1. Un investigador quiere
aplicar la escalera de Tukey en sus datos. Presumiblemente efectuará una:
A) Transformación
no lineal
B) Transformación lineal
C) Transformación a la
distribución normal
2. ¿Por qué preferimos la
correlación de Pearson a la covarianza?:
A) Porque está acotada
B) Porque no tiene
unidades
C) Tanto por estar
acotada como por no tener unidades.
3. Sabemos que la
distribución teórica subyacente es simétrica y con media 4. ¿Cuál de las
siguientes distribuciones teóricas podría encajar en tal descripción?:
A) Distribución normal
B) Distribución t de
Student
C) Tanto la distribución
normal como la distribución t de Student
4. Estamos midiendo la
estatura en centímetros. ¿Cuál de los siguientes estadísticos de variabilidad
ofrece la medida en la misma medida que los datos originales (cm)?:
A) Tanto la desviación típica como
la desviación media
B) La desviación típica
C) La desviación media
5. Si empleamos el término
“función de densidad de probabilidad”, nos referimos a una:
A) Variable aleatoria
discreta
B) Variable aleatoria continua
C) Variable aleatoria
normalizada
6. El diagrama de caja y
bigotes nos informa fácilmente sobre:
A) La tendencia central, variabilidad y forma de una
distribución.
B) Únicamente la tendencia
central y variabilidad de una distribución.
C) Únicamente la tendencia
central y forma de una distribución.
7. Tenemos un experimento
en el que se examina el tiempo que los bebés prestan atención (en ms) al fonema
/e/ en bebés cuyos padres son bien ambos bilingües castellano-valenciano, bien
ambos monolingües castellano-hablantes. La variable dependiente es:
A) El tiempo
B) La lengua materna de
los padres
C) El fonema /e/
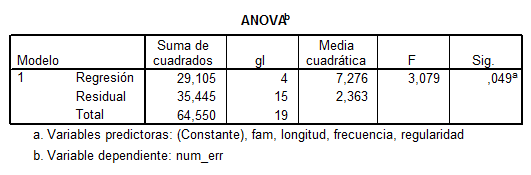
8. (TABLA 1) Indica qué
porcentaje de varianza de la variable “número de errores” explica la ecuación de
regresión:
A) 45%
B) 67%
C) No se ha proporcionado
dicha información en la tabla
9. (TABLA 1) ¿Crees que ha
podido haber problemas de multicolinealidad?:
A) No
B) Sí
C) No se ha
proporcionado dicha información en la tabla
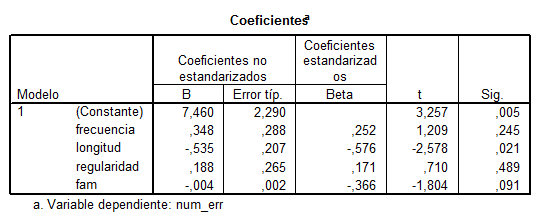
10. (TABLA 1) ¿Cuál es el
peor predictor en la ecuación?:
A) regularidad
B) fam
C) longitud
Tabla 1. Queremos predecir
el número de errores a partir de 4 predictores (fam, longitud, frecuencia,
regularidad). Se ofrece el output de SPSS para la regresión múltiple.