nombre_comun_castellano,
nombre_comun_valenciano,
grupo,
distrito,
geometry
)
# Seleccionamos solo variables útiles de distritos
distritos_limpio <- distritos %>%
select(geometry, everything())
# Creamos la unión espacial
arbolado_final <- st_join(arbolado_limpio, distritos_limpio, left = TRUE)
# Validamos las geometrías
arbolado_final <- st_make_valid(arbolado_final)
# Y eliminamos posibles columnas tipo lista antes de exportar
cols_lista <- sapply(arbolado_final, is.list)
arbolado_final <- arbolado_final[, !cols_lista]
# Creamos carpeta de salida
if (!dir.exists(file.path("data", "output"))) {
dir.create(file.path("data", "output"), recursive = TRUE)
}Arbolado urbano en València
Input
Hemos obtenido un conjunto de datos del portal Open Data València con información sobre el arbolado urbano de la ciudad. Cada observación corresponde a un árbol e incluye variables como el barrio, el tipo de situación o el nombre de la especie.
Asimismo, hemos utilizado la capa de distritos de València, disponible en el mismo portal, con el objetivo de incorporar una referencia territorial más clara a cada uno de los árboles.
Los conjuntos de datos empleados han sido los siguientes:
Inventario de arbolado: https://valencia.opendatasoft.com/explore/dataset/arbratge-arbolado/
Distritos de València: https://valencia.opendatasoft.com/explore/dataset/districtes-distritos/
Descripción
Hemos detectado que el dataset original, aunque es bastante completo, no está preparado para trabajar directamente con él como datos espaciales en R.
Por un lado, las coordenadas aparecen en una única columna en formato texto, lo que impide utilizarlas directamente como geometría. Por otro lado, el conjunto de datos incluye un número elevado de variables, muchas de las cuales no resultan necesarias para un análisis básico, dificultando así su manejo.
Además, aunque cada árbol cuenta con una localización, no existe una referencia territorial clara que permita agrupar o analizar la información por zonas de la ciudad, como pueden ser los distritos.
Por todo ello, resulta necesario realizar una transformación previa del dataset, con el objetivo de limpiarlo, convertirlo en una capa espacial y añadir información adicional que facilite su posterior análisis.
Tratamiento
Hemos llevado a cabo un proceso sencillo con el objetivo de preparar y mejorar el dataset.
En primer lugar, hemos leído el fichero CSV y hemos limpiado los nombres de las variables para facilitar su manejo. A continuación, hemos separado la columna que contenía las coordenadas en dos nuevas variables (latitud y longitud), convirtiéndolas posteriormente a formato numérico.
Una vez realizado este paso, hemos transformado la tabla en un objeto espacial de tipo punto mediante el uso de la librería sf.
Posteriormente, hemos cargado la capa de distritos y hemos verificado que ambas capas compartieran el mismo sistema de referencia de coordenadas. En caso contrario, hemos procedido a transformar una de ellas para asegurar su compatibilidad.
Seguidamente, hemos seleccionado únicamente las variables más relevantes del dataset de arbolado y hemos realizado una unión espacial con el fin de asignar a cada árbol el distrito correspondiente.
