|
|
|
|
IMAGE CODING
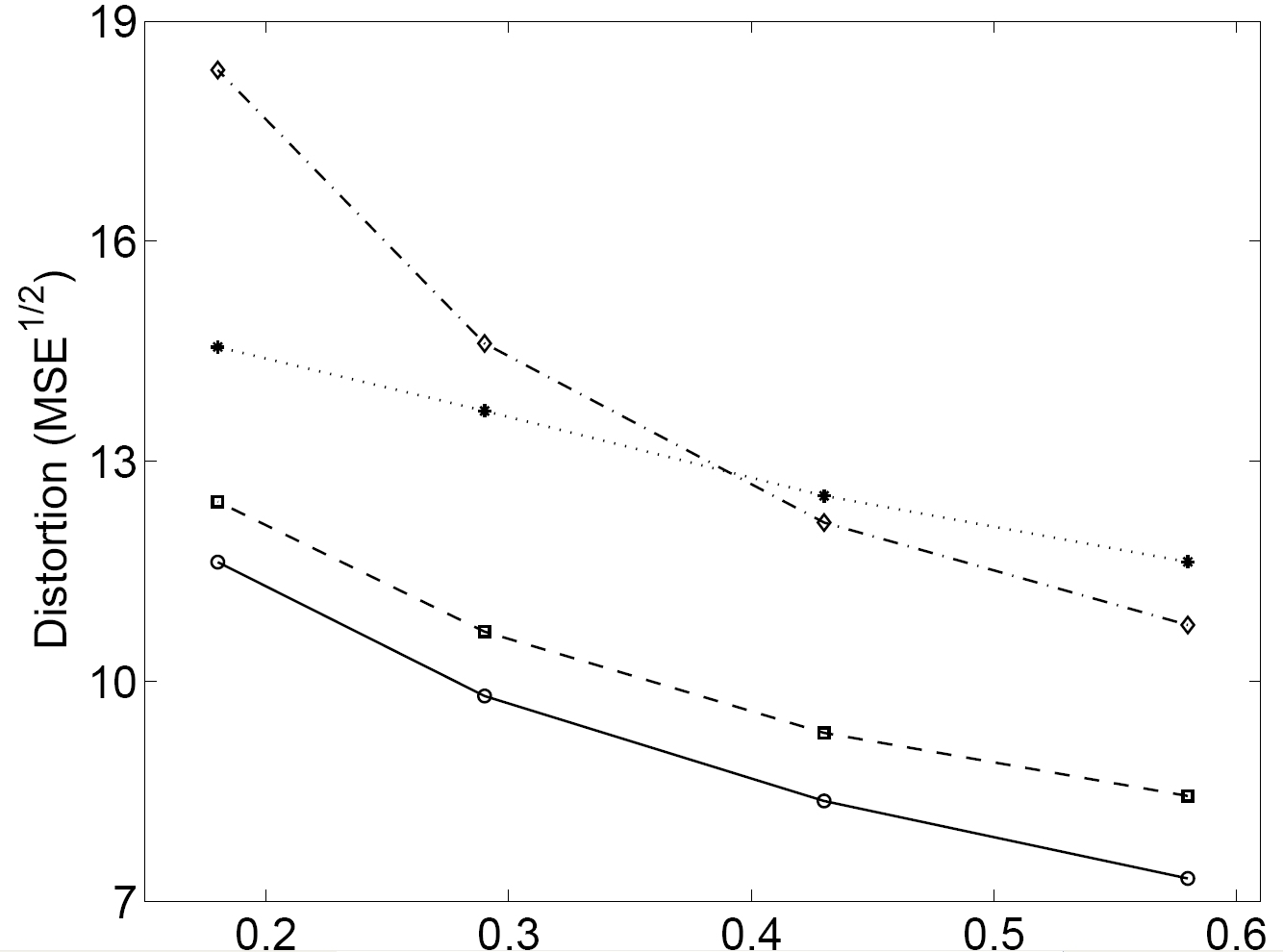
Image compression systems commonly operate by transforming the input signal into a new representation whose elements are then independently quantized. The success of such a system depends on two properties of the representation. First, the coding rate is minimized only if the elements of the representation are statistically independent. Second, the perceived coding distortion is minimized only if the errors in a reconstructed image arising from quantization of the different elements of the representation are perceptually independent. According to the Barlow hypothesis , the perceptual representation of the image should also be statistically efficient. The match with natural image statistics and the fact that most of the image coding applications are intended to be judged by a human observer have motivated the use of human vision models and perceptual metrics to inspire the image representation in transform coders as well as the bit allocation in the selected representation (e.g. JPEG and JPEG2000). Our work in this field has been focused in using accurate models of the perceptual non-linearties to improve these standards. The key issue is making a uniform quantization in a perceptually uniform domain. We have developed a distortion criterion that unifies all the results in perceptually based quantization: making a uniform quantization in the perceptual domain is equivalent to restrict the Maximum Perceptual Error (MPE) in each component of the perceptual representation. When using this concept, all the proposed approaches (ours and those of other people, e.g. JPEG and JPEG2000) are just particular cases using different perception models. The first attempts to use human vision models in tranform coding were too simple: the original JPEG standard [Wallace91] used the block-DCT as the first stage of the perceptual representation and a simple linear approximation of the second stage was used to design bit allocation (using achromatic