x <- 3.14
x[1] 3.14class(x)[1] "numeric"R es un potente lenguaje de programación y entorno de desarrollo estadístico diseñado para el análisis de datos y la creación de visualizaciones. Es ampliamente utilizado en la comunidad científica, académica e industrial para realizar tareas estadísticas y análisis de datos de manera eficiente. Para aprovechar al máximo las capacidades de R y facilitar su uso, se recomienda instalar dos programas esenciales: R y RStudio.
La instalación de R proporciona el motor subyacente que ejecuta los comandos y scripts en R (más adelante hablaremos en profundidad de esto). Este lenguaje es la base de todo el proceso analítico. Sin embargo, para una experiencia de programación más fluida, eficiente y amigable, se instala RStudio. RStudio actúa como un entorno de desarrollo integrado (IDE), ofreciendo una interfaz gráfica que simplifica la escritura, ejecución y depuración del código en R. La combinación de ambos programas proporciona una plataforma completa y poderosa para la exploración y análisis de datos, convirtiendo el proceso en una experiencia más accesible y productiva para aquellos que se embarcan en el mundo del análisis de datos con R.
El proceso de instalación de R es sencillo y comienza visitando el sitio oficial de R en el Comprehensive R Archive Network (CRAN) en https://cran.r-project.org/. En esta página, podemos seleccionar la opción de descarga correspondiente al sistema operativo que estemos utilizando, ya sea Windows, macOS o Linux.

Si seleccionamos Windows (lo más habitual), el navegador web nos mostrará una nueva pantalla, en la que deberemos seleccionar base.
En la nueva pantalla encontraremos el enlace para descargar la última versión de R. Hacemos clic sobre el link y procedemos a su descarga.
Una vez descargado, ejecutamos el instalador. Dejamos todas las opciones por defecto y finalizamos la instalación.
Cómo ya se ha comentado en la introducción, podríamos trabajar solo con el software de R. No obstante, lo habitual es también instalar RStudio, ya que tiene una interfaz mucho más amigable. Lo podemos descargar de https://posit.co/download/rstudio-desktop/.
Desde la propia página de RStudio nos recuerdan que antes de instalar RStudio debemos instalar R. Puesto que la primera parte del proceso ya la hemos completado, procedemos ahora a la descarga de RStudio:
Una vez hayamos descargado el instalador correspondiente a nuestro sistema operativo, instalamos la aplicación, aceptando las diversas pantallas que ofrece el asistente y dejando nuevamente todas las opciones por defecto.
Con la instalación exitosa de R y RStudio, estamos en disposición de iniciar el taller.
Puesto que el taller es eminentemente práctico, estaremos prácticamente toda la sesión “trasteando” con R y RStudio. No obstante, es interesante que algunos conceptos básicos queden por escrito, para poder consultarlos/repasarlos en el futuro…
En R, hay varios tipos de variables que se utilizan para almacenar diferentes tipos de datos. Estos son algunos de los tipos de variables más comunes en R:
x <- 3.14
x[1] 3.14class(x)[1] "numeric"y <- 42L
y[1] 42class(y)[1] "integer"En R se utiliza la letra “L” para especificar que ese número es entero.
nombre <- "Juan"
nombre[1] "Juan"class(nombre)[1] "character"#nombre <- JuanTRUE o FALSEverdadero <- TRUE
verdadero[1] TRUEclass(verdadero)[1] "logical"k <- F
class(k)[1] "logical"5 > 3[1] TRUE5 == 3[1] FALSEfecha <- as.Date("2023-01-01")
fecha[1] "2023-01-01"class(fecha)[1] "Date"fecha2 <- as.Date("18/05/06")
fecha2[1] "0018-05-06"fecha3 <- as.Date("18/05/74")fecha4 <- as.Date("18/05/74", "%d/%m/%y")
fecha4[1] "1974-05-18"Sys.Date()[1] "2026-05-12"fecha_hora <- as.POSIXct("2023-01-01 12:34:56")
fecha_hora[1] "2023-01-01 12:34:56 CET"Sys.time()[1] "2026-05-12 12:07:10 CEST"En R, hay varios tipos de objetos que se utilizan para almacenar y organizar datos. Estos son los más comunes:
Secuencia ordenada de elementos del mismo tipo, por ejemplo:
vector1 <- c(1, 2, 3, 4)
vector1[1] 1 2 3 4class(vector1)[1] "numeric"vector2 <- c(1L, 2L, 3L, 4L)
vector2[1] 1 2 3 4class(vector2)[1] "integer"vector3 <- c("1", "2", "3")
vector3[1] "1" "2" "3"class(vector3)[1] "character"vector4 <- c(1, 2L, "3")
vector4[1] "1" "2" "3"class(vector4)[1] "character"vector5 <- c(1, "2", TRUE)
vector5[1] "1" "2" "TRUE"class(vector5)[1] "character"Estructura bidimensional que contiene elementos del mismo tipo, por ejemplo:
mat1 <- matrix(c(1,2,3,4), nrow = 2)
mat1 [,1] [,2]
[1,] 1 3
[2,] 2 4mat2 <- matrix(1:9, ncol = 3)
mat2 [,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 91:10 [1] 1 2 3 4 5 6 7 8 9 10seq(from=1, to=10, by=1) [1] 1 2 3 4 5 6 7 8 9 10seq(1,10,1) [1] 1 2 3 4 5 6 7 8 9 10seq(0,50,5) [1] 0 5 10 15 20 25 30 35 40 45 50seq(0,100,0.25) [1] 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00
[10] 2.25 2.50 2.75 3.00 3.25 3.50 3.75 4.00 4.25
[19] 4.50 4.75 5.00 5.25 5.50 5.75 6.00 6.25 6.50
[28] 6.75 7.00 7.25 7.50 7.75 8.00 8.25 8.50 8.75
[37] 9.00 9.25 9.50 9.75 10.00 10.25 10.50 10.75 11.00
[46] 11.25 11.50 11.75 12.00 12.25 12.50 12.75 13.00 13.25
[55] 13.50 13.75 14.00 14.25 14.50 14.75 15.00 15.25 15.50
[64] 15.75 16.00 16.25 16.50 16.75 17.00 17.25 17.50 17.75
[73] 18.00 18.25 18.50 18.75 19.00 19.25 19.50 19.75 20.00
[82] 20.25 20.50 20.75 21.00 21.25 21.50 21.75 22.00 22.25
[91] 22.50 22.75 23.00 23.25 23.50 23.75 24.00 24.25 24.50
[100] 24.75 25.00 25.25 25.50 25.75 26.00 26.25 26.50 26.75
[109] 27.00 27.25 27.50 27.75 28.00 28.25 28.50 28.75 29.00
[118] 29.25 29.50 29.75 30.00 30.25 30.50 30.75 31.00 31.25
[127] 31.50 31.75 32.00 32.25 32.50 32.75 33.00 33.25 33.50
[136] 33.75 34.00 34.25 34.50 34.75 35.00 35.25 35.50 35.75
[145] 36.00 36.25 36.50 36.75 37.00 37.25 37.50 37.75 38.00
[154] 38.25 38.50 38.75 39.00 39.25 39.50 39.75 40.00 40.25
[163] 40.50 40.75 41.00 41.25 41.50 41.75 42.00 42.25 42.50
[172] 42.75 43.00 43.25 43.50 43.75 44.00 44.25 44.50 44.75
[181] 45.00 45.25 45.50 45.75 46.00 46.25 46.50 46.75 47.00
[190] 47.25 47.50 47.75 48.00 48.25 48.50 48.75 49.00 49.25
[199] 49.50 49.75 50.00 50.25 50.50 50.75 51.00 51.25 51.50
[208] 51.75 52.00 52.25 52.50 52.75 53.00 53.25 53.50 53.75
[217] 54.00 54.25 54.50 54.75 55.00 55.25 55.50 55.75 56.00
[226] 56.25 56.50 56.75 57.00 57.25 57.50 57.75 58.00 58.25
[235] 58.50 58.75 59.00 59.25 59.50 59.75 60.00 60.25 60.50
[244] 60.75 61.00 61.25 61.50 61.75 62.00 62.25 62.50 62.75
[253] 63.00 63.25 63.50 63.75 64.00 64.25 64.50 64.75 65.00
[262] 65.25 65.50 65.75 66.00 66.25 66.50 66.75 67.00 67.25
[271] 67.50 67.75 68.00 68.25 68.50 68.75 69.00 69.25 69.50
[280] 69.75 70.00 70.25 70.50 70.75 71.00 71.25 71.50 71.75
[289] 72.00 72.25 72.50 72.75 73.00 73.25 73.50 73.75 74.00
[298] 74.25 74.50 74.75 75.00 75.25 75.50 75.75 76.00 76.25
[307] 76.50 76.75 77.00 77.25 77.50 77.75 78.00 78.25 78.50
[316] 78.75 79.00 79.25 79.50 79.75 80.00 80.25 80.50 80.75
[325] 81.00 81.25 81.50 81.75 82.00 82.25 82.50 82.75 83.00
[334] 83.25 83.50 83.75 84.00 84.25 84.50 84.75 85.00 85.25
[343] 85.50 85.75 86.00 86.25 86.50 86.75 87.00 87.25 87.50
[352] 87.75 88.00 88.25 88.50 88.75 89.00 89.25 89.50 89.75
[361] 90.00 90.25 90.50 90.75 91.00 91.25 91.50 91.75 92.00
[370] 92.25 92.50 92.75 93.00 93.25 93.50 93.75 94.00 94.25
[379] 94.50 94.75 95.00 95.25 95.50 95.75 96.00 96.25 96.50
[388] 96.75 97.00 97.25 97.50 97.75 98.00 98.25 98.50 98.75
[397] 99.00 99.25 99.50 99.75 100.00rep(2,5)[1] 2 2 2 2 2rep("Hola", 7)[1] "Hola" "Hola" "Hola" "Hola" "Hola" "Hola" "Hola"paste0("Hola", seq(1,5,1))[1] "Hola1" "Hola2" "Hola3" "Hola4" "Hola5"paste("Hola", seq(1,10,2), sep = "_")[1] "Hola_1" "Hola_3" "Hola_5" "Hola_7" "Hola_9"rep(paste("Hola", seq(1,10,2), sep = "_"), 5) [1] "Hola_1" "Hola_3" "Hola_5" "Hola_7" "Hola_9" "Hola_1" "Hola_3"
[8] "Hola_5" "Hola_7" "Hola_9" "Hola_1" "Hola_3" "Hola_5" "Hola_7"
[15] "Hola_9" "Hola_1" "Hola_3" "Hola_5" "Hola_7" "Hola_9" "Hola_1"
[22] "Hola_3" "Hola_5" "Hola_7" "Hola_9"palabras <- paste("Hola", seq(1,10,2), sep = "_")
rep(palabras,5) [1] "Hola_1" "Hola_3" "Hola_5" "Hola_7" "Hola_9" "Hola_1" "Hola_3"
[8] "Hola_5" "Hola_7" "Hola_9" "Hola_1" "Hola_3" "Hola_5" "Hola_7"
[15] "Hola_9" "Hola_1" "Hola_3" "Hola_5" "Hola_7" "Hola_9" "Hola_1"
[22] "Hola_3" "Hola_5" "Hola_7" "Hola_9"Similar a una matriz, pero puede contener columnas de diferentes tipos, por ejemplo:
df <- data.frame(nombre = c("Juan", "María"), edad = c(25, 30))
df nombre edad
1 Juan 25
2 María 30View(df)
colnames(df)[1] "nombre" "edad" colnames(df)[1][1] "nombre"colnames(df)[2][1] "edad"colnames(df) <- c("Nombre", "Edad")
colnames(df)[1] <- "NOMBRE"
colnames(df)[2] <- "EDAD"
df NOMBRE EDAD
1 Juan 25
2 María 30Colección ordenada y mutable de elementos que pueden ser de diferentes tipos, por ejemplo:
lista <- list(1L, "dos", c(3, 4))
lista[[1]]
[1] 1
[[2]]
[1] "dos"
[[3]]
[1] 3 4class(lista[[1]])[1] "integer"class(lista[[2]])[1] "character"class(lista[[3]])[1] "numeric"View(lista)Representa variables categóricas con niveles predefinidos. Es útil en estadísticas y modelado. Por ejemplo:
fact1 <- factor(c("ALI", "CAS", "VAL"))
fact1[1] ALI CAS VAL
Levels: ALI CAS VALclass(fact1)[1] "factor"fact2 <- factor(c("ALI", "CAS", "VAL"),
levels = c("VAL", "ALI", "CAS"),
labels = c("Valencia", "Alicante", "Castellón"))
fact2[1] Alicante Castellón Valencia
Levels: Valencia Alicante Castellónclass(fact2)[1] "factor"Matrices de más de dos dimensiones, por ejemplo:
arr1 <- array(c(1, 2, 3, 4), dim = c(2, 2, 1))
arr1, , 1
[,1] [,2]
[1,] 1 3
[2,] 2 4class(arr1)[1] "array"arr2 <- array(1:18, dim = c(3, 3, 2))
arr2, , 1
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
, , 2
[,1] [,2] [,3]
[1,] 10 13 16
[2,] 11 14 17
[3,] 12 15 18class(arr2)[1] "array"arr3 <- array(1:75, dim = c(5, 5, 3))
arr3, , 1
[,1] [,2] [,3] [,4] [,5]
[1,] 1 6 11 16 21
[2,] 2 7 12 17 22
[3,] 3 8 13 18 23
[4,] 4 9 14 19 24
[5,] 5 10 15 20 25
, , 2
[,1] [,2] [,3] [,4] [,5]
[1,] 26 31 36 41 46
[2,] 27 32 37 42 47
[3,] 28 33 38 43 48
[4,] 29 34 39 44 49
[5,] 30 35 40 45 50
, , 3
[,1] [,2] [,3] [,4] [,5]
[1,] 51 56 61 66 71
[2,] 52 57 62 67 72
[3,] 53 58 63 68 73
[4,] 54 59 64 69 74
[5,] 55 60 65 70 75class(arr3)[1] "array"Lista donde los elementos pueden ser listas, permitiendo estructuras de datos anidadas, por ejemplo:
lista_de_listas <- list(list(1, 2), list("a", "b"))
lista_de_listas[[1]]
[[1]][[1]]
[1] 1
[[1]][[2]]
[1] 2
[[2]]
[[2]][[1]]
[1] "a"
[[2]][[2]]
[1] "b"class(lista_de_listas[[1]])[1] "list"class(lista_de_listas[[2]])[1] "list"class(lista_de_listas[[1]][[1]])[1] "numeric"class(lista_de_listas[[1]][[2]])[1] "numeric"class(lista_de_listas[[2]][[1]])[1] "character"class(lista_de_listas[[2]][[2]])[1] "character"Estos son solo algunos de los tipos de objetos que se utilizan comúnmente en R. La elección del tipo de objeto depende de la estructura y naturaleza de los datos que estás manejando, así como de las operaciones que planeas realizar sobre ellos.
x + y equivale a sum(x,y)
5+3[1] 8sum(5,3)[1] 8sum(5,"3")sum(2*10,3)[1] 23sum(seq(1:5))[1] 15x - y
9-7[1] 2x * y equivale a prod(x,y)
5*3[1] 15prod(5,3)[1] 15x / y
15/3[1] 515%%3[1] 015%%4[1] 3x ^ y
5^2[1] 25Raíz cuadrada
sqrt(x)
sqrt(16)[1] 4log(x)
log(10)[1] 2.302585exp(1)^log(10)[1] 10log10(10)[1] 1?log
log(10, base = 10)[1] 1mean(x)median(x)sd(x)var(x)min(x)max(x)quantile(x, probs(0.25, 0.5, 0.75))cor(x,y)lm(y ~ x)mean(c(2,3,4))[1] 3median(c(1,2,3,4,5000))[1] 3sd(c(100,200,300))[1] 100var(c(100,200,300))[1] 10000min(c(2,5,9,3,1,12))[1] 1max(c(2,5,9,3,1,12))[1] 12quantile(c(2,5,9,3,1,12)) 0% 25% 50% 75% 100%
1.00 2.25 4.00 8.00 12.00 altura <- c(158,164,210,185,177)
peso <- c(56,63,145,87,83)
cor(altura,peso)[1] 0.9839499modelo <- lm(peso~altura)
summary(modelo)
Call:
lm(formula = peso ~ altura)
Residuals:
1 2 3 4 5
4.3509 1.2112 5.4737 -10.2777 -0.7581
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -215.3621 31.8026 -6.772 0.00658 **
altura 1.6899 0.1769 9.551 0.00244 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.224 on 3 degrees of freedom
Multiple R-squared: 0.9682, Adjusted R-squared: 0.9575
F-statistic: 91.21 on 1 and 3 DF, p-value: 0.002435
La comunidad R ha desarrollado numerosos paquetes (librerías) que extienden la funcionalidad base del lenguaje, cubriendo una amplia gama de aplicaciones. Como se ha comentado anteriormente, CRAN es el repositorio oficial de paquetes de R, pero también existe la posibilidad de instalar librerías externas, alojadas en GitHub o GitLab, por ejemplo.
Algunos de los paquetes más utilizados, disponibles en CRAN, son:
dplyr(Wickham et al., 2026) proporciona un conjunto consistente de verbos para manipulación y transformación de datos, facilitando tareas como filtrado, selección, agrupación y unión de conjuntos de datos.

ggplot2(Wickham, 2016) implementa la filosofía de la Grammar of Graphics, proporcionando un sistema de gráficos declarativo que permite crear visualizaciones complejas y altamente personalizables mediante una sintaxis clara, coherente y estructurada.
Paquete orientado a la organización y reestructuración de datos, especialmente útil para convertir datos entre formatos “anchos” (wide) y “largos” (long), así como para manejar valores faltantes y separar o unir columnas. tidyr(Wickham, Vaughan, et al., 2025) se basa en el principio de los tidy data, donde cada variable ocupa una columna y cada observación una fila.

stringr(Wickham, 2025) proporciona un conjunto coherente y sencillo de funciones para trabajar con cadenas de texto (strings). Facilita tareas como búsqueda de patrones, reemplazo, extracción de texto y manipulación de caracteres utilizando expresiones regulares de manera más intuitiva.

readr(Wickham, Hester, et al., 2025) permite optimizar la importación y exportación de datos tabulares. Permite leer archivos CSV, TXT o TSV de forma rápida y eficiente, ofreciendo además un mejor tratamiento de tipos de datos y mensajes de error más claros que las funciones base de R.

purrr(Wickham y Henry, 2026) introduce herramientas de programación funcional en R, facilitando la aplicación de funciones sobre listas y vectores mediante una sintaxis consistente y legible. Es especialmente útil para automatizar procesos repetitivos y evitar bucles explícitos.

