Esperanza de vida por provincias España 1975-2022
Input
En España, el INE se refiere al Instituto Nacional de Estadística. Este organismo público tiene como objetivo principal la producción y difusión de estadísticas oficiales de España. Dispone de miles de bases de datos abiertas de temática muy variada a nivel nacional.
El conjunto de datos a analizar corresponde a la Esperanza de Vida al Nacimiento a nivel provincial. Este dataframe contiene la esperanza de vida al nacer, sin distinción de sexos, de cada provincia desde 1975 hasta 2022.
URL directa a la web de descarga aquí.
Descripcion
Cargamos las librerías necesarias:
Importamos la base de datos, dado que el archivo es XLSx y hay comentarios en celdas que no pertenecen al dataset, seleccionamos la matriz de celdas que nos interesan.
datos <- readxl::read_xlsx("data/espvida_prov_75_22.xlsx", range = "A7:AW60", col_names = F)
head(datos)# A tibble: 6 × 49
...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ...11 ...12 ...13
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 <NA> 2022 2021 2020 2019 2018 2017 2016 2015 2014 2013 2012 2011
2 Ambos… <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
3 02 Al… 82.99 83.21 81.36 83.31 83.36 83.47 83.14 82.87 82.66 82.84 82.65 82.43
4 03 Al… 82.62 82.21 82.42 83.09 82.69 82.68 82.85 82.51 82.66 82.57 81.99 82.17
5 04 Al… 81.31 80.61 81.2 81.93 81.14 81.75 81.7 81.11 81.82 81.58 81.03 80.79
6 01 Ar… 84.13 84.31 83.59 84.76 84.32 83.89 84.18 83.49 84.38 83.36 83.53 83.04
# ℹ 36 more variables: ...14 <chr>, ...15 <chr>, ...16 <chr>, ...17 <chr>,
# ...18 <chr>, ...19 <chr>, ...20 <chr>, ...21 <chr>, ...22 <chr>,
# ...23 <chr>, ...24 <chr>, ...25 <chr>, ...26 <chr>, ...27 <chr>,
# ...28 <chr>, ...29 <chr>, ...30 <chr>, ...31 <chr>, ...32 <chr>,
# ...33 <chr>, ...34 <chr>, ...35 <chr>, ...36 <chr>, ...37 <chr>,
# ...38 <chr>, ...39 <chr>, ...40 <chr>, ...41 <chr>, ...42 <chr>,
# ...43 <chr>, ...44 <chr>, ...45 <chr>, ...46 <chr>, ...47 <chr>, …Como podemos observar, a pesar de haber importado las celdas de interés, el conjunto de datos no está preparado para trabajar.
Tratamiento
Empezamos eliminando la segunda fila, cuya aportación es que los datos son de ambos sexos.
datos <- datos[-2, ]
head(datos)# A tibble: 6 × 49
...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ...11 ...12 ...13
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 <NA> 2022 2021 2020 2019 2018 2017 2016 2015 2014 2013 2012 2011
2 02 Al… 82.99 83.21 81.36 83.31 83.36 83.47 83.14 82.87 82.66 82.84 82.65 82.43
3 03 Al… 82.62 82.21 82.42 83.09 82.69 82.68 82.85 82.51 82.66 82.57 81.99 82.17
4 04 Al… 81.31 80.61 81.2 81.93 81.14 81.75 81.7 81.11 81.82 81.58 81.03 80.79
5 01 Ar… 84.13 84.31 83.59 84.76 84.32 83.89 84.18 83.49 84.38 83.36 83.53 83.04
6 33 As… 82.46 82.75 82.1 82.84 82.64 82.59 82.38 82.21 82.11 82.19 81.52 81.3
# ℹ 36 more variables: ...14 <chr>, ...15 <chr>, ...16 <chr>, ...17 <chr>,
# ...18 <chr>, ...19 <chr>, ...20 <chr>, ...21 <chr>, ...22 <chr>,
# ...23 <chr>, ...24 <chr>, ...25 <chr>, ...26 <chr>, ...27 <chr>,
# ...28 <chr>, ...29 <chr>, ...30 <chr>, ...31 <chr>, ...32 <chr>,
# ...33 <chr>, ...34 <chr>, ...35 <chr>, ...36 <chr>, ...37 <chr>,
# ...38 <chr>, ...39 <chr>, ...40 <chr>, ...41 <chr>, ...42 <chr>,
# ...43 <chr>, ...44 <chr>, ...45 <chr>, ...46 <chr>, ...47 <chr>, …Lo siguiente es fijar las variables con las que trabajaremos.
