|
|
AGRUPACIÓN DE LOS MUNICIPIOS EN CONGLOMERADOS HOMOGÉNEOS
.
ANÁLISIS CLUSTER.
Uno de los objetivos básicos de los dos análisis de configuración interna del A.M. de Valencia es el detectar conglomerados homogéneos de municipios que mantengan sus características de forma similar y que se diferencien claramente del resto . Este objetivo , se consigue a la perfección a través de los métodos de análisis cluster o grupos de individuos de características semejantes . Veamos cuales son las notas fundamentales de estos métodos.
En esencia se trata de resolver el siguiente problema:
Dado un conjunto de N individuos caracterizados por la información de las
n variables ![]() (
j=1,2,3,….n) nos planteamos el reto de ser capaces de clasificarlos de manera
que los individuos pertenecientes a un grupo (cluster) ( y siempre respecto a la
información disponible) sean tan similares entre sí como sea posible , siendo
los distintos grupos entre ellos tan disimilares como sea posible .
(
j=1,2,3,….n) nos planteamos el reto de ser capaces de clasificarlos de manera
que los individuos pertenecientes a un grupo (cluster) ( y siempre respecto a la
información disponible) sean tan similares entre sí como sea posible , siendo
los distintos grupos entre ellos tan disimilares como sea posible .
El proceso completo puede estructurarse de acuerdo con el siguiente esquema .
■Partimos de un conjunto de N individuos de los que se dispone información cifrada por un conjunto de n variables ( una matriz de n x m )
■Establecemos algún criterio de similaridad para poder determinar :
■Una matriz de similaridades que nos permita relacionar la semejanza de los individuos (municipios) entre sí ( matriz n x n).
■Escogemos un algoritmo de clasificación para determinar la estructura de la agrupación , lo que implica de paso , haber escogido algún criterio de disimilaridad entre individuos y grupos y entre grupos.
■Especificamos esa estructura mediante diagramas arbóreos o dendográmas u otros gráficos .
En nuestro trabajo el criterio de similaridad empleado será un criterio tipo distancia .Por tanto se tratará de un criterio de disimilaridad .La distancia interindividual empleada será , por lo general la distancia euclídea , que aún presentando menos ventaja que otras ( la de Mahalanobis) , por ejemplo , evita ciertos problemas de computación y resolución informática con el paquete estadístico utilizado (spss).
Si presentamos a los individuos (distintos municipios) i , j por los valores que toman las n variables , cada individuo será un punto del espacio n- dimensional de las variables y la distancia euclídea quedará definida de la manera habitual . En efecto , sean las representaciones de los individuos i, j :
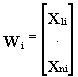
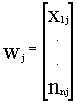
la distancia euclídea entre ambos
vendrá dada por
![]()
esta distancia , que será la que utilizaremos presenta dos inconvenientes , la dependencia de las unidades de medida de las variables utilizadas y el hecho de no ser capaz de eliminar la redundancia propia de las variables altamente correlacionadas . Este hecho puede corregirse a través de la distancia de Mahalanobis que utiliza como matriz asociada a la forma cuadrática la inversa de la matriz de varianzas , evitando así ambos inconvenientes
En cuanto a los algoritmos que utilizaremos , éstos serán siempre jerárquicos , esto es , nos irán ofreciendo distintos niveles de agrupación partiendo de la máxima desagregación ( cada individuo es un grupo, cada municipio es un cluster) hasta la fusión total . Para llevarlos a cabo en la práctica utilizaremos , básicamente dos métodos de agrupación : el método de la media (u.p.g.m.a) y el método de Ward ( en general preferible)
En ambos métodos se parte de considerar inicialmente todos los individuos como grupos . En primer lugar se considera los dos grupos más similares ( con menor distancia entre ellos ) y se obtiene así una partición de un elemento menos . El proceso continua de esta manera , hasta que todos los individuos queden agrupados en un solo grupo.
Lo que caracteriza cada método es la distancia empleada para determinar la similaridad entre grupos de más de un individuo:
En el método de la media , la distancia entre individuo y un grupo es el valor medio de todas las distancias entre el individuo y todos los miembros del grupo. Igualmente la distancia entre todos dos grupos queda definida como la media de todas las distancias entre todos sus individuos constituyentes . Este método tiene considerables ventajas sobre otros , conservando , intacta , la métrica inicial.
El método de Ward , opera de una manera distinta , considerando en cada pasa del proceso todas las posibilidades de fusión de grupos y optando en cada paso por la fusión de aquellos dos que menos incrementen la suma de los cuadrados de las desviaciones al unirse.
volver a fases del análisis estructural