and chromatic CSFs). Over the last years, we have shown that using progressively more accurate approximations of the second non-linear stage significantly improve the JPEG results [ Malo95 , Malo99 , Malo00 , Epifanio03 , Malo03 , Malo06a ]. In particular, we have shown that linear transforms cannot achieve either of the (statistical and perceptual independence) goals, and we have proposed an adaptive non-linear image representation (the divisive normalization) that greatly reduces both the statistical and the perceptual redundancy amongst representation elements. We developed an efficient method of inverting this representation, and we demonstrated that this dual reduction in dependency can greatly improve the visual quality of compressed images. For an extended review of the proposed methods in the context of color image coding, see [ Malo02 ] (in Spanish!). An illustration of the results that summarizes our work in this field is given below (0.18 bits/pix):
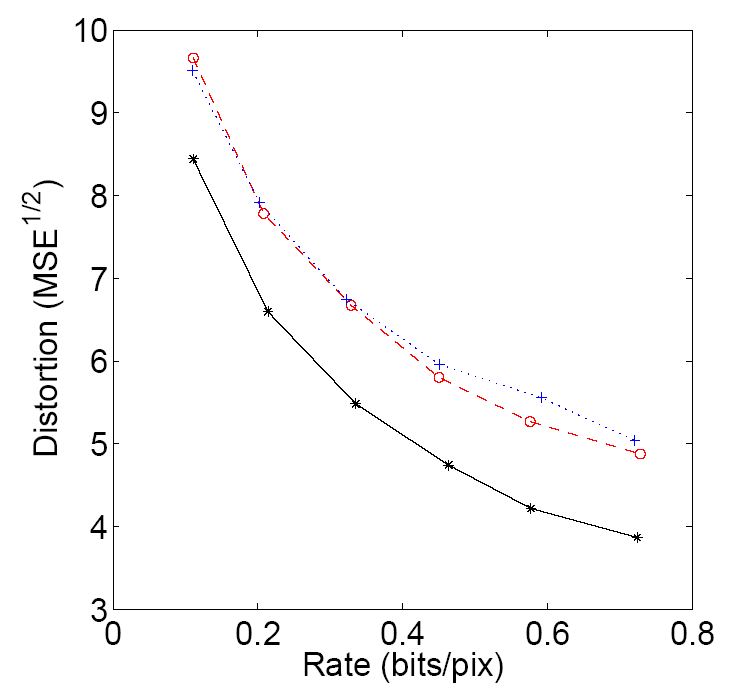
The new standard JPEG2000 [Taubman02] uses wavelets in the first linear stage; and it incorporates more complex expressions, yet not exact , for the non-linear perceptual stage [Daly02]. In particular, in addition of the simplest linear model (the CSF), it allows point-wise non-linearities and simplified versions of the divisive normalization. The major problem found in using the most accurate version of divisive normalization is the mathematical complexity of its inversion. This is why the standard just uses simplified versions of the non-linearity. In [ Navarro05 ] we improved the performance of JPEG2000 by using the perceptual non-linearities as well. We extended to wavelets the robust and fast algorithm to invert the exact expression of divisive normalization that was derived and used in the DCT context [Malo06a ]. In this way, significant improvements in rate-distortion performance and better color reproduction than in JPEG2000 have been found (see the example below 0.2 bits/pix).