lubridate(Grolemund y Wickham, 2011) es un paquete especializado en el manejo de fechas y horas. Simplifica la conversión, extracción y manipulación de componentes temporales, permitiendo trabajar con calendarios y formatos de fecha de manera más intuitiva.

Muchas de estas librerías forman parte del ecosistema tidyverse(Wickham et al., 2019), una colección integrada de paquetes diseñados para compartir una filosofía común, una sintaxis coherente y estructuras de datos compatibles, facilitando así el flujo completo de análisis y visualización de datos en R.
El análisis exploratorio de datos (Exploratory Data Analysis o EDA) constituye una etapa fundamental en cualquier proceso de análisis, ya que permite comprender la estructura, calidad y características principales de un conjunto de datos antes de aplicar modelos o técnicas estadísticas más avanzadas. En este apartado se presentarán algunas de las funciones más utilizadas de los paquetes dplyr, tidyr y ggplot2, orientadas a la transformación, limpieza y visualización de datos de forma eficiente y reproducible.
Cargamos librerías:
library(dplyr)
library(ggplot2)
library(tidyr)
library(tidyverse)dplyrPara conocer las funciones más habituales de dplyr, crearemos un dataset sencillo:
ayudas <- data.frame(
expediente = paste0("EXP",1:12),
provincia = c("València", "Alacant", "Castelló", "València", "Alacant", "Castelló",
"València", "Alacant", "Castelló", "València", "Alacant", "Castelló"),
programa = c("Empleo", "Vivienda", "Educación", "Empleo", "Vivienda", "Sanidad",
"Educación", "Sanidad", "Empleo", "Vivienda", "Educación", "Sanidad"),
importe = c(1200, 3000, 1500, 1800, 2500, 4000, 1600, 3800, 1400, 3200, 1700, 4100),
beneficiarios = c(10, 5, 20, 12, 6, 30, 22, 28, 11, 7, 24, 35),
año = c(2022, 2022, 2022, 2023, 2023, 2023, 2024, 2024, 2024, 2024, 2024, 2024)
)glimpse(ayudas)Rows: 12
Columns: 6
$ expediente <chr> "EXP1", "EXP2", "EXP3", "EXP4", "EXP5", "EXP…
$ provincia <chr> "València", "Alacant", "Castelló", "València…
$ programa <chr> "Empleo", "Vivienda", "Educación", "Empleo",…
$ importe <dbl> 1200, 3000, 1500, 1800, 2500, 4000, 1600, 38…
$ beneficiarios <dbl> 10, 5, 20, 12, 6, 30, 22, 28, 11, 7, 24, 35
$ año <dbl> 2022, 2022, 2022, 2023, 2023, 2023, 2024, 20…head(ayudas) expediente provincia programa importe beneficiarios año
1 EXP1 València Empleo 1200 10 2022
2 EXP2 Alacant Vivienda 3000 5 2022
3 EXP3 Castelló Educación 1500 20 2022
4 EXP4 València Empleo 1800 12 2023
5 EXP5 Alacant Vivienda 2500 6 2023
6 EXP6 Castelló Sanidad 4000 30 2023colnames(ayudas)[1] "expediente" "provincia" "programa" "importe"
[5] "beneficiarios" "año" nrow(ayudas)[1] 12summary(ayudas) expediente provincia programa
Length:12 Length:12 Length:12
Class :character Class :character Class :character
Mode :character Mode :character Mode :character
importe beneficiarios año
Min. :1200 Min. : 5.00 Min. :2022
1st Qu.:1575 1st Qu.: 9.25 1st Qu.:2023
Median :2150 Median :16.00 Median :2024
Mean :2483 Mean :17.50 Mean :2023
3rd Qu.:3350 3rd Qu.:25.00 3rd Qu.:2024
Max. :4100 Max. :35.00 Max. :2024 select()ayudas %>%
select(provincia, programa, importe) provincia programa importe
1 València Empleo 1200
2 Alacant Vivienda 3000
3 Castelló Educación 1500
4 València Empleo 1800
5 Alacant Vivienda 2500
6 Castelló Sanidad 4000
7 València Educación 1600
8 Alacant Sanidad 3800
9 Castelló Empleo 1400
10 València Vivienda 3200
11 Alacant Educación 1700
12 Castelló Sanidad 4100ayudas %>%
select(-expediente) provincia programa importe beneficiarios año
1 València Empleo 1200 10 2022
2 Alacant Vivienda 3000 5 2022
3 Castelló Educación 1500 20 2022
4 València Empleo 1800 12 2023
5 Alacant Vivienda 2500 6 2023
6 Castelló Sanidad 4000 30 2023
7 València Educación 1600 22 2024
8 Alacant Sanidad 3800 28 2024
9 Castelló Empleo 1400 11 2024
10 València Vivienda 3200 7 2024
11 Alacant Educación 1700 24 2024
12 Castelló Sanidad 4100 35 2024ayudas %>%
select(expediente, starts_with("benef")) expediente beneficiarios
1 EXP1 10
2 EXP2 5
3 EXP3 20
4 EXP4 12
5 EXP5 6
6 EXP6 30
7 EXP7 22
8 EXP8 28
9 EXP9 11
10 EXP10 7
11 EXP11 24
12 EXP12 35filter()ayudas %>%
filter(provincia == "València") expediente provincia programa importe beneficiarios año
1 EXP1 València Empleo 1200 10 2022
2 EXP4 València Empleo 1800 12 2023
3 EXP7 València Educación 1600 22 2024
4 EXP10 València Vivienda 3200 7 2024ayudas %>%
filter(año == 2024) expediente provincia programa importe beneficiarios año
1 EXP7 València Educación 1600 22 2024
2 EXP8 Alacant Sanidad 3800 28 2024
3 EXP9 Castelló Empleo 1400 11 2024
4 EXP10 València Vivienda 3200 7 2024
5 EXP11 Alacant Educación 1700 24 2024
6 EXP12 Castelló Sanidad 4100 35 2024ayudas %>%
filter(importe > 3000) expediente provincia programa importe beneficiarios año
1 EXP6 Castelló Sanidad 4000 30 2023
2 EXP8 Alacant Sanidad 3800 28 2024
3 EXP10 València Vivienda 3200 7 2024
4 EXP12 Castelló Sanidad 4100 35 2024ayudas %>%
filter(provincia == "Alacant", año >= 2023) expediente provincia programa importe beneficiarios año
1 EXP5 Alacant Vivienda 2500 6 2023
2 EXP8 Alacant Sanidad 3800 28 2024
3 EXP11 Alacant Educación 1700 24 2024ayudas %>%
filter(programa %in% c("Sanidad", "Educación")) expediente provincia programa importe beneficiarios año
1 EXP3 Castelló Educación 1500 20 2022
2 EXP6 Castelló Sanidad 4000 30 2023
3 EXP7 València Educación 1600 22 2024
4 EXP8 Alacant Sanidad 3800 28 2024
5 EXP11 Alacant Educación 1700 24 2024
6 EXP12 Castelló Sanidad 4100 35 2024arrange()ayudas %>%
arrange(importe) expediente provincia programa importe beneficiarios año
1 EXP1 València Empleo 1200 10 2022
2 EXP9 Castelló Empleo 1400 11 2024
3 EXP3 Castelló Educación 1500 20 2022
4 EXP7 València Educación 1600 22 2024
5 EXP11 Alacant Educación 1700 24 2024
6 EXP4 València Empleo 1800 12 2023
7 EXP5 Alacant Vivienda 2500 6 2023
8 EXP2 Alacant Vivienda 3000 5 2022
9 EXP10 València Vivienda 3200 7 2024
10 EXP8 Alacant Sanidad 3800 28 2024
11 EXP6 Castelló Sanidad 4000 30 2023
12 EXP12 Castelló Sanidad 4100 35 2024ayudas %>%
arrange(desc(importe)) expediente provincia programa importe beneficiarios año
1 EXP12 Castelló Sanidad 4100 35 2024
2 EXP6 Castelló Sanidad 4000 30 2023
3 EXP8 Alacant Sanidad 3800 28 2024
4 EXP10 València Vivienda 3200 7 2024
5 EXP2 Alacant Vivienda 3000 5 2022
6 EXP5 Alacant Vivienda 2500 6 2023
7 EXP4 València Empleo 1800 12 2023
8 EXP11 Alacant Educación 1700 24 2024
9 EXP7 València Educación 1600 22 2024
10 EXP3 Castelló Educación 1500 20 2022
11 EXP9 Castelló Empleo 1400 11 2024
12 EXP1 València Empleo 1200 10 2022ayudas %>%
arrange(provincia, desc(importe)) expediente provincia programa importe beneficiarios año
1 EXP8 Alacant Sanidad 3800 28 2024
2 EXP2 Alacant Vivienda 3000 5 2022
3 EXP5 Alacant Vivienda 2500 6 2023
4 EXP11 Alacant Educación 1700 24 2024
5 EXP12 Castelló Sanidad 4100 35 2024
6 EXP6 Castelló Sanidad 4000 30 2023
7 EXP3 Castelló Educación 1500 20 2022
8 EXP9 Castelló Empleo 1400 11 2024
9 EXP10 València Vivienda 3200 7 2024
10 EXP4 València Empleo 1800 12 2023
11 EXP7 València Educación 1600 22 2024
12 EXP1 València Empleo 1200 10 2022mutate()ayudas %>%
mutate(importe_por_beneficiario = importe / beneficiarios) expediente provincia programa importe beneficiarios año
1 EXP1 València Empleo 1200 10 2022
2 EXP2 Alacant Vivienda 3000 5 2022
3 EXP3 Castelló Educación 1500 20 2022
4 EXP4 València Empleo 1800 12 2023
5 EXP5 Alacant Vivienda 2500 6 2023
6 EXP6 Castelló Sanidad 4000 30 2023
7 EXP7 València Educación 1600 22 2024
8 EXP8 Alacant Sanidad 3800 28 2024
9 EXP9 Castelló Empleo 1400 11 2024
10 EXP10 València Vivienda 3200 7 2024
11 EXP11 Alacant Educación 1700 24 2024
12 EXP12 Castelló Sanidad 4100 35 2024
importe_por_beneficiario
1 120.00000
2 600.00000
3 75.00000
4 150.00000
5 416.66667
6 133.33333
7 72.72727
8 135.71429
9 127.27273
10 457.14286
11 70.83333
12 117.14286ayudas %>%
mutate(
importe_por_beneficiario = importe / beneficiarios,
ayuda_alta = importe > 3000
) expediente provincia programa importe beneficiarios año
1 EXP1 València Empleo 1200 10 2022
2 EXP2 Alacant Vivienda 3000 5 2022
3 EXP3 Castelló Educación 1500 20 2022
4 EXP4 València Empleo 1800 12 2023
5 EXP5 Alacant Vivienda 2500 6 2023
6 EXP6 Castelló Sanidad 4000 30 2023
7 EXP7 València Educación 1600 22 2024
8 EXP8 Alacant Sanidad 3800 28 2024
9 EXP9 Castelló Empleo 1400 11 2024
10 EXP10 València Vivienda 3200 7 2024
11 EXP11 Alacant Educación 1700 24 2024
12 EXP12 Castelló Sanidad 4100 35 2024
importe_por_beneficiario ayuda_alta
1 120.00000 FALSE
2 600.00000 FALSE
3 75.00000 FALSE
4 150.00000 FALSE
5 416.66667 FALSE
6 133.33333 TRUE
7 72.72727 FALSE
8 135.71429 TRUE
9 127.27273 FALSE
10 457.14286 TRUE
11 70.83333 FALSE
12 117.14286 TRUEayudas %>%
mutate(
tramo_importe = case_when(
importe < 2000 ~ "Bajo",
importe < 3500 ~ "Medio",
TRUE ~ "Alto"
)
) expediente provincia programa importe beneficiarios año
1 EXP1 València Empleo 1200 10 2022
2 EXP2 Alacant Vivienda 3000 5 2022
3 EXP3 Castelló Educación 1500 20 2022
4 EXP4 València Empleo 1800 12 2023
5 EXP5 Alacant Vivienda 2500 6 2023
6 EXP6 Castelló Sanidad 4000 30 2023
7 EXP7 València Educación 1600 22 2024
8 EXP8 Alacant Sanidad 3800 28 2024
9 EXP9 Castelló Empleo 1400 11 2024
10 EXP10 València Vivienda 3200 7 2024
11 EXP11 Alacant Educación 1700 24 2024
12 EXP12 Castelló Sanidad 4100 35 2024
tramo_importe
1 Bajo
2 Medio
3 Bajo
4 Bajo
5 Medio
6 Alto
7 Bajo
8 Alto
9 Bajo
10 Medio
11 Bajo
12 Altosummarise()ayudas %>%
summarise(
importe_total = sum(importe),
importe_medio = mean(importe),
beneficiarios_totales = sum(beneficiarios),
n_expedientes = n()
) importe_total importe_medio beneficiarios_totales n_expedientes
1 29800 2483.333 210 12group_by()ayudas %>%
group_by(provincia) %>%
summarise(
importe_total = sum(importe),
beneficiarios_totales = sum(beneficiarios),
expedientes = n()
)# A tibble: 3 × 4
provincia importe_total beneficiarios_totales expedientes
<chr> <dbl> <dbl> <int>
1 Alacant 11000 63 4
2 Castelló 11000 96 4
3 València 7800 51 4ayudas %>%
group_by(programa) %>%
summarise(
importe_medio = mean(importe),
beneficiarios_medios = mean(beneficiarios)
)# A tibble: 4 × 3
programa importe_medio beneficiarios_medios
<chr> <dbl> <dbl>
1 Educación 1600 22
2 Empleo 1467. 11
3 Sanidad 3967. 31
4 Vivienda 2900 6ayudas %>%
group_by(año, provincia) %>%
summarise(
importe_total = sum(importe),
.groups = "drop"
)# A tibble: 9 × 3
año provincia importe_total
<dbl> <chr> <dbl>
1 2022 Alacant 3000
2 2022 Castelló 1500
3 2022 València 1200
4 2023 Alacant 2500
5 2023 Castelló 4000
6 2023 València 1800
7 2024 Alacant 5500
8 2024 Castelló 5500
9 2024 València 4800ayudas %>%
group_by(programa) %>%
summarise(
gasto_total = sum(importe),
personas_atendidas = sum(beneficiarios),
coste_medio_por_persona = gasto_total / personas_atendidas,
expedientes = n(),
.groups = "drop"
)# A tibble: 4 × 5
programa gasto_total personas_atendidas coste_medio_por_persona
<chr> <dbl> <dbl> <dbl>
1 Educación 4800 66 72.7
2 Empleo 4400 33 133.
3 Sanidad 11900 93 128.
4 Vivienda 8700 18 483.
# ℹ 1 more variable: expedientes <int>ayudas %>%
group_by(provincia) %>%
summarise(
gasto_total = sum(importe),
beneficiarios = sum(beneficiarios),
gasto_por_beneficiario = gasto_total / beneficiarios,
.groups = "drop"
