# Carga de librerías esenciales para el análisis espacial
libs <- c("tidyverse", "sf", "mapSpain", "osmdata", "ggspatial", "prettymapr", "ggplot2",
"dbscan", "leaflet","RColorBrewer")
installed_libs <- libs %in% rownames(installed.packages())
if (any(installed_libs == FALSE)) {install.packages(libs[!installed_libs])}
invisible(lapply(libs, library, character.only = TRUE))
rm(libs, installed_libs)Análisis y mejora de los Spots de Surf en la costa española
SURF
COSTA
DEPORTE
GKPG
Input
Este proyecto tiene como objetivo obtener y mejorar los datos de los puntos de surf (spots) en las costas de España. Los resultados están pensados para deportistas y escuelas que necesitan saber exactamente dónde ir a surfear.
Para que el listado sea realmente útil, vamos a quitar todos aquellos puntos que no tengan un nombre. En el surf, el nombre de un sitio es fundamental porque te da pistas sobre cómo es la zona: si el fondo es de arena o de roca, y qué tipo de ola te vas a encontrar. Un punto sin nombre no ayuda mucho a planificar una sesión.
Además, nos aseguraremos de que todos los sitios estén realmente en la costa, eliminando errores de coordenadas que a veces sitúan olas en el interior de la península por error.
Nuestra fuente principal es OpenStreetMaps (OSM), que tiene muchísima información geográfica de España. Pero, como es una plataforma donde cualquiera puede colaborar, tiene algunos problemas que debemos corregir: -Datos incompletos: En zonas con pocos usuarios, puede que falten sitios o la info esté vieja. -Nombres y sitios repetidos: A veces hay errores humanos y aparecen puntos duplicados o mal etiquetados. -Falta de precisión: No siempre se garantiza que el punto esté en el sitio exacto, sobre todo en zonas de difícil acceso.
A pesar de estos fallos, OSM sigue siendo una herramienta muy potente si se hace un buen tratamiento de los datos. Limpiando y filtrando la información, podemos conseguir un mapa de surf mucho más fiable y útil para todo el mundo.
Descripción
Para extraer la información de OpenStreetMap (OSM) utilizamos el paquete osmdata. El proceso consiste en definir el área de búsqueda con la función getbb() y construir una consulta específica con opq(). En este caso, filtramos los datos para obtener únicamente los elementos etiquetados como surfing dentro de la clave sport, que es la que identifica los spots y escuelas de surf en la cartografía.
# Indicamos el bounding box de España
bbox_esp <- getbb("Spain")
# Construimos la consulta para puntos de surf
query_surf <- bbox_esp %>%
opq(timeout = 300) %>% # Le damos 5 minutos al servidor para que no se rinda
add_osm_feature(key = "sport", value = "surfing")Al ejecutar la consulta, recibimos una lista con diferentes tipos de geometrías. Principalmente, obtenemos puntos, que marcan el sitio exacto de la rompiente o el acceso a la playa, y algunos polígonos, que suelen representar el área total de una escuela o una zona de surf protegida. Como nuestro objetivo es mapear la ubicación precisa de las olas para los deportistas, hemos decidido quedarnos solo con los puntos y descartar el resto de geometrías para facilitar el análisis posterior.
# Almacenamos el resultado (se genera una lista de objetos sf)
spots_raw <- osmdata_sf(query_surf)
spots_points <- spots_raw$osm_pointsAntes de realizar cualquier tratamiento, es fundamental hacer una primera representación gráfica para ver el estado real de los datos que acabamos de bajar. Esto nos permite identificar rápidamente si hay errores de ubicación, puntos repetidos o datos que se salen de nuestra zona de estudio.
