libs <- c("tidyverse", "sf", "mapSpain", "osmdata", "ggspatial", "leaflet")
installed_libs <- libs %in% rownames(installed.packages())
if (any(installed_libs == F)) {install.packages(libs[!installed_libs])}
invisible(lapply(libs, library, character.only = T))
rm(libs, installed_libs)Datos de estaciones ferroviarias España
Estaciones de tren
España
Transporte
Transporte público
Input
OpenStreetMap (OSM) es una plataforma colaborativa que proporciona datos geoespaciales abiertos utilizados en diversos proyectos de análisis y modelado. En este estudio, trabajaré con un conjunto de datos obtenido de OpenStreetMaps (OSM), que incluye información sobre estaciones y paradas ferroviarias en España. Este conjunto de datos contiene detalles como el nombre de la estación, sus coordenadas geográficas y otros atributos espaciales.
Si bien los datos de OSM son muy útiles para el análisis y el modelado, en ocasiones presentan ciertos desafíos, en mi caso podemos observar la presencia de estaciones fuera del territorio español, registros sin nombre y duplicados generados por pequeñas variaciones en el nombre de las estaciones (antes de la modificación del data frame Madrid-Atocha era considerada diferente a Madrid Atocha) o coordenadas. En este proyecto, aplicaré técnicas de limpieza de datos para mejorar la precisión y utilidad del conjunto de datos. Esto incluye la eliminación de registros fuera de España, la normalización de nombres, la detección y eliminado de duplicados aproximados.
Este dataset es un recurso valioso para estudios de movilidad, planificación del transporte ferroviario y análisis geoespacial. Al trabajar con datos abiertos de OSM, contribuimos a la mejora de la información para futuros proyectos de análisis y visualización de datos de infraestructuras de transporte en España.
Descripción
Cargamos las librerías necesarias:
Empezamos creando el bounding box de España, obtenido del paquete mapSpain:
spain <- mapSpain::esp_get_country(moveCAN = F)
bbox_spain <- c(-10, 35, 5, 45)Una vez ya hemos creado el bounding box, obtenemos las paradas de tren de España mediante osmdata:
q1 <- bbox_spain %>%
osmdata::opq(timeout = 3600) %>%
osmdata::add_osm_feature("railway", "station")
tren <- osmdata_sf(q1)
tren_points <- tren$osm_pointsObtenemos un data frame con 10948 observaciones y 292 variables. Vamos a hacer una primera observación del mapa antes de modificarlo.
ggplot() +
ggspatial::annotation_map_tile(type = "cartolight") +
geom_sf(data = tren_points, color = "#229E6B", alpha = .5) +
theme_minimal()Zoom: 4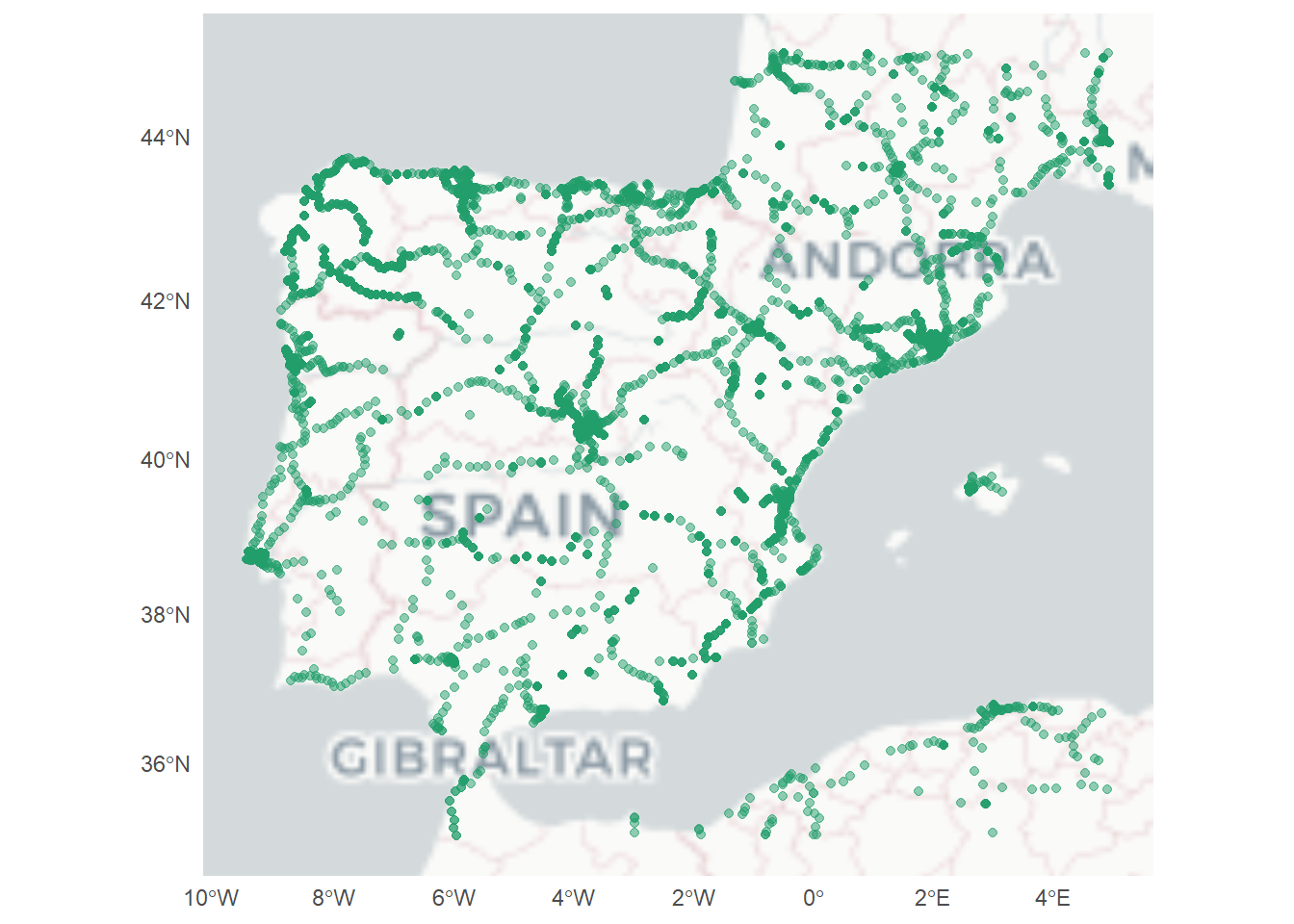
Tratamiento
Aquí podemos observar como la columna name contiene un total de 8,220 valores NA. Además, observando el mapa y el dataset se pueden detectar múltiples registros duplicados que podían clasificarse en dos categorías:
Duplicados por variaciones ortográficas: Diferentes representaciones de un mismo nombre, como “Madrid-Atocha” y “Madrid Atocha”.