) %>%
arrange(desc(gasto_por_beneficiario))# A tibble: 3 × 4
provincia gasto_total beneficiarios gasto_por_beneficiario
<chr> <dbl> <dbl> <dbl>
1 Alacant 11000 63 175.
2 València 7800 51 153.
3 Castelló 11000 96 115.ayudas %>%
group_by(año) %>%
summarise(
gasto_total = sum(importe),
beneficiarios = sum(beneficiarios),
expedientes = n(),
.groups = "drop"
)# A tibble: 3 × 4
año gasto_total beneficiarios expedientes
<dbl> <dbl> <dbl> <int>
1 2022 5700 35 3
2 2023 8300 48 3
3 2024 15800 127 6ayudas %>%
group_by(año, programa) %>%
summarise(
gasto_total = sum(importe),
.groups = "drop"
) %>%
arrange(programa, año)# A tibble: 10 × 3
año programa gasto_total
<dbl> <chr> <dbl>
1 2022 Educación 1500
2 2024 Educación 3300
3 2022 Empleo 1200
4 2023 Empleo 1800
5 2024 Empleo 1400
6 2023 Sanidad 4000
7 2024 Sanidad 7900
8 2022 Vivienda 3000
9 2023 Vivienda 2500
10 2024 Vivienda 3200count()ayudas %>%
count(provincia) provincia n
1 Alacant 4
2 Castelló 4
3 València 4ayudas %>%
count(programa, sort = TRUE) programa n
1 Educación 3
2 Empleo 3
3 Sanidad 3
4 Vivienda 3ayudas %>%
count(año, provincia) año provincia n
1 2022 Alacant 1
2 2022 Castelló 1
3 2022 València 1
4 2023 Alacant 1
5 2023 Castelló 1
6 2023 València 1
7 2024 Alacant 2
8 2024 Castelló 2
9 2024 València 2rename()ayudas %>%
rename(
id_expediente = expediente,
cuantia = importe,
personas_beneficiarias = beneficiarios
) id_expediente provincia programa cuantia personas_beneficiarias
1 EXP1 València Empleo 1200 10
2 EXP2 Alacant Vivienda 3000 5
3 EXP3 Castelló Educación 1500 20
4 EXP4 València Empleo 1800 12
5 EXP5 Alacant Vivienda 2500 6
6 EXP6 Castelló Sanidad 4000 30
7 EXP7 València Educación 1600 22
8 EXP8 Alacant Sanidad 3800 28
9 EXP9 Castelló Empleo 1400 11
10 EXP10 València Vivienda 3200 7
11 EXP11 Alacant Educación 1700 24
12 EXP12 Castelló Sanidad 4100 35
año
1 2022
2 2022
3 2022
4 2023
5 2023
6 2023
7 2024
8 2024
9 2024
10 2024
11 2024
12 2024relocate()ayudas %>%
mutate(importe_por_beneficiario = importe / beneficiarios) %>%
relocate(importe_por_beneficiario, .after = importe) expediente provincia programa importe importe_por_beneficiario
1 EXP1 València Empleo 1200 120.00000
2 EXP2 Alacant Vivienda 3000 600.00000
3 EXP3 Castelló Educación 1500 75.00000
4 EXP4 València Empleo 1800 150.00000
5 EXP5 Alacant Vivienda 2500 416.66667
6 EXP6 Castelló Sanidad 4000 133.33333
7 EXP7 València Educación 1600 72.72727
8 EXP8 Alacant Sanidad 3800 135.71429
9 EXP9 Castelló Empleo 1400 127.27273
10 EXP10 València Vivienda 3200 457.14286
11 EXP11 Alacant Educación 1700 70.83333
12 EXP12 Castelló Sanidad 4100 117.14286
beneficiarios año
1 10 2022
2 5 2022
3 20 2022
4 12 2023
5 6 2023
6 30 2023
7 22 2024
8 28 2024
9 11 2024
10 7 2024
11 24 2024
12 35 2024distinct()ayudas %>%
distinct(provincia) provincia
1 València
2 Alacant
3 Castellóayudas %>%
distinct(programa) programa
1 Empleo
2 Vivienda
3 Educación
4 Sanidadayudas %>%
distinct(provincia, programa) provincia programa
1 València Empleo
2 Alacant Vivienda
3 Castelló Educación
4 Castelló Sanidad
5 València Educación
6 Alacant Sanidad
7 Castelló Empleo
8 València Vivienda
9 Alacant Educaciónleft_join()poblacion <- data.frame(
provincia = c("València", "Alacant", "Castelló"),
poblacion = c(2650000, 1900000, 600000)
)ayudas %>%
group_by(provincia) %>%
summarise(
gasto_total = sum(importe),
beneficiarios = sum(beneficiarios),
.groups = "drop"
) %>%
left_join(poblacion, by = "provincia") %>%
mutate(
gasto_por_habitante = gasto_total / poblacion,
beneficiarios_por_1000_hab = beneficiarios / poblacion * 1000
)# A tibble: 3 × 6
provincia gasto_total beneficiarios poblacion gasto_por_habitante
<chr> <dbl> <dbl> <dbl> <dbl>
1 Alacant 11000 63 1900000 0.00579
2 Castelló 11000 96 600000 0.0183
3 València 7800 51 2650000 0.00294
# ℹ 1 more variable: beneficiarios_por_1000_hab <dbl>tidyrindicadores <- data.frame(
provincia = c("València", "Alacant", "Castelló"),
empleo_2022 = c(68.2, 65.4, 66.1),
empleo_2023 = c(69.5, 66.7, 67.3),