# Extraemos la primera fila como nombres de las variables
nombres_columnas <- as.character(datos[1, ])
# Eliminamos la primera fila del data frame
datos <- datos[-1, ]
# Asignamos los nombres de las variables al data frame
names(datos) <- nombres_columnas
head(datos)# A tibble: 6 × 49
`` `2022` `2021` `2020` `2019` `2018` `2017` `2016` `2015` `2014` `2013`
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 02 Alba… 82.99 83.21 81.36 83.31 83.36 83.47 83.14 82.87 82.66 82.84
2 03 Alic… 82.62 82.21 82.42 83.09 82.69 82.68 82.85 82.51 82.66 82.57
3 04 Alme… 81.31 80.61 81.2 81.93 81.14 81.75 81.7 81.11 81.82 81.58
4 01 Arab… 84.13 84.31 83.59 84.76 84.32 83.89 84.18 83.49 84.38 83.36
5 33 Astu… 82.46 82.75 82.1 82.84 82.64 82.59 82.38 82.21 82.11 82.19
6 05 Ávila 83.41 83.57 82.24 83.95 83.44 83.32 83.28 82.57 83.15 82.88
# ℹ 38 more variables: `2012` <chr>, `2011` <chr>, `2010` <chr>, `2009` <chr>,
# `2008` <chr>, `2007` <chr>, `2006` <chr>, `2005` <chr>, `2004` <chr>,
# `2003` <chr>, `2002` <chr>, `2001` <chr>, `2000` <chr>, `1999` <chr>,
# `1998` <chr>, `1997` <chr>, `1996` <chr>, `1995` <chr>, `1994` <chr>,
# `1993` <chr>, `1992` <chr>, `1991` <chr>, `1990` <chr>, `1989` <chr>,
# `1988` <chr>, `1987` <chr>, `1986` <chr>, `1985` <chr>, `1984` <chr>,
# `1983` <chr>, `1982` <chr>, `1981` <chr>, `1980` <chr>, `1979` <chr>, …La columna de las provincias sigue sin titulo, además contiene dos valores, el código y el nombre de prvincia, que dividiremos en dos variables.
# Ponemos nombre provisional a la columna de las provincias
names(datos)[1] <- "PROV"
# Dividimos la variable PROV en cpro (codigo provincia) y nombrepro (nombre de provincia)
datos$CPRO <- substr(datos$PROV, 1, 2) # Extraemos los dos primeros caracteres como cpro
datos$NOMBREPRO <- substr(datos$PROV, 4, nchar(datos$PROV)) # Extraemos el resto como nombrepro
# Eliminamos la variable PROV
datos <- datos[,-1]
# Reordenamos las variables colocando las recientemente creadas al principio
datos <- datos %>%
select(CPRO, NOMBREPRO, everything())
head(datos)# A tibble: 6 × 50
CPRO NOMBREPRO `2022` `2021` `2020` `2019` `2018` `2017` `2016` `2015` `2014`
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 02 Albacete 82.99 83.21 81.36 83.31 83.36 83.47 83.14 82.87 82.66
2 03 Alicante… 82.62 82.21 82.42 83.09 82.69 82.68 82.85 82.51 82.66
3 04 Almería 81.31 80.61 81.2 81.93 81.14 81.75 81.7 81.11 81.82
4 01 Araba/Ál… 84.13 84.31 83.59 84.76 84.32 83.89 84.18 83.49 84.38