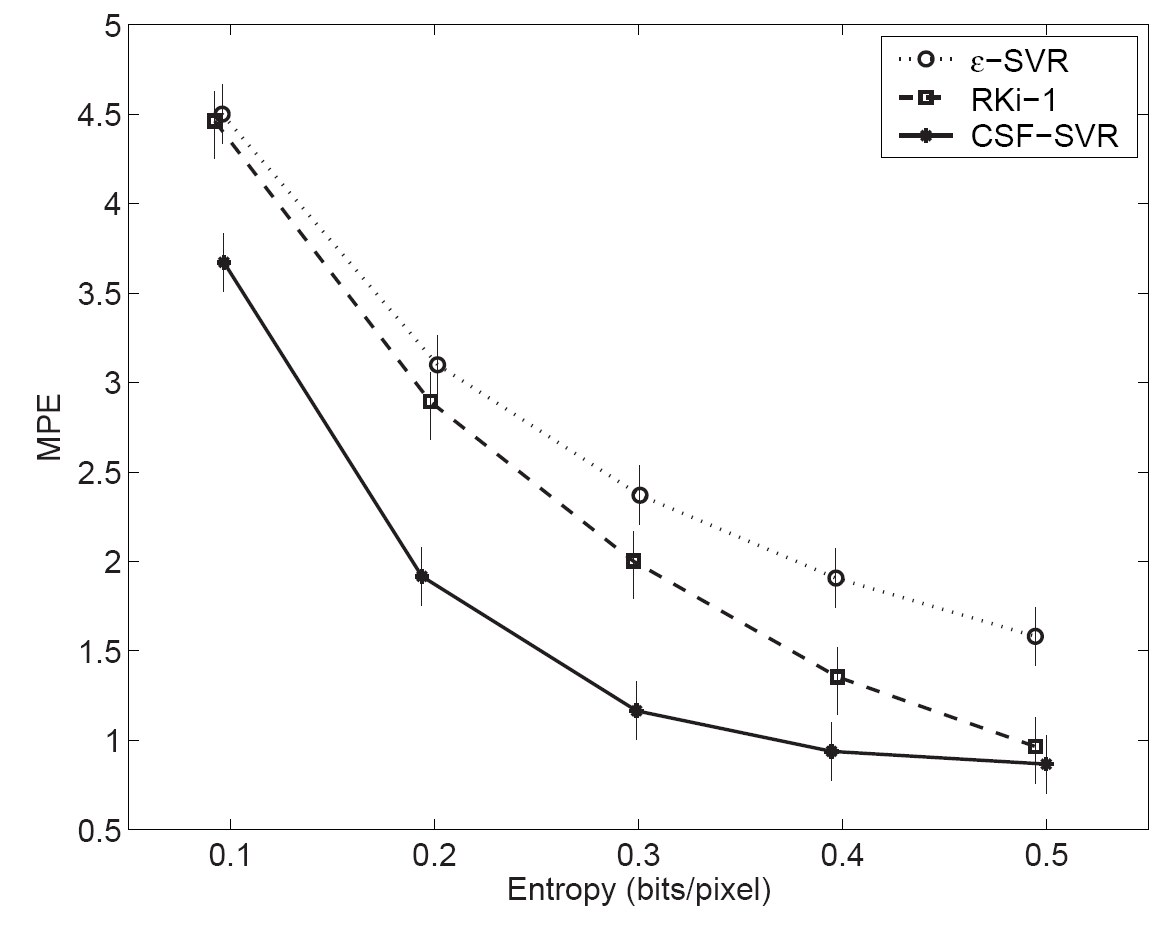
Due to our colaboration with Dr. Gustavo Camps (Dept. d'Eng. Electr. Universitat de Valencia) we are applied a different kind of non-linear processing after the linear transform representation. In particular, we trained perceptually weighted Support Vector Machines (SVMs) to select the subset of more relevant coefficients in the linear representation. SVM learning has been recently proposed for image compression in the frequency domain using a constant insensitivity zone by Robinson and Kecman [Rob&Kec03]. However, according to the statistical properties of natural images and the properties of human perception (the Barlow hypothesis again!), a constant insensitivity makes sense in the spatial domain but it is certainly not a good option in a frequency domain. In fact, in their approach they made a fixed low-pass ad-hoc assumption: they neglected high-frequency coefficients in the SVM training. In [ Gomez04 ] we have proposed the use of adaptive insensitivity SVMs [Camps01] for image coding using an appropriate distortion criterion [ Malo95 -Malo06a ] based on a simple visual cortex model. Training the SVM by using an accurate perception model avoids any a priori assumption and reduces the blocking effect and improves the subjective rate-distortion performance of the original approach. Our results compared to the
results using straightforward SVMs in the DCT domain and with the
method proposed in [Rob&Kec03] are shown below (0.3 bits/pix). Even
better results are obtained when operating in non-linearly transformed
domains [
Gutiérrez07
, Camps08]. We have recently
extended these results to work with color images [Malo08].
PUBLICATIONS
|
|
|
|
IMAGE RESTORATION
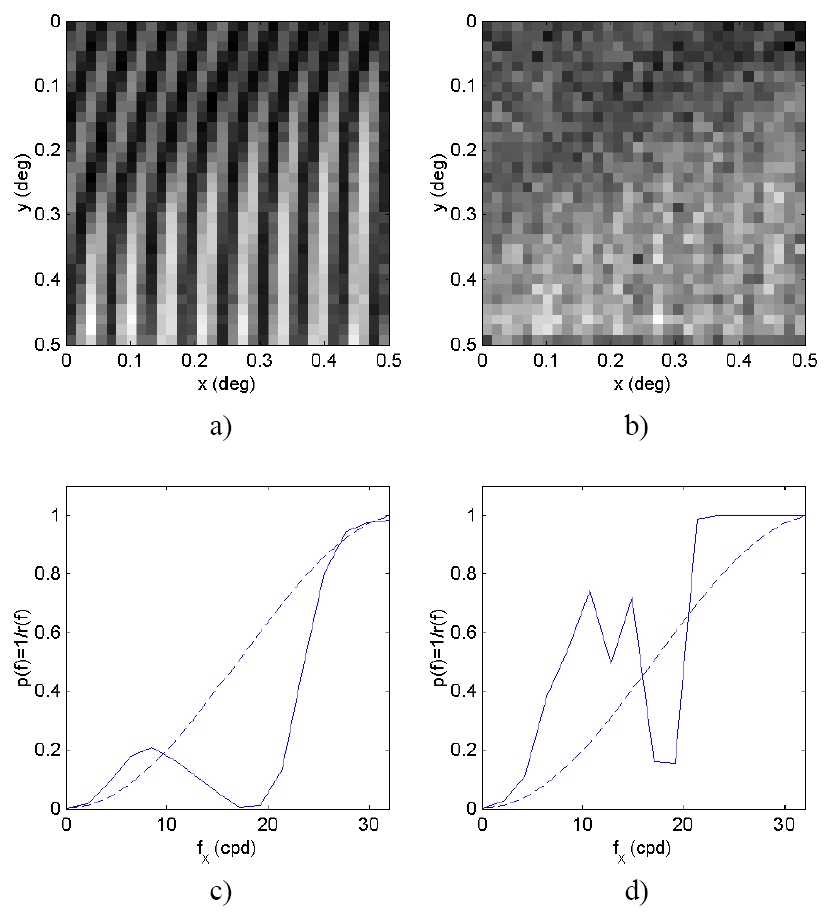