empleo_2024 = c(70.1, 67.2, 68.0),
pobreza_2022 = c(18.4, 20.1, 17.8),
pobreza_2023 = c(17.9, 19.5, 17.1),
pobreza_2024 = c(17.2, 18.8, 16.5)
)pivot_longer()indicadores_largo <- indicadores %>%
pivot_longer(
cols = -provincia,
names_to = "indicador_año",
values_to = "valor"
)
indicadores_largo# A tibble: 18 × 3
provincia indicador_año valor
<chr> <chr> <dbl>
1 València empleo_2022 68.2
2 València empleo_2023 69.5
3 València empleo_2024 70.1
4 València pobreza_2022 18.4
5 València pobreza_2023 17.9
6 València pobreza_2024 17.2
7 Alacant empleo_2022 65.4
8 Alacant empleo_2023 66.7
9 Alacant empleo_2024 67.2
10 Alacant pobreza_2022 20.1
11 Alacant pobreza_2023 19.5
12 Alacant pobreza_2024 18.8
13 Castelló empleo_2022 66.1
14 Castelló empleo_2023 67.3
15 Castelló empleo_2024 68
16 Castelló pobreza_2022 17.8
17 Castelló pobreza_2023 17.1
18 Castelló pobreza_2024 16.5Separar indicador y año:
indicadores_largo <- indicadores %>%
pivot_longer(
cols = -provincia,
names_to = c("indicador", "año"),
names_sep = "_",
values_to = "valor"
)
indicadores_largo# A tibble: 18 × 4
provincia indicador año valor
<chr> <chr> <chr> <dbl>
1 València empleo 2022 68.2
2 València empleo 2023 69.5
3 València empleo 2024 70.1
4 València pobreza 2022 18.4
5 València pobreza 2023 17.9
6 València pobreza 2024 17.2
7 Alacant empleo 2022 65.4
8 Alacant empleo 2023 66.7
9 Alacant empleo 2024 67.2
10 Alacant pobreza 2022 20.1
11 Alacant pobreza 2023 19.5
12 Alacant pobreza 2024 18.8
13 Castelló empleo 2022 66.1
14 Castelló empleo 2023 67.3
15 Castelló empleo 2024 68
16 Castelló pobreza 2022 17.8
17 Castelló pobreza 2023 17.1
18 Castelló pobreza 2024 16.5Convertir el año a numérico:
indicadores_largo <- indicadores %>%
pivot_longer(
cols = -provincia,
names_to = c("indicador", "año"),
names_sep = "_",
values_to = "valor"
) %>%
mutate(año = as.integer(año))Seleccionar solo algunas columnas:
indicadores %>%
pivot_longer(
cols = starts_with("empleo"),
names_to = "año",
names_prefix = "empleo_",
values_to = "tasa_empleo"
)# A tibble: 9 × 6
provincia pobreza_2022 pobreza_2023 pobreza_2024 año tasa_empleo
<chr> <dbl> <dbl> <dbl> <chr> <dbl>
1 València 18.4 17.9 17.2 2022 68.2
2 València 18.4 17.9 17.2 2023 69.5
3 València 18.4 17.9 17.2 2024 70.1
4 Alacant 20.1 19.5 18.8 2022 65.4
5 Alacant 20.1 19.5 18.8 2023 66.7
6 Alacant 20.1 19.5 18.8 2024 67.2
7 Castelló 17.8 17.1 16.5 2022 66.1
8 Castelló 17.8 17.1 16.5 2023 67.3
9 Castelló 17.8 17.1 16.5 2024 68 Ejemplo con gasto público por año:
gasto <- data.frame(
programa = c("Empleo", "Vivienda", "Educación", "Sanidad"),
gasto_2022 = c(1200000, 900000, 1500000, 2200000),
gasto_2023 = c(1350000, 950000, 1600000, 2400000),
gasto_2024 = c(1500000, 1100000, 1750000, 2600000)
)gasto_largo <- gasto %>%
pivot_longer(
cols = starts_with("gasto"),
names_to = "año",
names_prefix = "gasto_",
values_to = "gasto"
) %>%
mutate(año = as.integer(año))
gasto_largo# A tibble: 12 × 3
programa año gasto
<chr> <int> <dbl>
1 Empleo 2022 1200000
2 Empleo 2023 1350000
3 Empleo 2024 1500000
4 Vivienda 2022 900000
5 Vivienda 2023 950000
6 Vivienda 2024 1100000
7 Educación 2022 1500000
8 Educación 2023 1600000
9 Educación 2024 1750000
10 Sanidad 2022 2200000
11 Sanidad 2023 2400000
12 Sanidad 2024 2600000gasto_largo %>%
group_by(año) %>%
summarise(
gasto_total = sum(gasto),
.groups = "drop"
)# A tibble: 3 × 2
año gasto_total
<int> <dbl>
1 2022 5800000
2 2023 6300000
3 2024 6950000gasto_largo %>%
group_by(programa) %>%
summarise(
gasto_medio = mean(gasto),
crecimiento_2022_2024 = gasto[año == 2024] - gasto[año == 2022],
crecimiento_2022_2024_rel = (gasto[año == 2024] - gasto[año == 2022]) / gasto[año == 2022],
.groups = "drop"
)# A tibble: 4 × 4
programa gasto_medio crecimiento_2022_2024 crecimiento_2022_202…¹
<chr> <dbl> <dbl> <dbl>
1 Educación 1616667. 250000 0.167
2 Empleo 1350000 300000 0.25
3 Sanidad 2400000 400000 0.182
4 Vivienda 983333. 200000 0.222
# ℹ abbreviated name: ¹crecimiento_2022_2024_relejecucion <- data.frame(
provincia = c("València", "València", "València",