# Representación inicial rápida [cite: 24]
ggplot() +
annotation_map_tile(type="cartolight") +
geom_sf(data = spots_points, color = "blue", size = 0.5)Zoom: 4Fetching 4 missing tiles
|
| | 0%
|
|================== | 25%
|
|=================================== | 50%
|
|==================================================== | 75%
|
|======================================================================| 100%...complete!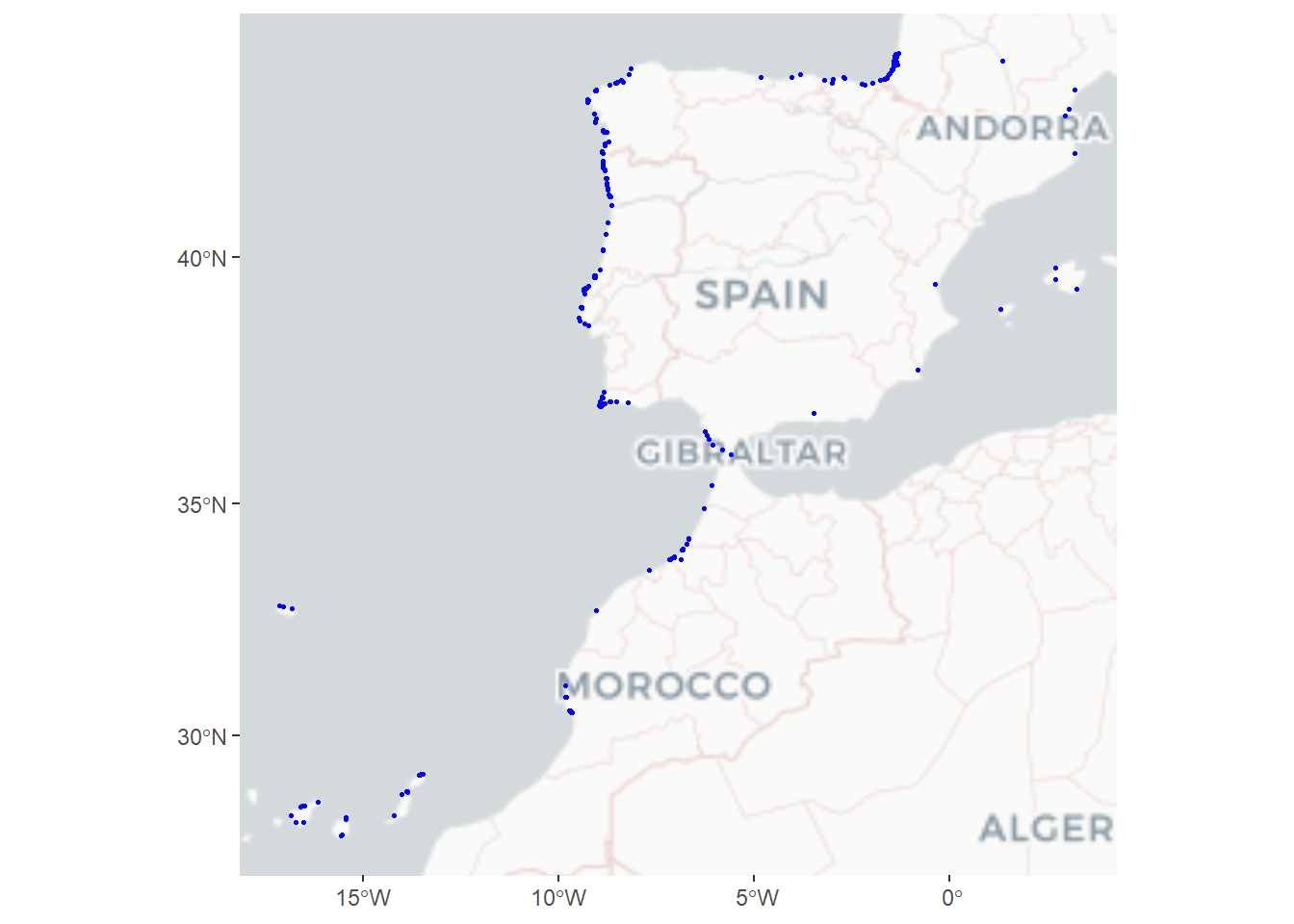
Al observar el primer mapa generado, podemos sacar varias conclusiones importantes:
-Puntos fuera de España: Se ve claramente que la consulta ha traído spots de Portugal, Francia y el norte de África. Esto sucede porque el “cuadro” de búsqueda (bounding box) de España es rectangular y acaba cogiendo zonas de países vecinos.
-Concentración de datos: En ciertas zonas de la costa (como el Cantábrico o Canarias), hay nubes de puntos azules muy densas. Esto es una señal de que existen muchos datos duplicados o muy cercanos que tendremos que tratar para que el mapa no se vea saturado.
-Errores de posición: Algunos puntos parecen caer ligeramente en tierra firme o lejos de la línea de costa, posiblemente por una mala georreferenciación por parte de los usuarios de OSM.