Perceptual Image Restoration. Image restoration requires a priori knowledge on the solution. The key idea behind conventional regularization techniques is smoothness. Smoothness means predictability of the signal from the neighborhood, therefore, the conventional approaches use simple statistical models such as band-limitation or autorregresive (AR) models of the signal. However, natural images exhibit additional features, such as particular relations between local Fourier or wavelet transform coefficients. Biological visual systems have evolved to capture these relations (as assumed by the Barlow hypothesis ). We have proposed to use this biological behavior in regularization as an alternative to smoothness-based functionals [Gutierrez03 , Gutierrez06 ]. In particular, we have shown that the use of the human visual non-linear response in local frequency domains to design the penalty functional in regularization identifies the relevant features of the images. In this way, these features are discriminated from noise and preserved in the restoration process. An illustration of how the perceptual penalty functional identifies the presence of a relevant feature, consider this patch of the Barbara image that contains relevant information around 18 cycles/deg. Figures (a) and (b) show the original and degraded (blurred and noisy) versions of the patch. Figures (c) and (d), show the penalty functionals computed from these images using the proposed method (solid lines). The classical 2nd derivative functional [Katsaggelos02] (dashed lines) is shown for reference purposes. Note how the proposed functional captures (and hence preserves!) the relevant feature even though it is almost invisible after the degradation process.
The examples below show the performance of the proposed regularization functionals compared with other stationary (2nd derivarive and CSF) and adaptive (AR and Adaptive Wiener) regularization methods in synthetically degraded and naturally degraded images. In every case, no prior information about the nature of the noise or the blurring process is assumed. Therefore, the performance of the methods fully depends on the suitability of the underlying assumptions