"Alacant", "Alacant", "Alacant",
"Castelló", "Castelló", "Castelló"),
año = c(2022, 2023, 2024,
2022, 2023, 2024,
2022, 2023, 2024),
gasto = c(1200000, 1350000, 1500000,
900000, 950000, 1100000,
600000, 680000, 750000)
)pivot_wider()ejecucion %>%
pivot_wider(
names_from = año,
values_from = gasto
)# A tibble: 3 × 4
provincia `2022` `2023` `2024`
<chr> <dbl> <dbl> <dbl>
1 València 1200000 1350000 1500000
2 Alacant 900000 950000 1100000
3 Castelló 600000 680000 750000Crear nombres de columnas más claros:
ejecucion %>%
pivot_wider(
names_from = año,
values_from = gasto,
names_prefix = "gasto_"
)# A tibble: 3 × 4
provincia gasto_2022 gasto_2023 gasto_2024
<chr> <dbl> <dbl> <dbl>
1 València 1200000 1350000 1500000
2 Alacant 900000 950000 1100000
3 Castelló 600000 680000 750000Más de una variable de valores:
seguimiento <- data.frame(
provincia = c("València", "València", "València",
"Alacant", "Alacant", "Alacant"),
año = c(2022, 2023, 2024, 2022, 2023, 2024),
gasto = c(1200000, 1350000, 1500000, 900000, 950000, 1100000),
beneficiarios = c(1000, 1200, 1400, 800, 850, 950)
)seguimiento %>%
pivot_wider(
names_from = año,
values_from = c(gasto, beneficiarios),
names_glue = "{.value}_{año}"
)# A tibble: 2 × 7
provincia gasto_2022 gasto_2023 gasto_2024 beneficiarios_2022
<chr> <dbl> <dbl> <dbl> <dbl>
1 València 1200000 1350000 1500000 1000
2 Alacant 900000 950000 1100000 800
# ℹ 2 more variables: beneficiarios_2023 <dbl>,
# beneficiarios_2024 <dbl>Rellena valores ausentes:
seguimiento_incompleto <- data.frame(
provincia = c("València", "València", "Alacant", "Castelló"),
año = c(2023, 2024, 2024, 2024),
gasto = c(1350000, 1500000, 1100000, 750000)
)seguimiento_incompleto %>%
pivot_wider(
names_from = año,
values_from = gasto,
names_prefix = "gasto_",
values_fill = 0
)# A tibble: 3 × 3
provincia gasto_2023 gasto_2024
<chr> <dbl> <dbl>
1 València 1350000 1500000
2 Alacant 0 1100000
3 Castelló 0 750000Cuando hay duplicados:
solicitudes <- data.frame(
provincia = c("València", "València", "València", "Alacant", "Alacant"),
programa = c("Empleo", "Empleo", "Vivienda", "Empleo", "Vivienda"),
solicitudes = c(100, 120, 80, 90, 70)
)solicitudes %>%
pivot_wider(
names_from = programa,
values_from = solicitudes,
values_fn = sum,
values_fill = 0
)# A tibble: 2 × 3
provincia Empleo Vivienda
<chr> <dbl> <dbl>
1 València 220 80
2 Alacant 90 70ggplot2evaluacion <- data.frame(
provincia = c("València", "València", "València",
"Alacant", "Alacant", "Alacant",
"Castelló", "Castelló", "Castelló"),
año = c(2022, 2023, 2024,
2022, 2023, 2024,
2022, 2023, 2024),
gasto = c(1200000, 1350000, 1500000,
900000, 950000, 1100000,
600000, 680000, 750000),
beneficiarios = c(1000, 1200, 1400,
800, 850, 950,
500, 600, 700),
satisfaccion = c(7.1, 7.4, 7.8,
6.8, 7.0, 7.3,
7.3, 7.5, 7.7)
)ggplot(data = evaluacion, aes(x = año, y = gasto)) +
geom_point()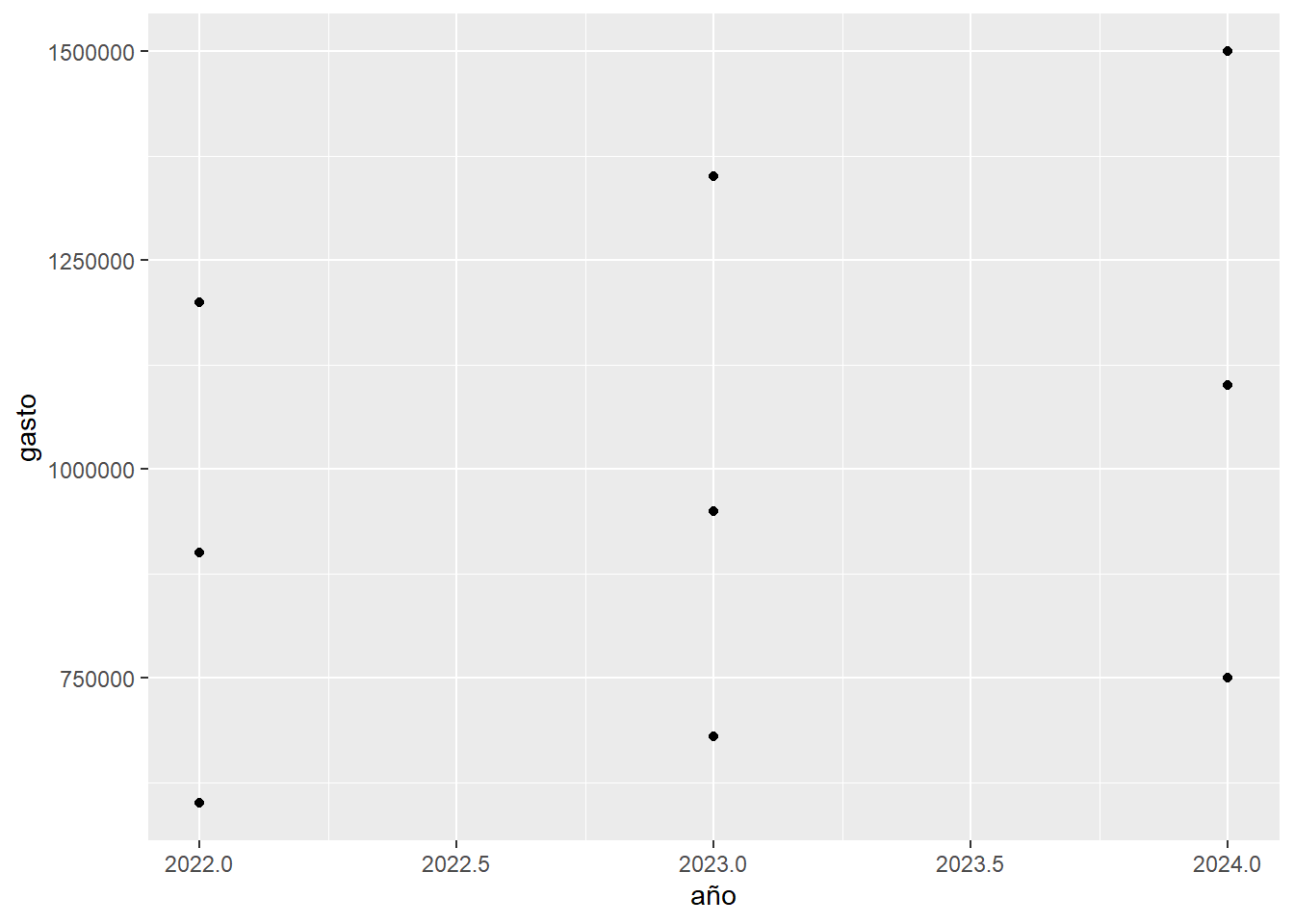
evaluacion %>%
ggplot(aes(x = año, y = gasto)) +
geom_point()
geom_pointevaluacion %>%
ggplot(aes(x = beneficiarios, y = gasto)) +
geom_point()
Con color por provincia:
evaluacion %>%
ggplot(aes(x = beneficiarios, y = gasto, color = provincia)) +
geom_point(size = 3)
geom_lineevaluacion %>%
ggplot(aes(x = año, y = gasto, group = provincia)) +
geom_line() +
geom_point()
Con color por provincia:
evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3)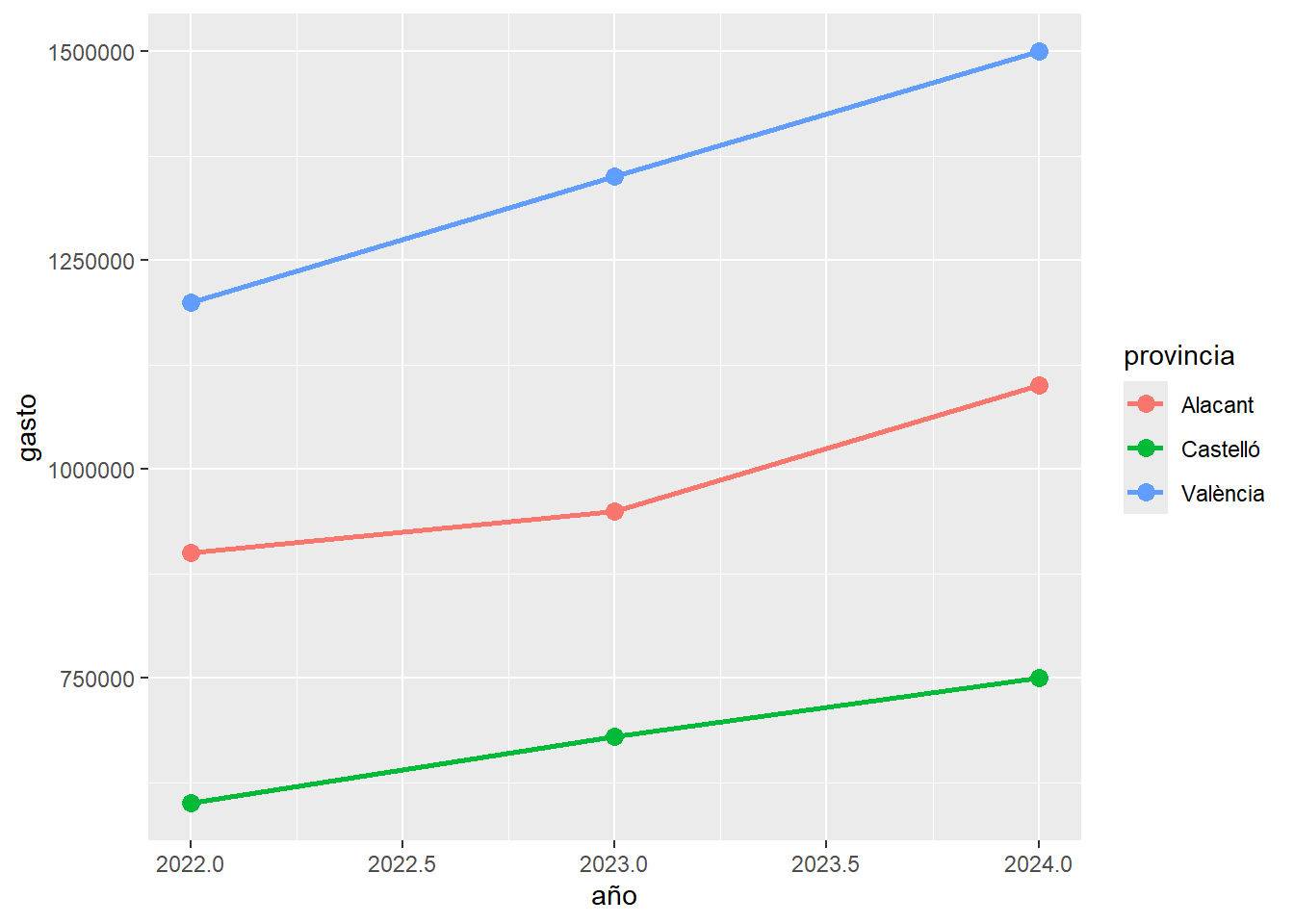
geom_colevaluacion %>%
filter(año == 2024) %>%
ggplot(aes(x = provincia, y = gasto)) +
geom_col()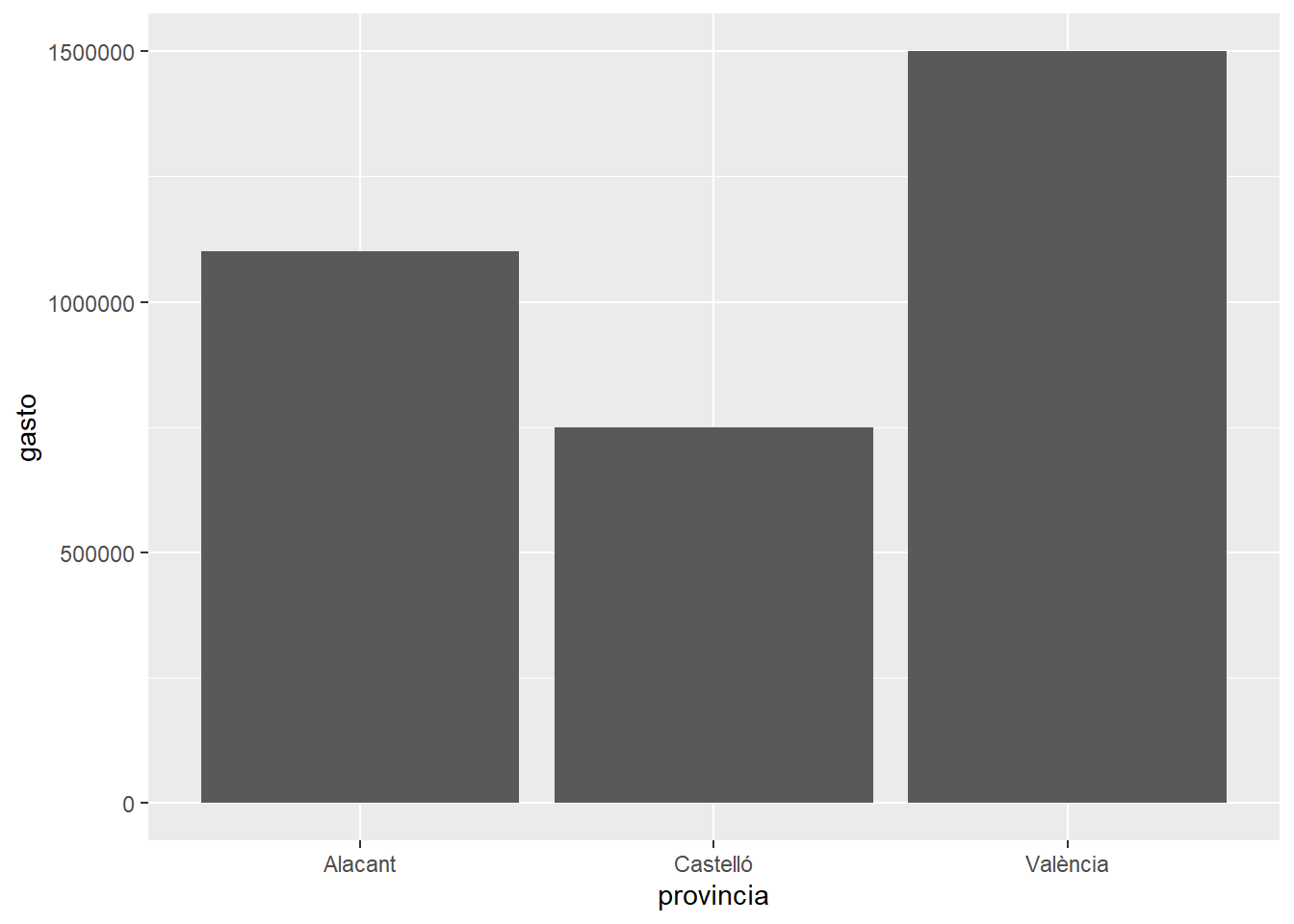
Ordenando provincias por gasto:
evaluacion %>%
filter(año == 2024) %>%
ggplot(aes(x = reorder(provincia, gasto), y = gasto)) +
geom_col() +
coord_flip()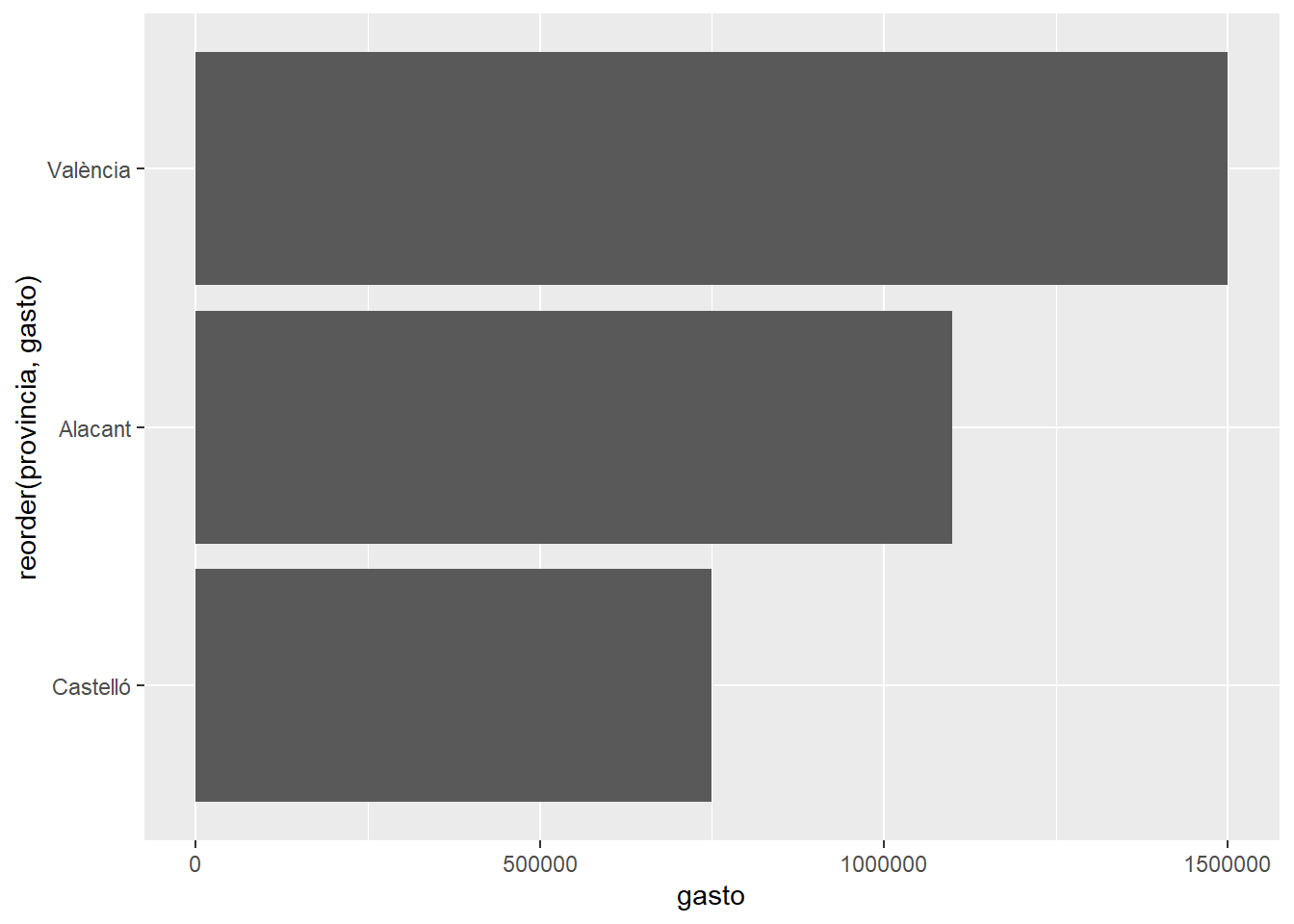
Barras agrupadas:
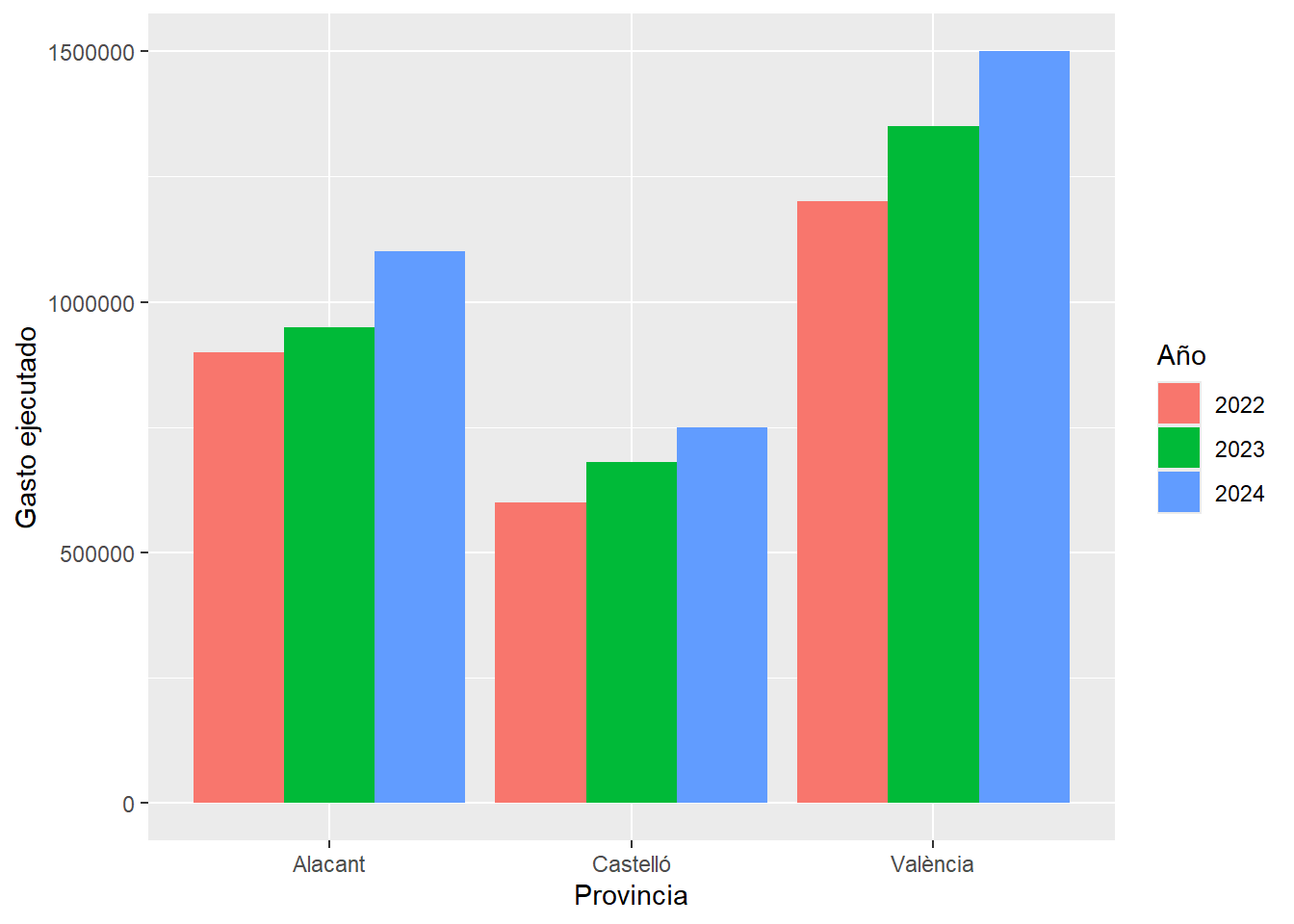
evaluacion %>%
ggplot(aes(x = provincia, y = gasto, fill = factor(año))) +
geom_col(position = "dodge")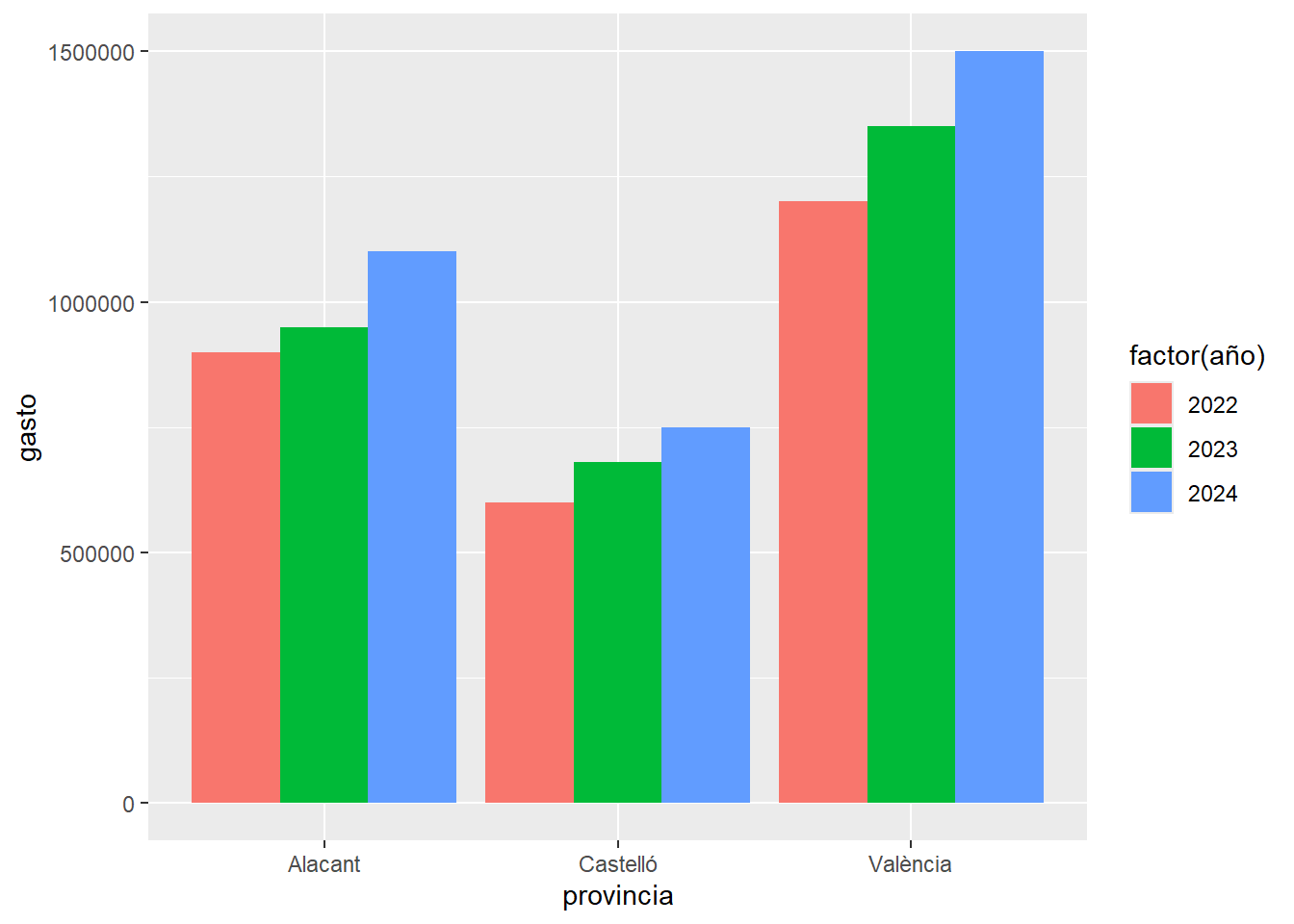