Este primer diagnóstico nos confirma que, aunque tenemos una buena base de datos, es totalmente necesario pasar a la fase de Tratamiento para limpiar estos errores y que el resultado final sea fiable y profesional.
Tratamiento
###Eliminación de observaciones incompletas (NA)
Como hemos comentado, al ser OpenStreetMap una plataforma colaborativa donde cualquier usuario puede subir información, es normal que muchos registros estén incompletos o mal definidos. En zonas con poco movimiento de usuarios, es muy habitual encontrar puntos con bastantes valores “NA” (sin información).
En este estudio, el nombre de cada punto es la columna más importante, ya que nos permite identificar el spot y saber de qué playa o zona estamos hablando. Un punto de surf sin nombre no tiene utilidad para un deportista que intenta planificar su ruta, y además complica mucho cualquier análisis posterior. Por este motivo, he decidido eliminar todas las observaciones que no tengan nombre; así garantizamos que el conjunto de datos final sea fiable y que cada punto represente un sitio real y localizable.
Además, aprovechamos este paso para limpiar el listado y quedarnos solo con las columnas que realmente nos interesan para el mapa final, como el identificador del punto y su nombre
###Filtro geográfico y eliminación de errores
Para solucionar el problema que vimos en el primer mapa, donde aparecían puntos en otros países, vamos a utilizar la función st_intersection(). Esta herramienta nos permite cruzar nuestros puntos de surf con un mapa oficial de los límites administrativos de España.
Para obtener este contorno oficial de la península y las islas, utilizamos la geometría de la administración pública filtrada para quedarnos únicamente con el territorio nacional. Al hacer esta “intersección”, el programa descarta automáticamente cualquier punto que caiga fuera de nuestras fronteras.Una vez realizado este proceso, volvemos a representar los datos para comprobar que el tratamiento ha funcionado correctamente y que ahora solo tenemos spots validados dentro de la costa española.
# Obtenemos el contorno administrativo de España
espana_sf <- esp_get_country() %>%
st_transform(4326) # Aseguramos que use las mismas coordenadas que los spots
# Ahora ya podemos hacer la intersección
spots_final <- st_intersection(spots_clean, espana_sf)Output
Una vez finalizado todo el proceso de limpieza y filtrado, presentamos el resultado final del estudio. El objetivo era transformar una base de datos bruta y con errores en un conjunto de información útil para cualquier surfista en España.
Para facilitar la navegación por el mapa, hemos utilizado una técnica de agrupación de marcadores (clusters). Como se puede observar en la imagen, esto permite ver de un vistazo las zonas con mayor densidad de spots, como la costa cantábrica o Galicia, sin que el mapa se sature de iconos. Al hacer zoom, los grupos se dividen hasta mostrar la ubicación exacta de cada spot, incluyendo un desplegable con su nombre oficial.
# Crear el mapa interactivo final
leaflet(spots_final) %>%
addTiles() %>%
addMarkers(
clusterOptions = markerClusterOptions(), # Agrupamos para mejorar visualización
popup = ~paste("<b>Spot:</b>", name)
)Un detalle interesante que surge tras el tratamiento es la distribución de los datos. Aunque hemos limpiado los puntos que caían en otros países, observamos que en zonas como las Islas Canarias la representación es menor de lo esperado. Esto es un ejemplo perfecto de lo que comentábamos en el Input: al ser una base de datos colaborativa (OSM), puede que en ciertas regiones los colaboradores usen etiquetas diferentes o que la información sea todavía incompleta. Este resultado subraya la importancia de este proyecto dentro de DataEnhance UV, ya que identifica dónde es necesario seguir mejorando y aportando datos espaciales.
Finalmente, para que este trabajo sea realmente útil y reproducible, el conjunto de datos depurado se ha exportado en formato GeoPackage. Este archivo incluye únicamente los puntos validados, con sus nombres correctos y ubicaciones exactas dentro del territorio nacional, listo para ser utilizado en cualquier software de mapas profesional.
# Guardado del fichero reproducible
st_write(spots_final, "spots_surf_españa_clean.gpkg", delete_dsn = TRUE, quiet = TRUE)El/los fichero(s) generados con este procedimiento/técnica/metodología se puede(n) descargar de aquí.
![]()
Proyecto de Innovación Educativa Emergente (PIEE-3898312)