on the nature of the image in each case. Synthetically degraded images were generated by low-pass filtering the original (using a certain cut-off frequency, fc ) and using additive gaussian white noise of certain variance, s. Playing with fc and s, we considered all the possibilities between deblurring and denoising. (almost) Deblurring: fc = 3 cpd, s 2 = 15
(almost) Denoising: fc = 27 cpd, s 2 = 200
Naturally degraded images were obtained taking pictures of a given scene in poor lightning conditions. The example below shows that the proposed method works better than classical methods (such as [Lee80]) because it focuses in removing the (real) degradation: note how the Wiener method identifies as noise relevant features of the image such as edges. Naturally degraded images
Image Restoration
with Kernels in the Wavelet domain. [ Laparra08 , Laparra10b ] We propose
an alternative non-explicit way to take into account the relations
among
natural image wavelet coefficients for denoising: we use support vector
regression
(SVR) in the wavelet domain to enforce these relations in the estimated
signal.
Since relations among the coefficients are specific to the signal, the
regularization
property of SVR is exploited to remove the noise, which does not share
this
feature. The specific signal relations are encoded in an anisotropic
kernel
obtained from mutual information measures computed on a representative
image
database. In the proposed scheme, training considers minimizing the
Kullback-Leibler
divergence (KLD) between the estimated and actual probability functions
(or
histograms) of signal and noise in order to enforce similarity up to
the
higher (computationally estimable) order. Due to its non-parametric
nature,
the method can eventually cope with different noise sources without the
need
of an explicit re-formulation, as it is strictly necessary under
parametric
Bayesian formalisms.Image
restoration requires a priori knowledge on the solution.
|
|
|
|