5 33 Asturias 82.46 82.75 82.1 82.84 82.64 82.59 82.38 82.21 82.11
6 05 Ávila 83.41 83.57 82.24 83.95 83.44 83.32 83.28 82.57 83.15
# ℹ 39 more variables: `2013` <chr>, `2012` <chr>, `2011` <chr>, `2010` <chr>,
# `2009` <chr>, `2008` <chr>, `2007` <chr>, `2006` <chr>, `2005` <chr>,
# `2004` <chr>, `2003` <chr>, `2002` <chr>, `2001` <chr>, `2000` <chr>,
# `1999` <chr>, `1998` <chr>, `1997` <chr>, `1996` <chr>, `1995` <chr>,
# `1994` <chr>, `1993` <chr>, `1992` <chr>, `1991` <chr>, `1990` <chr>,
# `1989` <chr>, `1988` <chr>, `1987` <chr>, `1986` <chr>, `1985` <chr>,
# `1984` <chr>, `1983` <chr>, `1982` <chr>, `1981` <chr>, `1980` <chr>, …El dataframe está preparado para trabajar con él. No obstante, sigue sin poder ser representado. Para ello:
# Importamos el sf de las provincias españolas
spain <- mapSpain::esp_get_prov()
spain <- spain %>%
dplyr::select(codauto, cpro, geometry)
# Juntamos el df de la esperanza de vida y el df de españa
datos <- inner_join(datos, spain, by=c("CPRO"="cpro"))
datos <- datos %>%
select(codauto, CPRO, NOMBREPRO, geometry,everything())
# Convertimos el df a sf para que pueda ser representado
datos_sf <- st_as_sf(datos, crs = 4258)
head(datos)# A tibble: 6 × 52
codauto CPRO NOMBREPRO geometry `2022` `2021` `2020` `2019`
<chr> <chr> <chr> <MULTIPOLYGON [°]> <chr> <chr> <chr> <chr>
1 08 02 Albacete (((-0.92896 38.78681, -0… 82.99 83.21 81.36 83.31
2 10 03 Alicante/… (((-0.036857 38.88119, -… 82.62 82.21 82.42 83.09
3 01 04 Almería (((-1.640825 37.38238, -… 81.31 80.61 81.2 81.93
4 16 01 Araba/Ála… (((-2.547264 43.08767, -… 84.13 84.31 83.59 84.76
5 03 33 Asturias (((-4.536122 43.40053, -… 82.46 82.75 82.1 82.84
6 07 05 Ávila (((-4.729031 41.15078, -… 83.41 83.57 82.24 83.95
# ℹ 44 more variables: `2018` <chr>, `2017` <chr>, `2016` <chr>, `2015` <chr>,
# `2014` <chr>, `2013` <chr>, `2012` <chr>, `2011` <chr>, `2010` <chr>,
# `2009` <chr>, `2008` <chr>, `2007` <chr>, `2006` <chr>, `2005` <chr>,
# `2004` <chr>, `2003` <chr>, `2002` <chr>, `2001` <chr>, `2000` <chr>,
# `1999` <chr>, `1998` <chr>, `1997` <chr>, `1996` <chr>, `1995` <chr>,
# `1994` <chr>, `1993` <chr>, `1992` <chr>, `1991` <chr>, `1990` <chr>,
# `1989` <chr>, `1988` <chr>, `1987` <chr>, `1986` <chr>, `1985` <chr>, …Output
Hemos obtenido un nuevo objeto sf, con 52 observaciones y 52 variables
# Convertimos el df a sf para que pueda ser representado
datos_sf <- st_as_sf(datos, crs = 4258)
class(datos_sf)[1] "sf" "tbl_df" "tbl" "data.frame"dim(datos_sf)[1] 52 52Representamos el conjunto de datos obtenido.