Con etiquetas más claras:
evaluacion %>%
ggplot(aes(x = provincia, y = gasto, fill = factor(año))) +
geom_col(position = "dodge") +
labs(
x = "Provincia",
y = "Gasto ejecutado",
fill = "Año"
)
Barras apiladas:
evaluacion %>%
ggplot(aes(x = provincia, y = beneficiarios, fill = factor(año))) +
geom_col()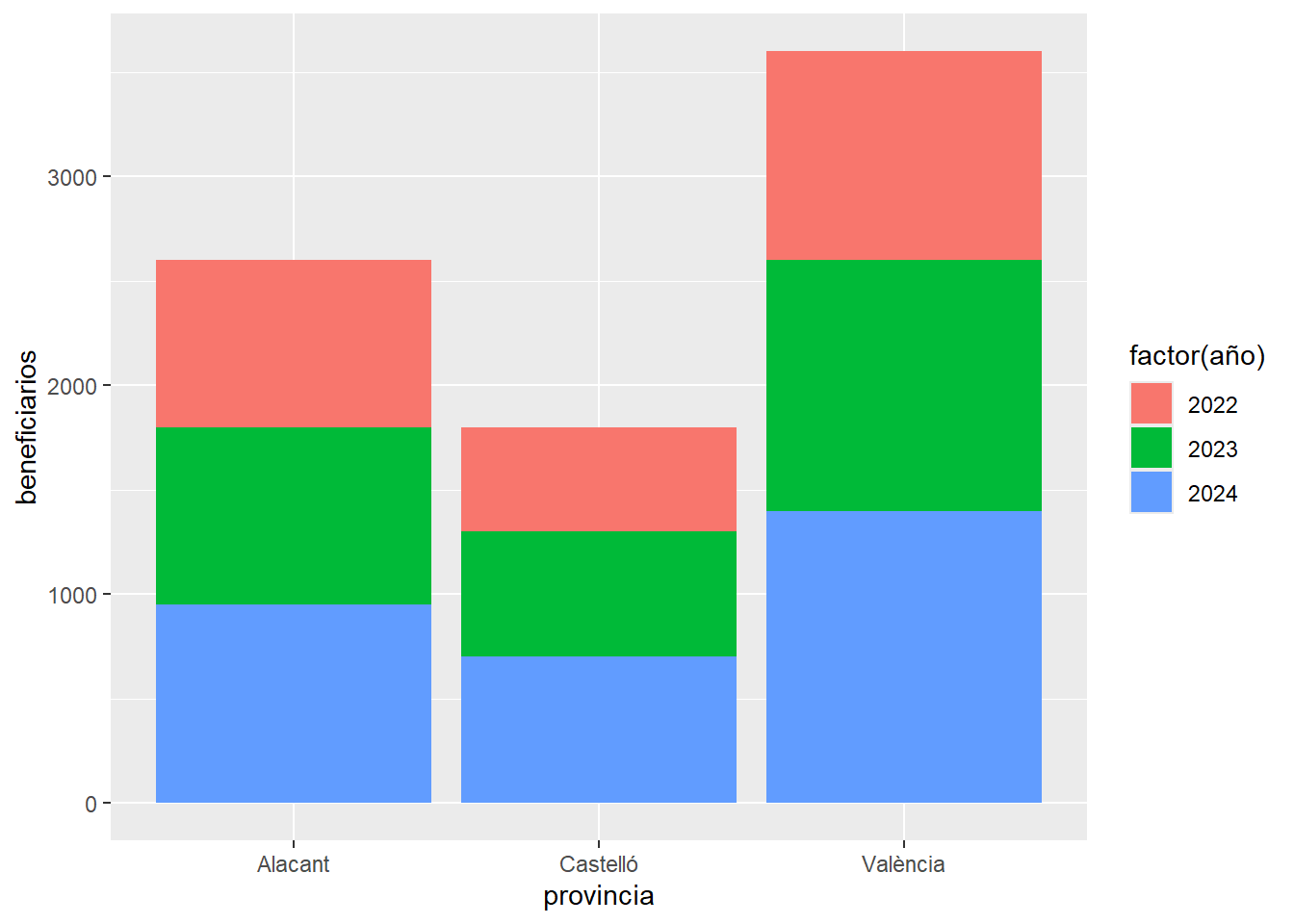
Barras apiladas al 100%:
evaluacion %>%
ggplot(aes(x = provincia, y = beneficiarios, fill = factor(año))) +
geom_col(position = "fill") +
labs(
y = "Proporción",
fill = "Año"
)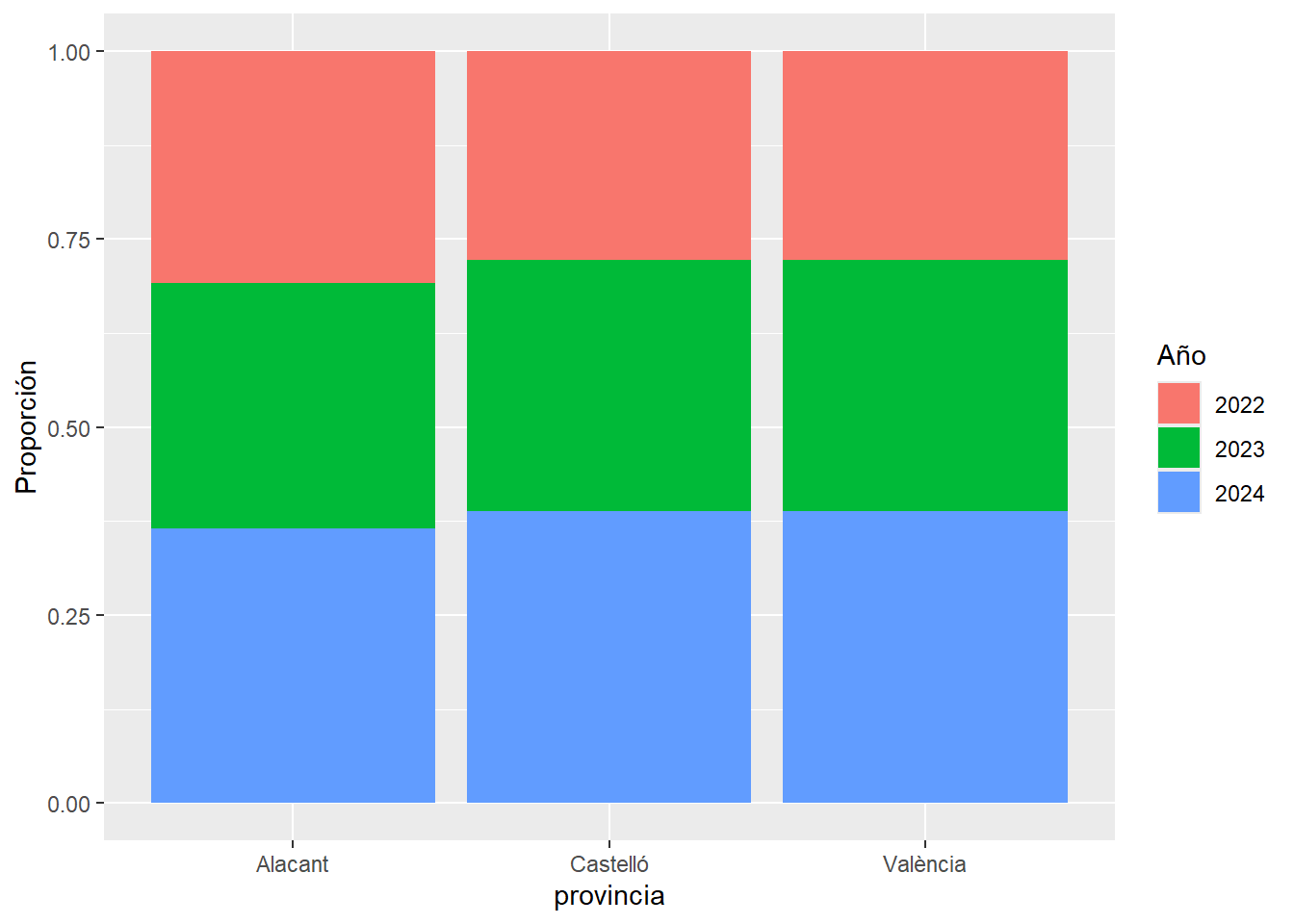
Gráfico de dispersión con recta de tendencia:
evaluacion %>%
ggplot(aes(x = gasto, y = satisfaccion)) +
geom_point(size = 3) +
geom_smooth(method = "lm", se = FALSE)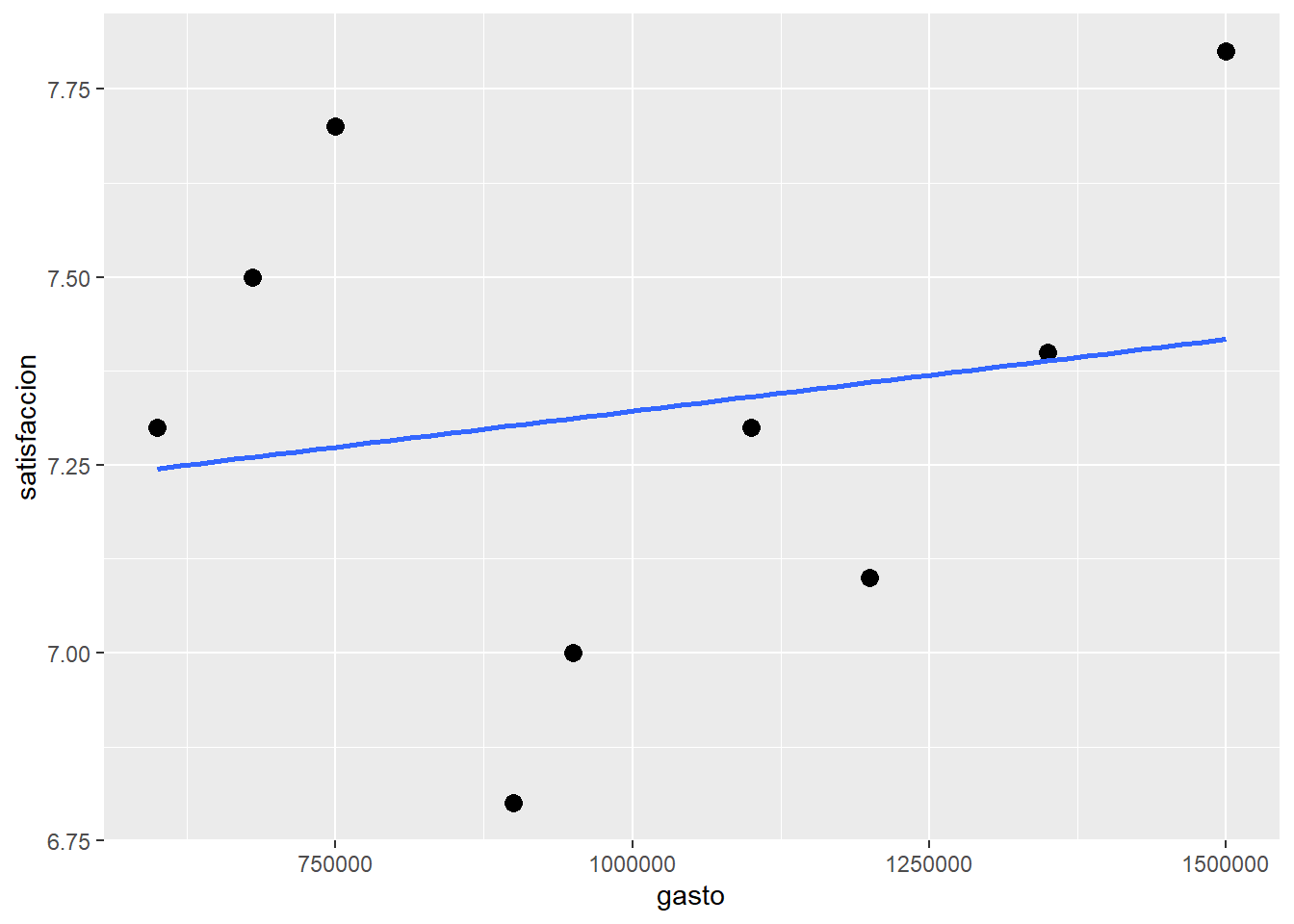
Con color por provincia:
evaluacion %>%
ggplot(aes(x = gasto, y = satisfaccion, color = provincia)) +
geom_point(size = 3) +
geom_smooth(method = "lm", se = FALSE)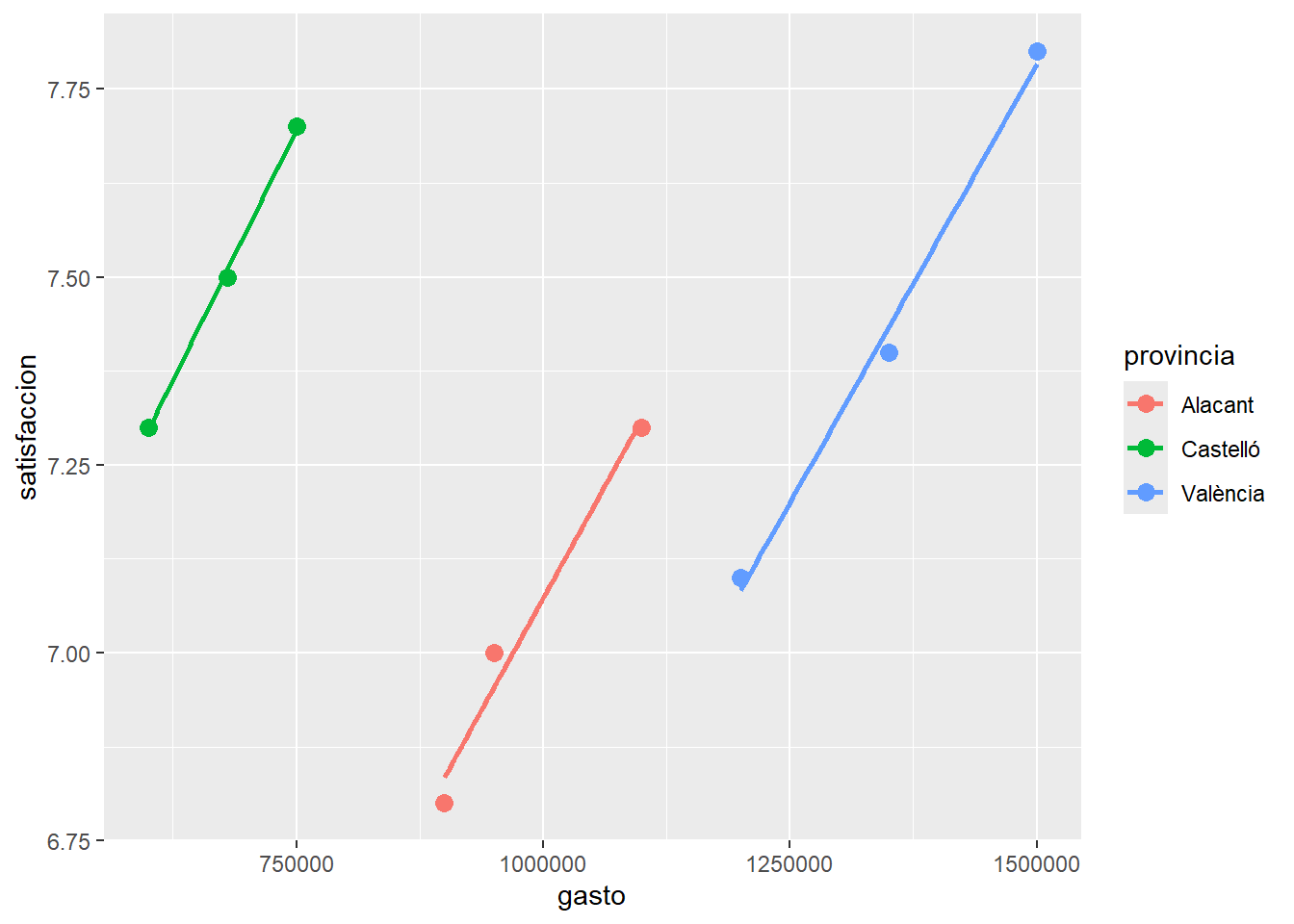
Crear indicadores antes de graficar:
evaluacion %>%
mutate(
gasto_por_beneficiario = gasto / beneficiarios
) %>%
ggplot(aes(x = año, y = gasto_por_beneficiario, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3)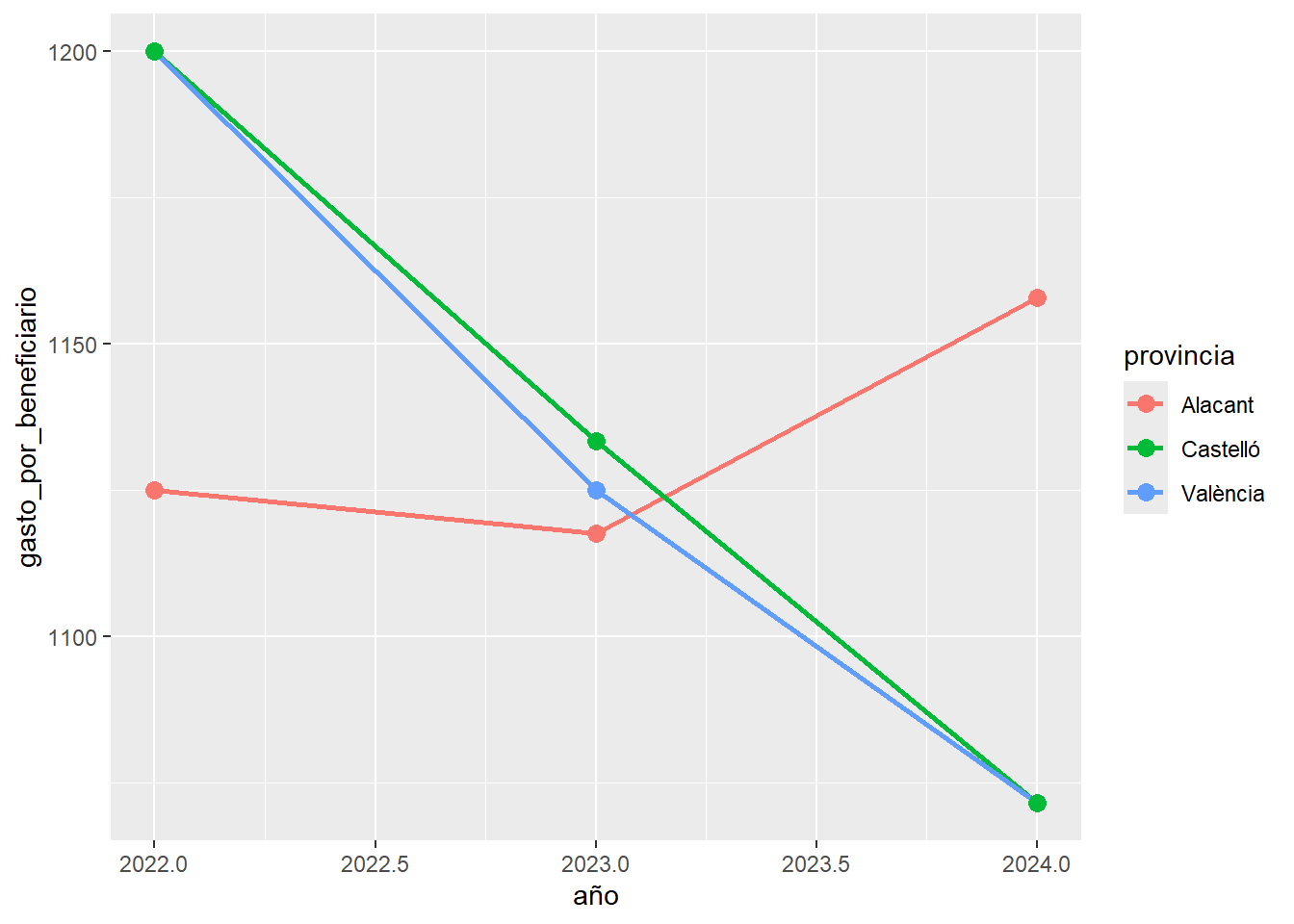
facet_wrap()evaluacion %>%
ggplot(aes(x = año, y = gasto)) +
geom_line() +
geom_point() +
facet_wrap(~ provincia)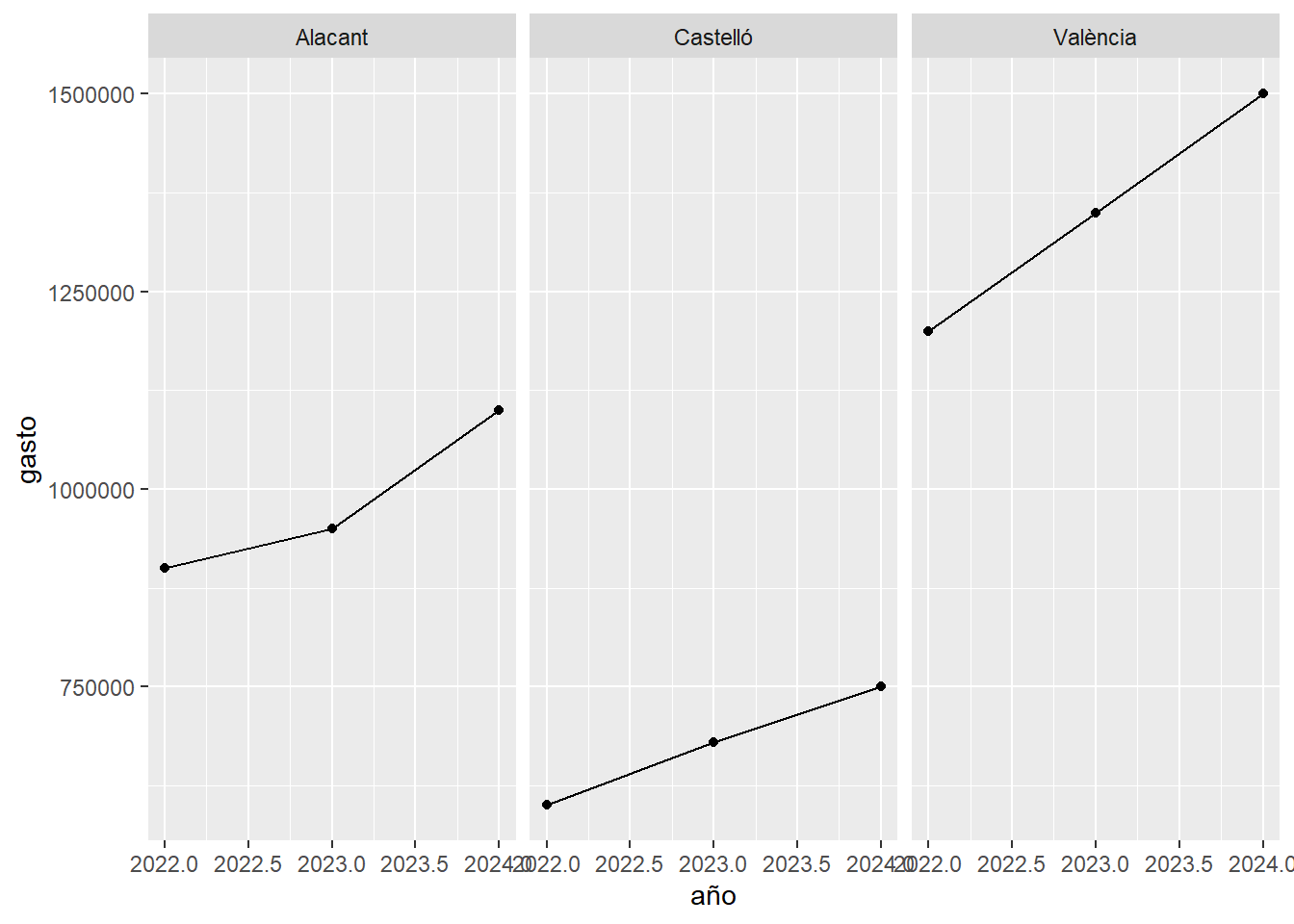
evaluacion %>%
mutate(gasto_por_beneficiario = gasto / beneficiarios) %>%
ggplot(aes(x = año, y = gasto_por_beneficiario)) +
geom_line() +
geom_point() +
facet_wrap(~ provincia)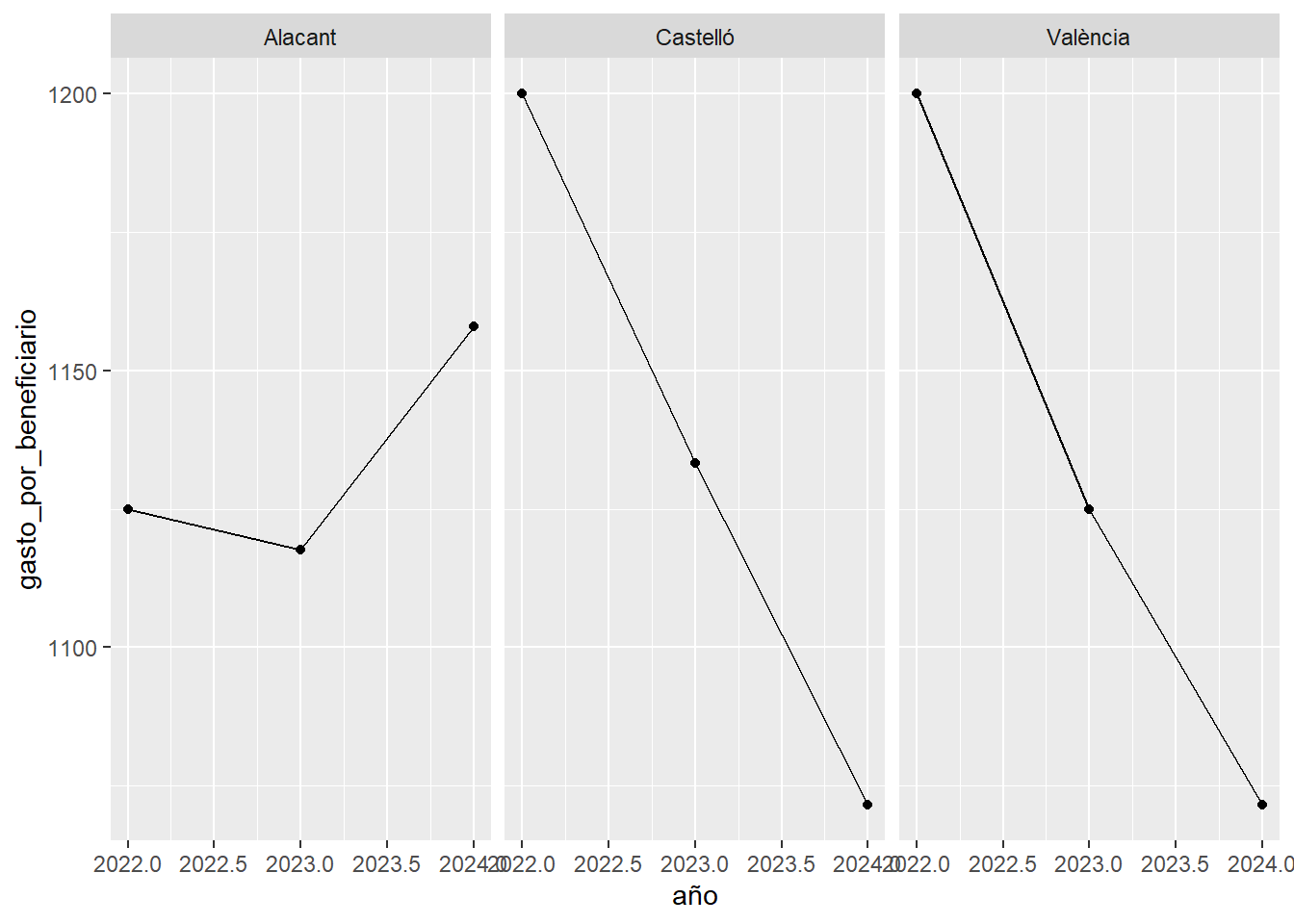
Facetas con dos variables:
programas <- data.frame(
provincia = rep(c("València", "Alacant", "Castelló"), each = 6),
programa = rep(c("Empleo", "Vivienda"), each = 3, times = 3),
año = rep(c(2022, 2023, 2024), times = 6),
gasto = c(
800000, 900000, 1000000,
400000, 450000, 500000,
600000, 650000, 750000,
300000, 300000, 350000,
400000, 450000, 500000,
200000, 230000, 250000
)
)programas %>%
ggplot(aes(x = año, y = gasto, color = programa)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
facet_wrap(~ provincia)
labs():evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
labs(
title = "Evolución del gasto ejecutado por provincia",
subtitle = "Programas seleccionados, 2022-2024",
x = "Año",
y = "Gasto ejecutado (€)",
color = "Provincia",
caption = "Fuente: datos simulados para formación"
)
Formato de ejes:
evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
scale_y_continuous(labels = scales::label_number(big.mark = ".", decimal.mark = ","))
Formato en euros:
evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
scale_y_continuous(
labels = scales::label_currency(
prefix = "",
suffix = " €",
big.mark = ".",
decimal.mark = ","
)
)
Tema visual:
evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
theme_minimal()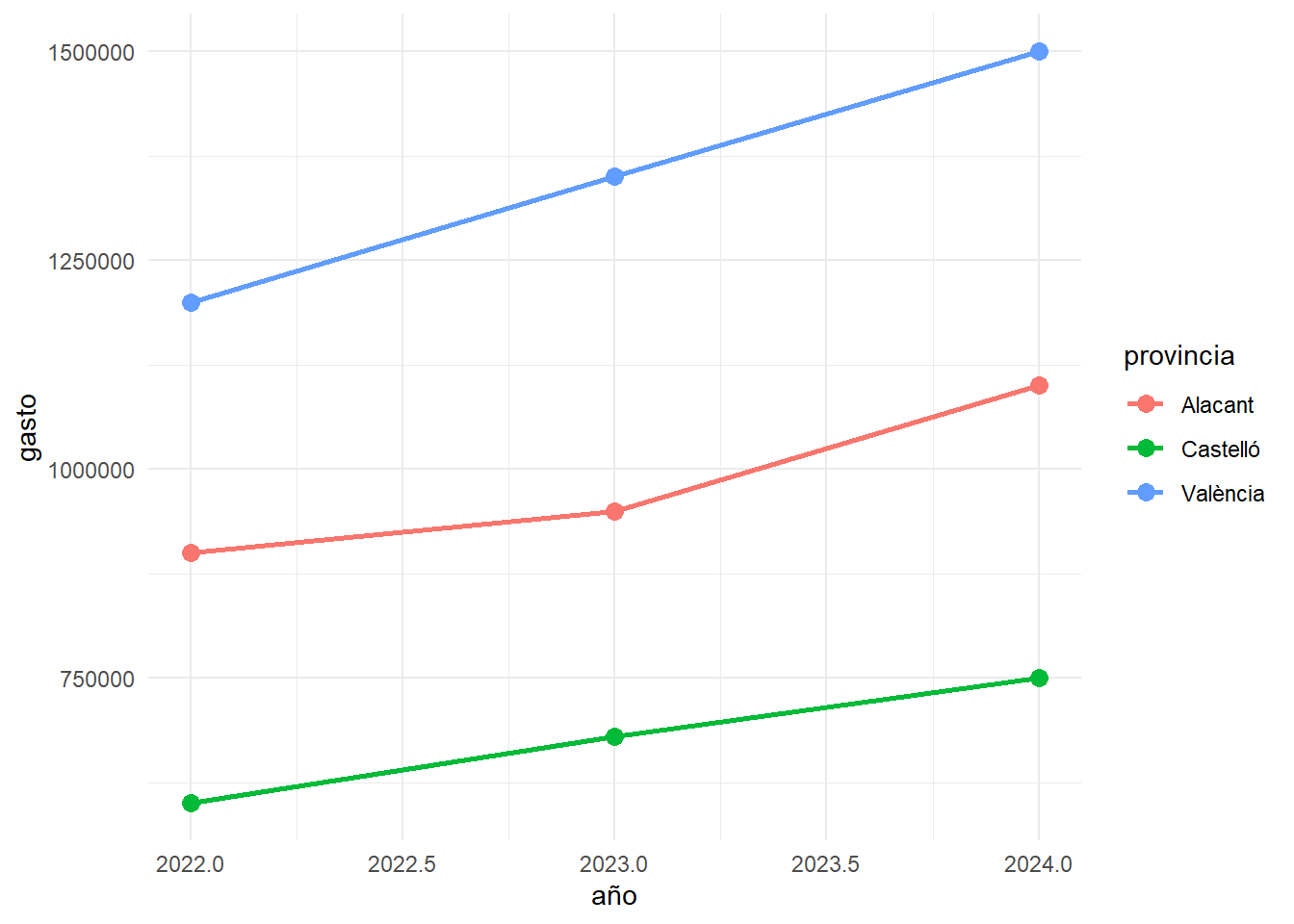
evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
theme_minimal() +
theme(
legend.position = "bottom",
plot.title = element_text(face = "bold")
)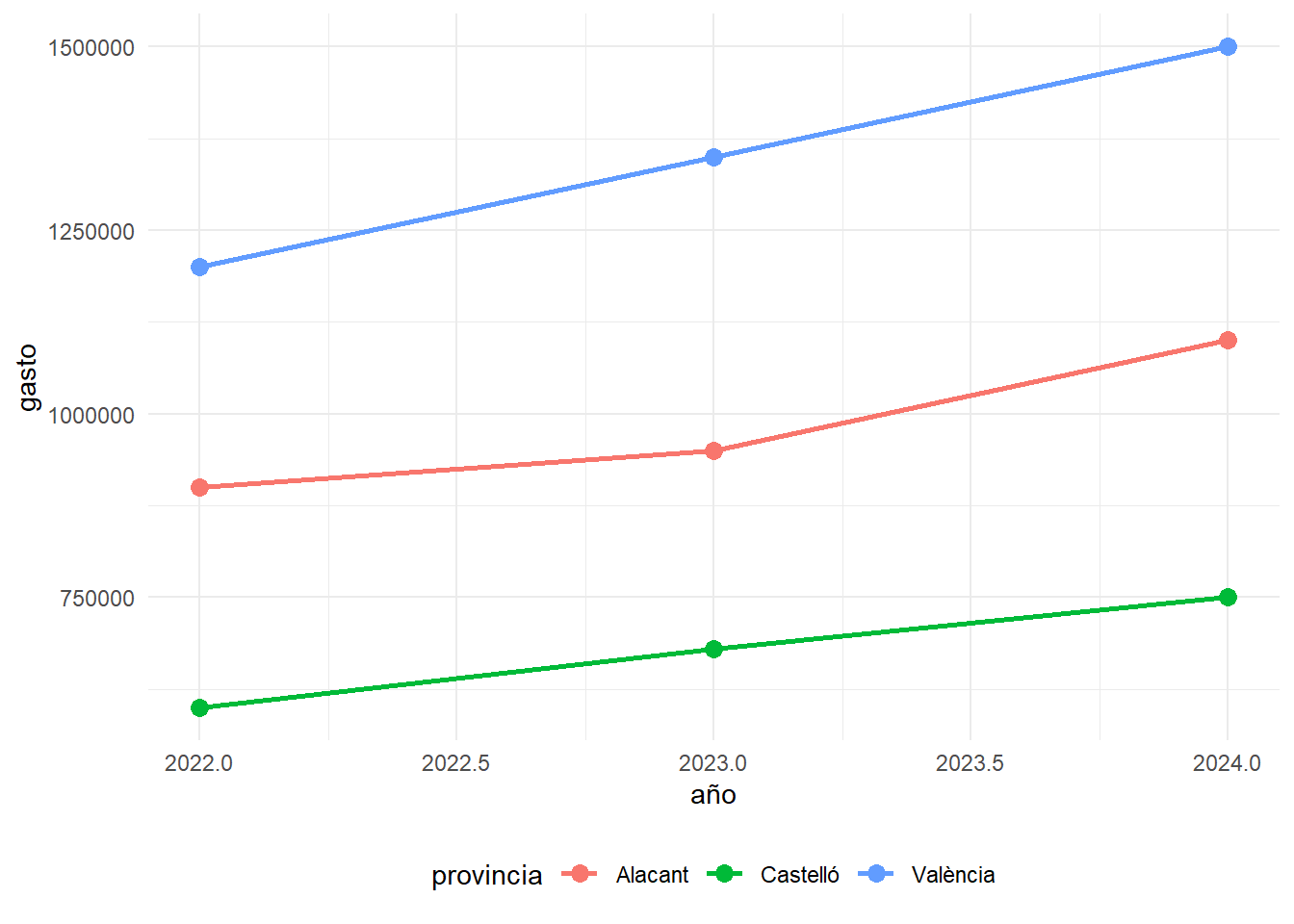
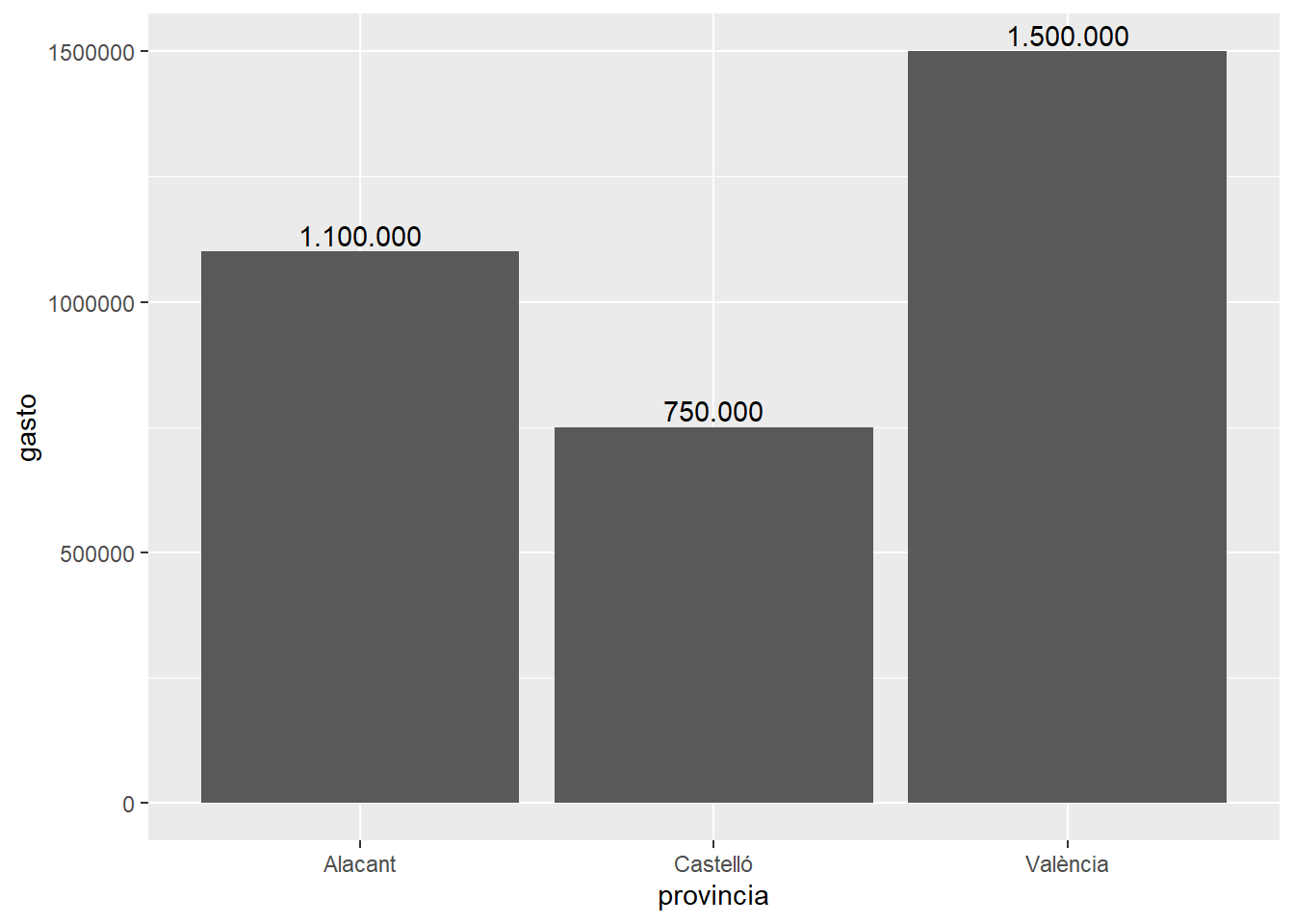
Añadir etiquetas a los valores:
evaluacion %>%
filter(año == 2024) %>%
ggplot(aes(x = provincia, y = gasto)) +
geom_col() +
geom_text(
aes(label = scales::label_number(big.mark = ".", decimal.mark = ",")(gasto)),
vjust = -0.3
)
ggsavegrafico_gasto <- evaluacion %>%
ggplot(aes(x = año, y = gasto, color = provincia)) +
geom_line(linewidth = 1) +
geom_point(size = 3) +
theme_minimal() +
labs(
title = "Evolución del gasto por provincia",
x = "Año",
y = "Gasto ejecutado (€)",
color = "Provincia"
)ggsave(
filename = "grafico_gasto_provincia.png",
plot = grafico_gasto,
width = 8,
height = 5,
dpi = 300
)Obtenemos del INE datos del Censo de Población y Viviendas (resultados municipales), seleccionando todos los valores disponibles y dejando por defecto la forma de presentación de la tabla. En caso de no funcionar el link, descargar los datos de aquí.