Por último, hemos exportado el resultado final en formato GeoPackage.
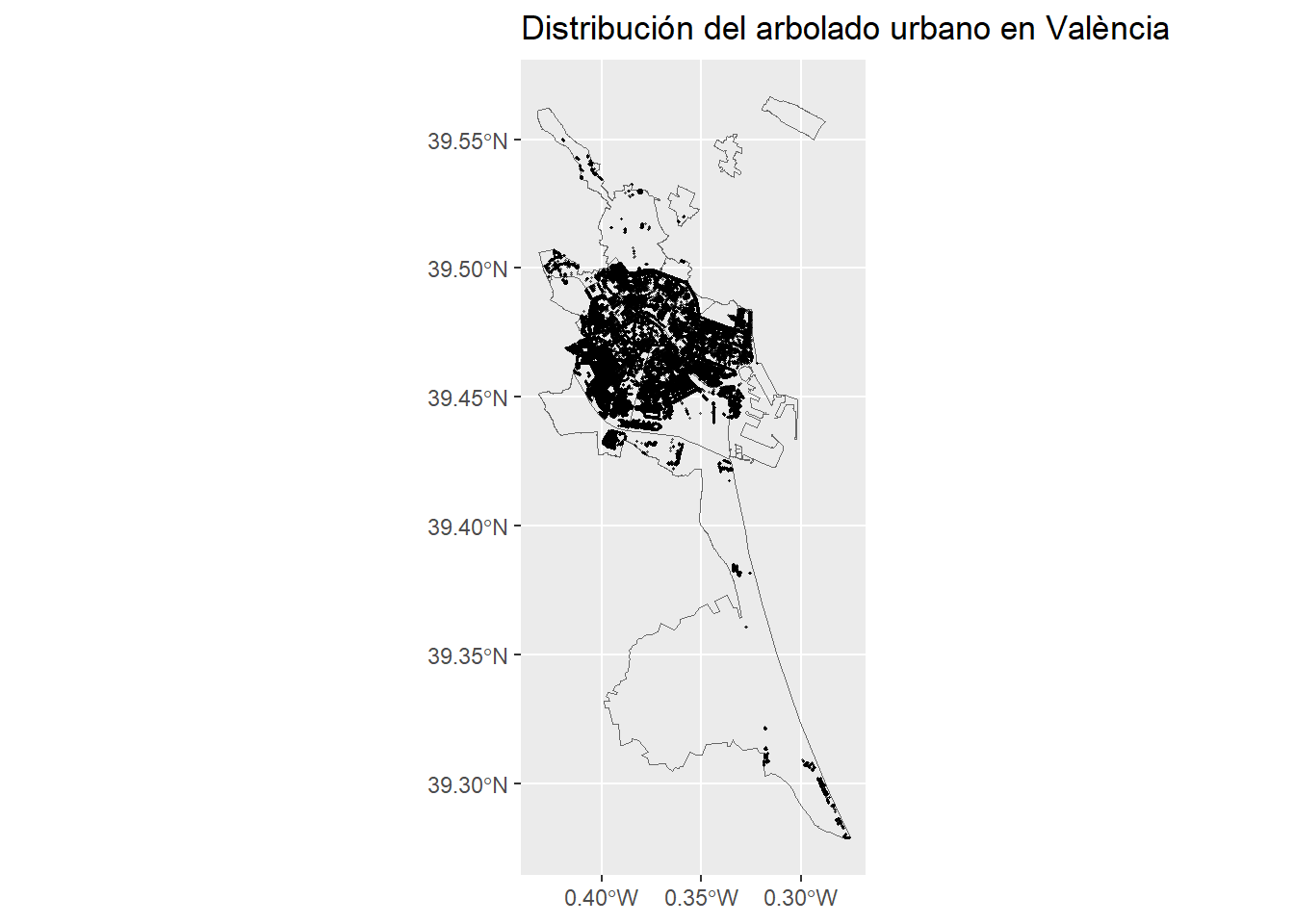
Análisis de la distribución del arbolado urbano en Valencia
El mapa deja bastante claro que el arbolado en Valencia no está repartido de forma uniforme. Se ve cómo se concentra sobre todo en el centro y en las zonas más consolidadas, donde la densidad es bastante alta. En cambio, cuando te vas alejando hacia la periferia, especialmente hacia el sur, los árboles aparecen mucho más dispersos y en menor cantidad.
Tiene bastante sentido si lo piensas, porque las zonas más antiguas y con más actividad suelen haber recibido más inversión en este tipo de cosas, mientras que otras áreas han quedado algo más atrás en ese aspecto.
Al final, más que un reparto equilibrado, lo que se observa es un patrón bastante centralizado que sigue la lógica del desarrollo urbano. Además, esto no es solo algo visual, también dice bastante sobre la calidad ambiental de cada zona. Donde hay más árboles suele haber más sombra, mejor temperatura y mejor calidad del aire.
En ese sentido, el arbolado se puede entender casi como un indicador de cómo de cuidada está cada zona, y deja ver que todavía hay margen para repartir mejor las zonas verdes y equilibrar un poco más la ciudad.
Este mapa nos sirve mucho para demostrar que sí que ha servido la transformación de los datos y que tiene una aplicación real que puede ayudar a la hora de una toma de decisiones, y que gracias a estos cambios, podemos conseguir mapas de mucho valor logrando combinar datos y transformándolos.
Conclusión de la transformación realizada:
La transformación que hemos hecho tiene sentido y aporta bastante valor porque parte de un dataset que, aunque era completo, no estaba listo para trabajar con él directamente, y lo convierte en algo mucho más útil. Al principio teníamos un CSV con las coordenadas en formato texto, muchas variables que no aportaban demasiado y sin una estructura espacial clara. Después del proceso, lo que tenemos es una capa geográfica limpia, con la geometría bien definida y además con una referencia territorial añadida, que son los distritos.
Y ahí es donde realmente está el valor. No es solo ordenar los datos, sino hacerlos más útiles. Ahora no solo vemos puntos en un mapa, sino que podemos analizar cosas de verdad, como comparar zonas, ver patrones o entender mejor cómo se distribuye el arbolado en la ciudad.
Además, el hecho de exportarlo en un formato como GeoPackage hace que no se quede solo en este trabajo. Es algo que se puede reutilizar fácilmente en otros proyectos o por otras personas sin tener que repetir todo el proceso.
En ese sentido, encaja bastante bien con la idea de DataEnhance UV, porque no solo usamos datos abiertos, sino que los dejamos preparados para un uso más realista y más cercano a un contexto profesional.
El/los fichero(s) generados con este procedimiento/técnica/metodología se puede(n) descargar de aquí.
![]()
Proyecto de Innovación Educativa Emergente (PIEE-3898312)