Duplicados por proximidad geográfica: Registros con coordenadas casi idénticas que representan la misma estación.
Para empezar, voy a quedarme solamente con las columnas del nombre y la de la geometría, esto lo hago para después poder estudiar más facilmente los duplicados de proximidad geográfica y los duplicados por variaciones ortográficas.
tren_points4 <- tren_points %>%
select(name, geometry) Ahora voy a continuar normalizando los nombres de las estaciones, haré esto eliminando espacios extra y convirtiendo las letras a minúsculas para evitar diferencias innecesarias en la comparación.
tren_points4 <- tren_points4 %>%
mutate(name_clean = str_trim(str_to_lower(name))) A continuación voy a redondear las coordenadas a 4 decimales para fusionar estaciones prácticamente idénticas en ubicación.
Seguidamente agrupo las estaciones con nombres similares y ubicaciones cercanas para identificar posibles duplicados.
duplicados_aprox <- tren_points4 %>%
group_by(name_clean, lat, lon) %>%
filter(n() > 1)Por último elimino los duplicados aproximados, es decir, nos quedamos con la primera aparición de cada grupo de duplicados.
tren_points4 <- tren_points4 %>%
distinct(name_clean, lat, lon, .keep_all = TRUE) %>%
select(-name_clean, -lat, -lon) Durante este proceso, se han eliminado registros duplicados basados en la similitud de nombres y cercanía geográfica. Como resultado, algunas estaciones sin nombre (NA en name) también fueron eliminadas. Esto ocurrió porque al redondear las coordenadas para identificar estaciones cercanas, aquellas sin nombre que estaban en la misma ubicación que una estación con nombre fueron reemplazadas por esta última. En otras palabras, cuando dos registros tenían coordenadas casi idénticas, el proceso de eliminación de duplicados priorizó el que tenía un nombre sobre el que no lo tenía.
Dado que el criterio de eliminación de duplicados favoreció las estaciones con nombre, algunas estaciones sin nombre desaparecieron al agruparse con registros de ubicación similar. Esto se ha realizaado de esta manera ya que lo que buscamos es consolidar la base de datos eliminando información redundante.
Este enfoque ha permitido reducir registros duplicados y mejorar la precisión geoespacial del dataset, aunque con la consecuencia de que algunas estaciones sin nombre fueron eliminadas en el proceso.
Ahora voy a convertir a formato espacial (sf) para visualización y análisis
tren_points4 <- st_as_sf(tren_points4)Transformo los datos de las estaciones para que coincidan con el CRS del mapa de España.
tren_points4 <- st_transform(tren_points4, st_crs(spain))Elimino cualquier estación que, por error en los datos, esté fuera del territorio español.
tren_points4 <- tren_points4[st_within(tren_points4, spain, sparse = FALSE), ]Este paso garantiza que solo se mantengan las estaciones ubicadas dentro de los límites de España, descartando aquellas que por errores en los datos aparecían en ubicaciones incorrectas.
Finalmente, generamos un mapa interactivo con Leaflet para visualizar las estaciones de tren tras la limpieza y el filtrado de datos:
leaflet(data = tren_points4) %>%
addTiles() %>%
addCircleMarkers(
~st_coordinates(geometry)[,1],
~st_coordinates(geometry)[,2],
popup = ~name,
label = ~name,
color = "#229E6B", fillOpacity = 0.7, radius = 4
) %>%
setView(lng = -3.7038, lat = 40.4168, zoom = 6) Output
Este mapa permite explorar visualmente la distribución de las estaciones de tren en España después del proceso de limpieza y normalización de datos, asegurando que solo se representen registros válidos y únicos.
sf::st_write(tren_points, "tren_points.gpkg", delete_dsn = TRUE)El/los fichero(s) generados con este procedimiento se pueden descargar de aquí.
![]()
Proyectos de Innovación Educativa Emergente PIEE-2737007 y PIEE-3325394