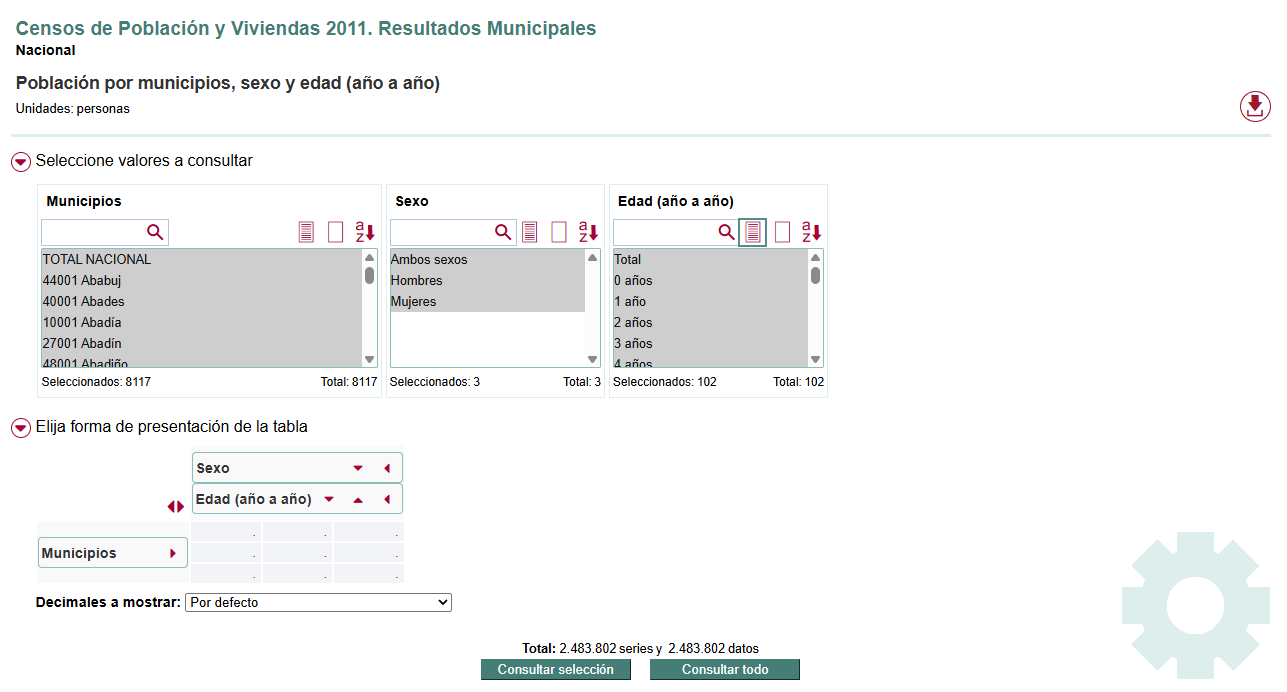
Al abrir el fichero nos damos cuenta de que tenemos que hacer varios arreglos…
Importamos el dataset “por bloques” (primero “Ambos sexos”). Aprovechamos para sustituir .. por NA:
dt1 <- readxl::read_xlsx("censo.xlsx",
range = "A8:CY8125",
na = c("NA","..",""))Eliminamos primera fila y segunda columna:
dt1 <- dt1[-1,-2]Asignamos nombre a la primera variable (columna):
colnames(dt1)[1] <- "MUNICIPIO"Separamos código y nombre de municipio y eliminamos la variable original:
dt1 <- dt1 %>%
dplyr::mutate(CMUN = stringr::str_sub(MUNICIPIO, start = 1, end = 5),
NMUN = stringr::str_sub(MUNICIPIO, start = 8, end = -1),
.before = MUNICIPIO) %>%
dplyr::select(-MUNICIPIO)Convertimos el dataset en formato long y añadimos la variable SEXO:
dt1_long <- dt1 %>%
tidyr::pivot_longer(cols = -c(1:2),
names_to = "EDAD",
values_to = "POB") %>%
mutate(SEXO = "Ambos sexos")Reemplazamos los NA por 0 (en este casi sí tiene sentido, pero no siempre es así):
dt1_long <- dt1_long %>%
dplyr::mutate(POB = tidyr::replace_na(POB, 0))Convertimos en numérica la variable EDAD, eliminando previamente el texto:
dt1_long <- dt1_long %>%
mutate(EDAD = as.numeric(str_extract_all(EDAD, pattern = "^\\d+")))Mostramos un resumen de las variables del dataset en el estado actual:
summary(dt1_long) CMUN NMUN EDAD
Length:819716 Length:819716 Min. : 0
Class :character Class :character 1st Qu.: 25
Mode :character Mode :character Median : 50
Mean : 50
3rd Qu.: 75
Max. :100
POB SEXO
Min. : 0.00 Length:819716
1st Qu.: 1.00 Class :character
Median : 5.00 Mode :character
Mean : 57.11
3rd Qu.: 21.00
Max. :59395.00 Otra forma de ver la clase de las variables y las primeras observaciones:
dplyr::glimpse(dt1_long)Rows: 819,716
Columns: 5
$ CMUN <chr> "44001", "44001", "44001", "44001", "44001", "44001",…
$ NMUN <chr> "Ababuj", "Ababuj", "Ababuj", "Ababuj", "Ababuj", "Ab…
$ EDAD <dbl> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,…
$ POB <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0,…
$ SEXO <chr> "Ambos sexos", "Ambos sexos", "Ambos sexos", "Ambos s…Generamos una variable con la edad por intervalos:
dt1_long <- dt1_long %>%
mutate(
EDAD_int = cut(
EDAD,
breaks = c(seq(0, 95, by = 5), Inf),
right = FALSE,
labels = c(
paste(seq(0, 90, 5), seq(4, 94, 5), sep = " - "),
"95 - 100+")
)
)
unique(dt1_long$EDAD_int) [1] 0 - 4 5 - 9 10 - 14 15 - 19 20 - 24 25 - 29
[7] 30 - 34 35 - 39 40 - 44 45 - 49 50 - 54 55 - 59
[13] 60 - 64 65 - 69 70 - 74 75 - 79 80 - 84 85 - 89
[19] 90 - 94 95 - 100+
20 Levels: 0 - 4 5 - 9 10 - 14 15 - 19 20 - 24 25 - 29 ... 95 - 100+Añadimos variables de interés al dataset (códigos y nombres de provincias y comunidades autónomas) usando datasets generados a partir de datos proporcionados en otras librerías (como mapSpain):
library(sf)
library(mapSpain)
ccaa <- mapSpain::esp_get_ccaa() %>%
sf::st_drop_geometry() %>%
select(codauto, ine.ccaa.name)
prov <- mapSpain::esp_get_prov() %>%
sf::st_drop_geometry() %>%
select(codauto, cpro, ine.prov.name)
#saveRDS(ccaa, "ccaa.rds")
#saveRDS(prov, "prov.rds")
#ccaa <- read_rds("ccaa.rds")
#prov <- read_rds("prov.rds")Pero antes debemos crear la variable CPRO:
dt1_long <- dt1_long %>%
mutate(CPRO = str_sub(CMUN,1,2))dt1_long <- right_join(prov, dt1_long, by = c("cpro" = "CPRO"))dt1_long <- right_join(ccaa, dt1_long, by = "codauto")Ahora habría que replicar el proceso para Hombres y Mujeres…
dt2 <- readxl::read_xlsx("censo.xlsx",
range = "DA8:GW8125",
na = c("NA","..",""))
dt2 <- dt2[-1,]
dt3 <- readxl::read_xlsx("censo.xlsx",
range = "GY8:KU8125",
na = c("NA","..",""))
dt3 <- dt3[-1,]municipios <- dt1 %>% select(1:2)Podemos replicar todos los pasos anteriores y crear una función:
arreglos <- function(data, sexo){
colnames(data)[1] <- "MUNICIPIO"
data <- cbind(municipios,data)
dt <- data %>%
pivot_longer(cols = -c(1:2),
names_to = "EDAD",
values_to = "POB") %>%
mutate(SEXO = sexo,
POB = tidyr::replace_na(POB, 0),
EDAD = as.numeric(str_extract_all(EDAD, pattern = "^\\d+"))) %>%
mutate(EDAD = tidyr::replace_na(EDAD, 0)) %>%
mutate(
EDAD_int = cut(
EDAD,
breaks = c(seq(0, 95, by = 5), Inf),
right = FALSE,
labels = c(
paste(seq(0, 90, 5), seq(4, 94, 5), sep = " - "),
"95 - 100+")
)
) %>%
mutate(CPRO = str_sub(CMUN,1,2))
dt <- right_join(prov, dt, by = c("cpro" = "CPRO"))
dt <- right_join(ccaa, dt, by = "codauto")
dt
}Aplicamos la función que hemos creado a los otros dos datasets:
dt2_long <- arreglos(data = dt2, sexo = "Hombres")
dt3_long <- arreglos(data = dt3, sexo = "Mujeres")Unimos los tres datasets:
data <- bind_rows(dt1_long,
dt2_long,
dt3_long)Y creamos algunas visualizaciones:
p <- ggplot(data = data %>% filter(CMUN == "28079", SEXO != "Ambos sexos"),
aes(x = EDAD, y = POB, color = SEXO)) +
geom_point()
p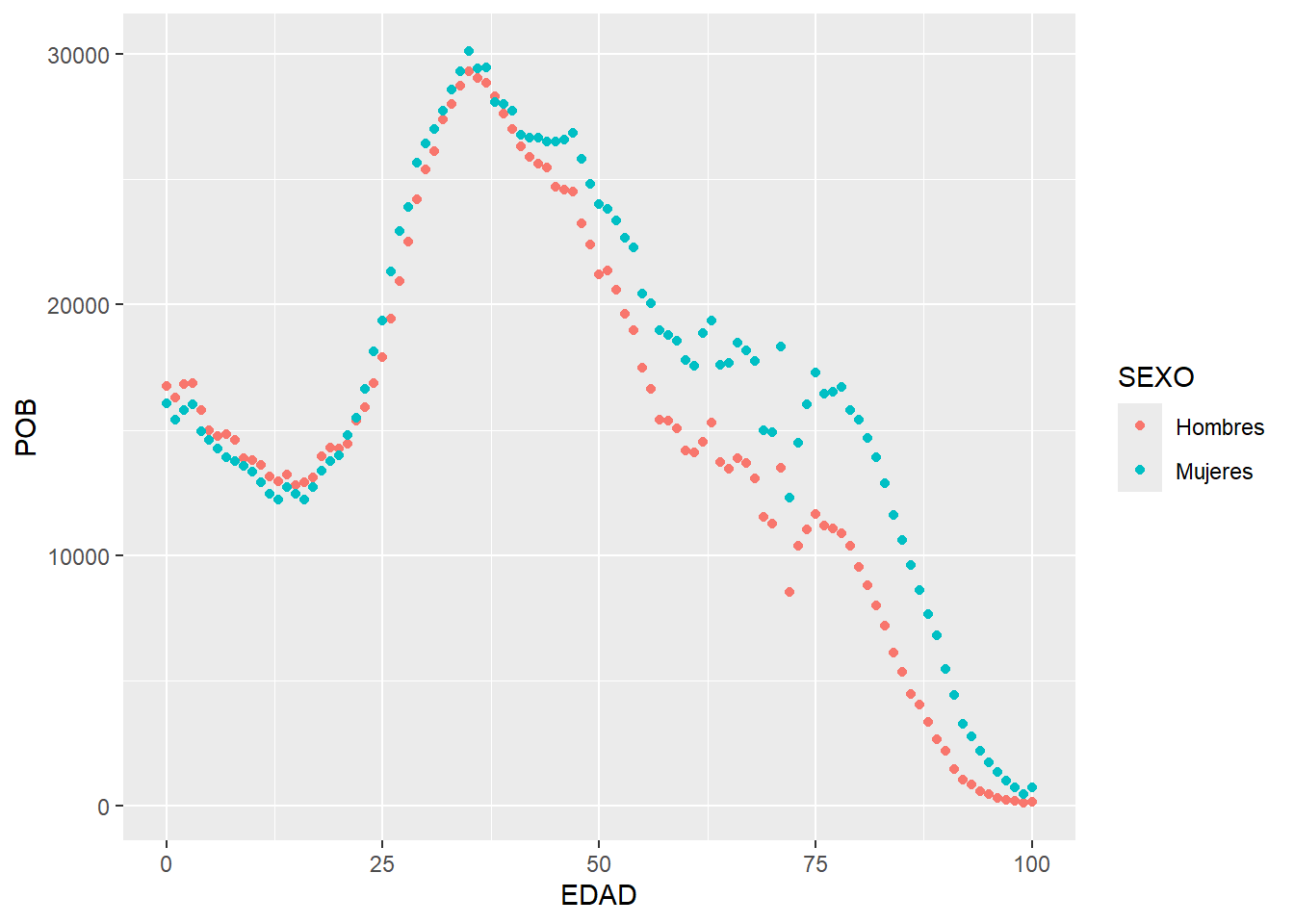
Podemos usar plotly para hacer interactivo el gráfico:
library(plotly)
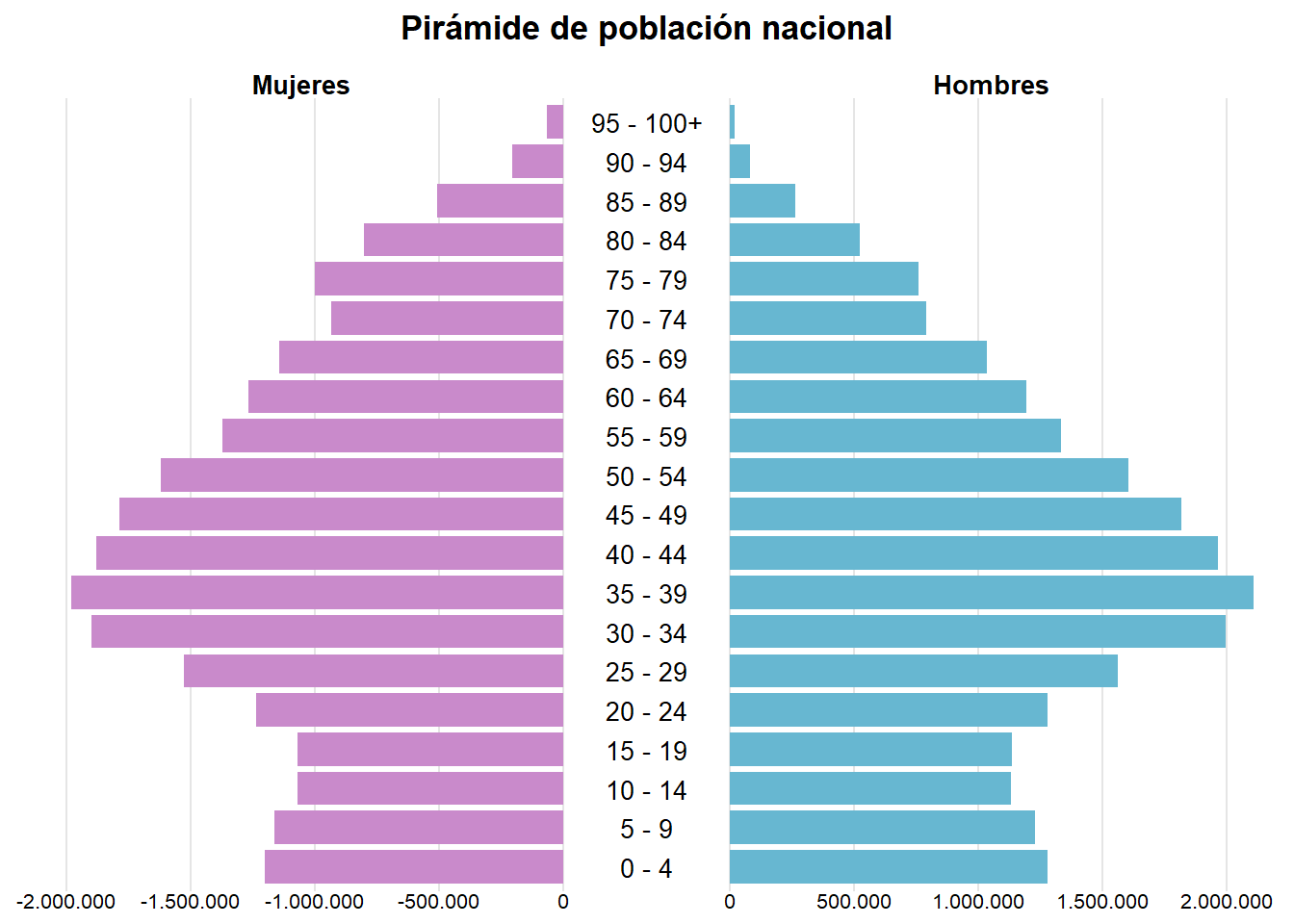
ggplotly(p)Y una pirámide de población, basada en este trabajo:
library(scales)
library(patchwork)
# 1. Agregar población nacional por sexo e intervalo de edad
piramide_data <- data %>%
filter(SEXO != "Ambos sexos") %>%
group_by(EDAD_int, SEXO) %>%
summarise(POB = sum(POB, na.rm = TRUE), .groups = "drop") %>%
mutate(
EDAD_int = fct_inorder(EDAD_int),
POB = if_else(SEXO == "Mujeres", -POB, POB)
)
# 2. Máximo para que ambos lados tengan la misma escala
max_pob <- piramide_data %>%
mutate(POB_abs = abs(POB)) %>%
summarise(max_pob = max(POB_abs, na.rm = TRUE)) %>%
pull(max_pob)
# 3. Etiquetas centrales
edad_labels <- piramide_data %>%
distinct(EDAD_int)
plot_mujeres <- piramide_data %>%
filter(SEXO == "Mujeres") %>%
ggplot(aes(x = POB, y = EDAD_int)) +
geom_col(fill = "#C98ACB", width = 0.85) +
scale_x_continuous(
labels = scales::label_number(big.mark = ".", decimal.mark = ","),
limits = c(-max_pob, 0)
) +
labs(x = NULL, y = NULL, title = "Mujeres") +
theme_void() +
theme(
axis.text.x = element_text(size = 8),
panel.grid.major.x = element_line(color = "grey90"),
plot.title = element_text(size = 10, hjust = 0.5, face = "bold")
)
plot_edades <- edad_labels %>%
ggplot(aes(x = 1, y = EDAD_int, label = EDAD_int)) +
geom_text(size = 3.5) +
theme_void()
plot_hombres <- piramide_data %>%
filter(SEXO == "Hombres") %>%
ggplot(aes(x = POB, y = EDAD_int)) +
geom_col(fill = "#67B7D1", width = 0.85) +
scale_x_continuous(
labels = scales::label_number(big.mark = ".", decimal.mark = ","),
limits = c(0, max_pob)
) +
labs(x = NULL, y = NULL, title = "Hombres") +
theme_void() +
theme(
axis.text.x = element_text(size = 8),
panel.grid.major.x = element_line(color = "grey90"),
plot.title = element_text(size = 10, hjust = 0.5, face = "bold")
)
# 4. Unir los tres gráficos
plot_mujeres + plot_edades + plot_hombres +
plot_layout(widths = c(7.5, 1.5, 7.5)) +
plot_annotation(
title = "Pirámide de población nacional",
theme = theme(
plot.title = element_text(hjust = 0.5, face = "bold")
)
)
Los datos que usaremos en este apartado están disponibles aquí.