# Representaremos la esperanza de vida en 2021
espvida2021 <- as.numeric(datos$'2021')
# Mapa de calor
ggplot() +
geom_sf(data = datos_sf, aes(fill = espvida2021)) +
scale_fill_gradient(low = "darkblue", high = "yellow", name = "Esperanza de vida") +
labs(title = "Esperanza de vida por provincias en España") +
theme_minimal()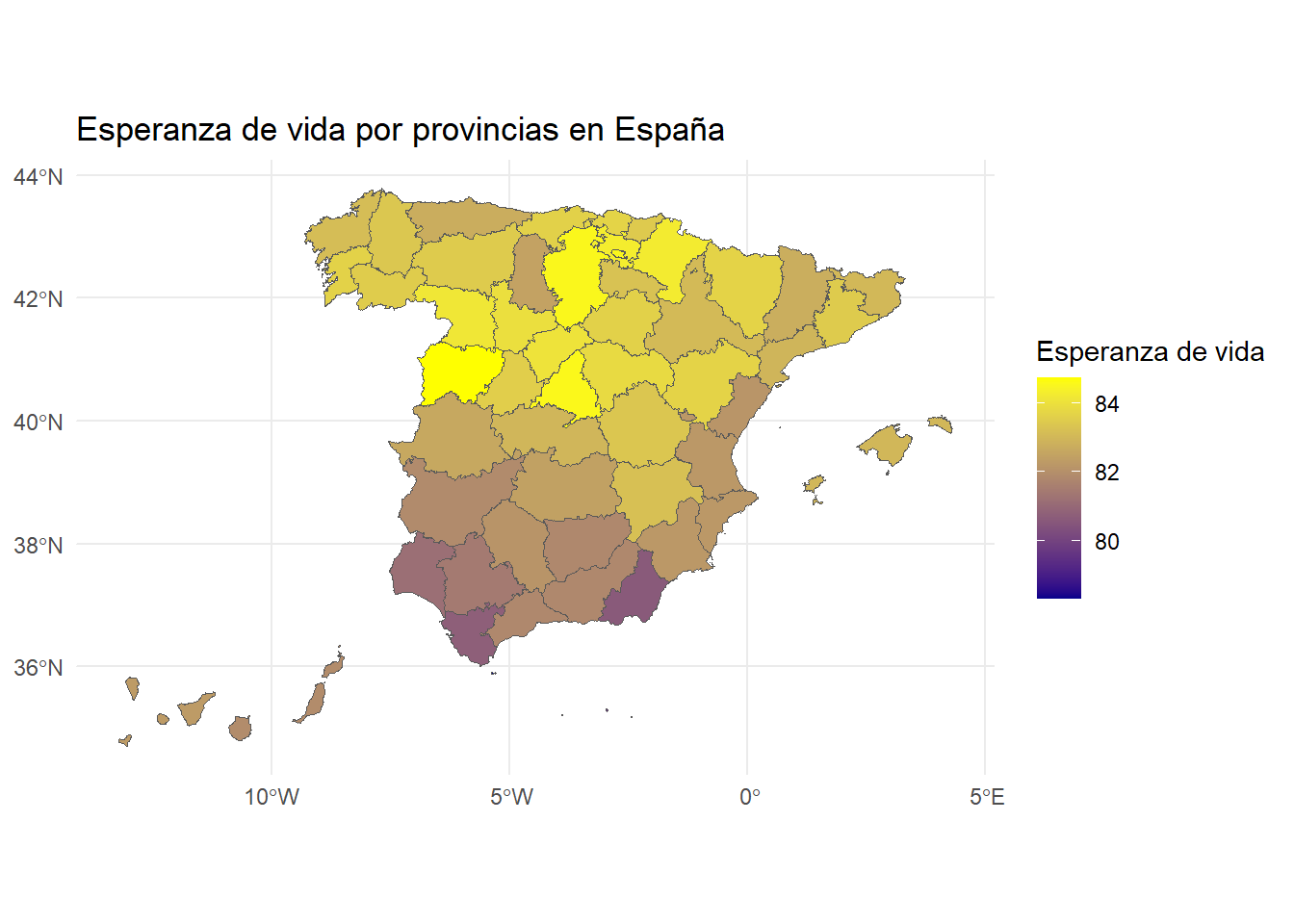
sf::st_write(datos_sf, "esp_vida_prov.gpkg")El dataset resultante queda disponible para su descarga aquí.
![]()
Proyecto de Innovación Educativa Emergente (PIEE-2737007)