library(dplyr)
library(stringr)
library(tidyr)
library(ggplot2)
library(readxl)
library(scales)
library(ggbump)
library(mapSpain)
library(sf)options(OutDec = ",")clean <- function(x) {
x <- str_to_lower(
str_replace_all(
stringi::stri_trans_general(x,"Latin-ASCII"),
"\\s+","")
)
}fn_plot1 <- function(df, titulo = NULL) {
# Renombrar la primera columna como CCAA
colnames(df)[1] <- "CCAA"
# Transformar los valores de CCAA
df <- df %>%
mutate(CCAA = case_when(
str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "esp") ~ "ESP",
str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "val|cv|gva") ~ "VAL",
str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "ue|eur") ~ "UE",
TRUE ~ CCAA
)) %>%
pivot_longer(cols = -CCAA, names_to = "ANYO", values_to = "value") %>%
mutate(
ANYO = as.integer(ANYO), # Convertir a número el eje X
CCAA = factor(CCAA,
levels = c("VAL", "ESP", "UE"),
labels = c("Comunitat Valenciana", "España", "Unión Europea"))
)
# Definir la paleta de colores
colores_ccaa <- c("España" = "#AA151B",
"Comunitat Valenciana" = "#000000",
"Unión Europea" = "#0033A0")
# Generar el gráfico
p <- df %>%
ggplot(aes(x = ANYO, y = value)) +
geom_line(aes(color = CCAA, group = CCAA), linewidth = 0.8) +
geom_point(aes(color = CCAA), shape = 21, size = 2.5, stroke = 1, fill = "white") +
scale_color_manual(values = colores_ccaa) +
labs(title = titulo, x = NULL, y = NULL) +
theme_bw() +
theme(legend.title = element_blank(),
legend.text = element_text(margin = margin(r = 15, unit = "pt")),
legend.position = "top",
panel.grid.minor = element_blank(),
axis.ticks = element_blank())
p
}# asigna un código a cada CCAA
cod_ccaa <- function(data){
data <- data %>%
mutate(ccaa_normalizada = clean(CCAA)) %>%
mutate(codauto = case_when(
str_detect(ccaa_normalizada, "anda") ~ "01",
str_detect(ccaa_normalizada, "arag") ~ "02",
str_detect(ccaa_normalizada, "astu") ~ "03",
str_detect(ccaa_normalizada, "balear") ~ "04",
str_detect(ccaa_normalizada, "canar") ~ "05",
str_detect(ccaa_normalizada, "canta") ~ "06",
str_detect(ccaa_normalizada, "leon") ~ "07",
str_detect(ccaa_normalizada, "manch") ~ "08",
str_detect(ccaa_normalizada, "catal") ~ "09",
str_detect(ccaa_normalizada, "valen") ~ "10",
str_detect(ccaa_normalizada, "extre") ~ "11",
str_detect(ccaa_normalizada, "gali") ~ "12",
str_detect(ccaa_normalizada, "madr") ~ "13",
str_detect(ccaa_normalizada, "murci") ~ "14",
str_detect(ccaa_normalizada, "navarra") ~ "15",
str_detect(ccaa_normalizada, "vasco|eus") ~ "16",
str_detect(ccaa_normalizada, "rioja") ~ "17",
str_detect(ccaa_normalizada, "ceut") ~ "18",
str_detect(ccaa_normalizada, "meli") ~ "19",
TRUE ~ CCAA)) %>%
select(-ccaa_normalizada) %>%
relocate(codauto, .before = CCAA)
}# TASA BRUTA DE TITULACION CFGS - comparativa GVA vs ESP -----------------------------------
# informe SEIE 2023
dt20a <- readRDS("datasets/dt20a.rds")
dt20a# A tibble: 2 × 11
...1 `2012` `2013` `2014` `2015` `2016` `2017` `2018` `2019`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 España 22.6 24.4 27.3 28.5 27.8 26.7 29.3 29.2
2 Comunidad… 26 32.2 30.9 31 30.4 28.2 28.8 27.5
# ℹ 2 more variables: `2020` <dbl>, `2021` <dbl>(p20a <- fn_plot1(dt20a))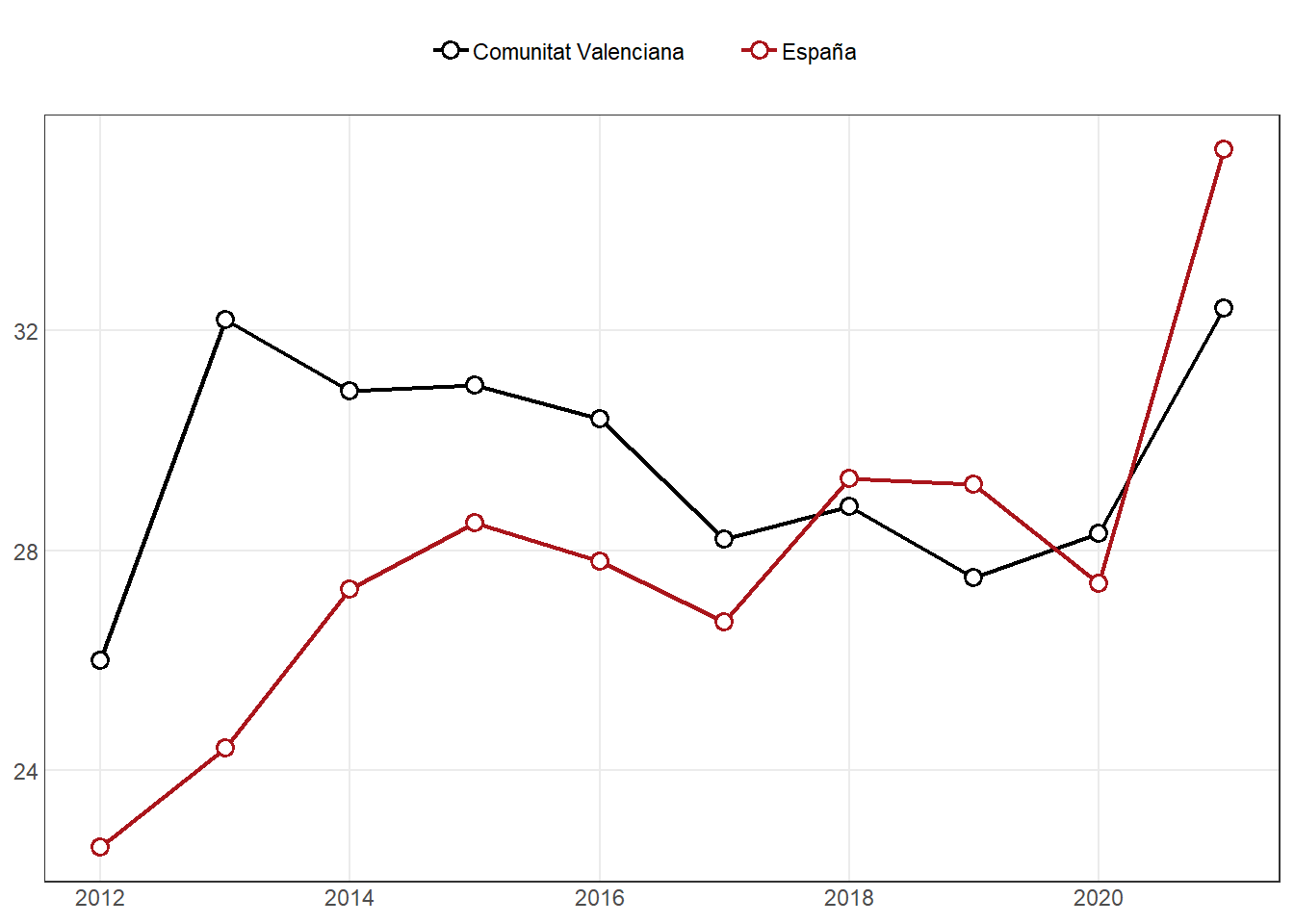
# plot paso a paso
df <- dt20a
colnames(df)[1] <- "CCAA"
df <- df %>%
mutate(CCAA = case_when(
str_detect(str_to_lower(str_replace_all(CCAA, " ", "")), "esp") ~ "ESP",
str_detect(str_to_lower(str_replace_all(CCAA, " ", "")), "val|cv|gva") ~ "VAL",
str_detect(str_to_lower(str_replace_all(CCAA, " ", "")), "ue|eur") ~ "UE",
#str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "esp") ~ "ESP",
#str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "val|cv|gva") ~ "VAL",
#str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "ue|eur") ~ "UE",
TRUE ~ CCAA
)) %>%
pivot_longer(cols = -CCAA, names_to = "ANYO", values_to = "value") %>%
mutate(
ANYO = as.integer(ANYO), # Convertir a número el eje X
CCAA = factor(CCAA,
levels = c("VAL", "ESP", "UE"),
labels = c("Comunitat Valenciana", "España", "Unión Europea"))
)
colores_ccaa <- c("España" = "#AA151B",
"Comunitat Valenciana" = "#000000",
"Unión Europea" = "#0033A0")
p <- df %>%
ggplot(aes(x = ANYO, y = value)) +
geom_line(aes(color = CCAA, group = CCAA), linewidth = 0.8) +
geom_point(aes(color = CCAA), shape = 21, size = 2.5, stroke = 1, fill = "white") +
scale_color_manual(values = colores_ccaa) +
labs(title = NULL, x = NULL, y = NULL) +
theme_bw() +
theme(legend.title = element_blank(),
legend.text = element_text(margin = margin(r = 15, unit = "pt")),
legend.position = "top",
panel.grid.minor = element_blank(),
axis.ticks = element_blank())
p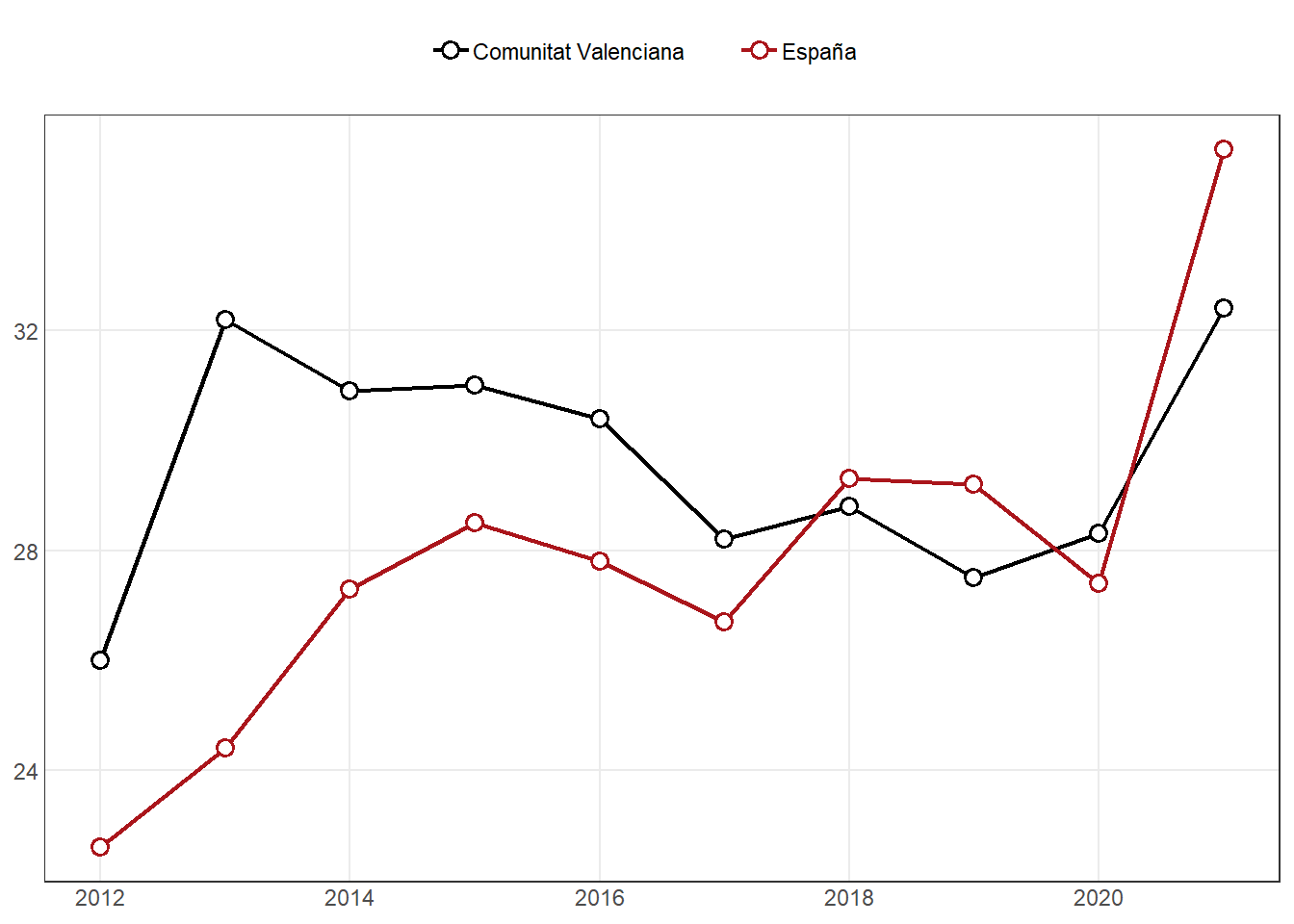
# TASA BRUTA DE TITULACION CFGS - comparativa comunidades en 2021 --------------------------
dt20b <- readRDS("datasets/dt20b.rds")
dt20b# A tibble: 20 × 2
...1 `2021`
<chr> <dbl>
1 Asturias (Principado de) 44.6
2 País Vasco 43.5
3 Galicia 42.3
4 Cantabria 40.9
5 Canarias 37.6
6 Cataluña 37.3
7 Andalucía 36.8
8 Castilla y León 35.9
9 España 35.3
10 Rioja (La) 33.7
11 Murcia (Región de ) 33.4
12 Aragón 33.2
13 Madrid (Comunidad de) 33.1
14 Comunidad Valenciana 32.4
15 Extremadura 30.7
16 Castilla-La Mancha 30.1
17 Navarra (Comunidad Foral de) 27
18 Melilla 25.3
19 Balears (Illes) 21.1
20 Ceuta 19.6#(p20b <- fn_plot2(dt20b, m=1.2, reverse_order = F))# plot paso a paso
df <- dt20b
# Renombrar columnas
colnames(df) <- c("CCAA", "value")
df$value <- as.numeric(df$value)
# Definir colores personalizados
col_gva <- "#000000" # Negro para Comunitat Valenciana
col_esp <- "#AA151B" # Rojo para España
col_ue <- "#0033A0" # Azul para UE
col_ccaa <- "gray50" # Color genérico para otras CCAA
# Asignar colores según la comunidad autónoma
df <- df %>%
mutate(color = case_when(
str_detect(
str_to_lower(
str_replace_all(
stringi::stri_trans_general(
CCAA,
"Latin-ASCII"
),
"\\s+",""
)
),
"esp"
) ~ col_esp,
str_detect(clean(CCAA), "val|cv|gva") ~ col_gva,
str_detect(clean(CCAA), "ue|eur") ~ col_ue,
TRUE ~ col_ccaa
))
# Ordenar de mayor a menor para la visualización
df <- df %>%
filter(!is.na(CCAA)) %>%
arrange(desc(value)) %>%
mutate(CCAA = factor(CCAA, levels = CCAA))
# Crear el gráfico
p20b <- ggplot(df, aes(x = value, y = CCAA, color = color)) +
geom_segment(aes(x = 0, xend = value, yend = CCAA), linewidth = 0.8) +
geom_point(aes(x = value), shape = 21, size = 2.5, stroke = 1, fill = "white") +
geom_text(aes(label = paste0(value," %")), size = 3, color = "black", hjust = -0.4) +
labs(x = NULL, y = NULL, title = NULL) +
scale_x_continuous(limits = c(0, 1.1*max(df$value)),
expand = c(0, 0),
labels = scales::label_number(decimal.mark = ",", big.mark = ".")) +
scale_y_discrete(position = "left") +
scale_color_identity() +
theme_classic() +
theme(
plot.title = element_text(hjust = 0.5),
axis.ticks = element_blank(),
panel.grid = element_blank(),
axis.line = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_text(size = 9))
p20b
# P21 - TASA BRUTA DE TITULACION CFGM ------------------------------------------------------
# informe SEIE 2023
dt21a <- readRDS("datasets/dt21a.rds")
dt21a# A tibble: 2 × 11
...1 `2012` `2013` `2014` `2015` `2016` `2017` `2018` `2019`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 España 22.4 22.2 23.9 24.7 24.7 23.5 22.7 23.3
2 Comunidad… 26.6 29.5 29.2 28.9 28.7 26.4 25.6 26.5
# ℹ 2 more variables: `2020` <dbl>, `2021` <dbl>(p21a <- fn_plot1(dt21a))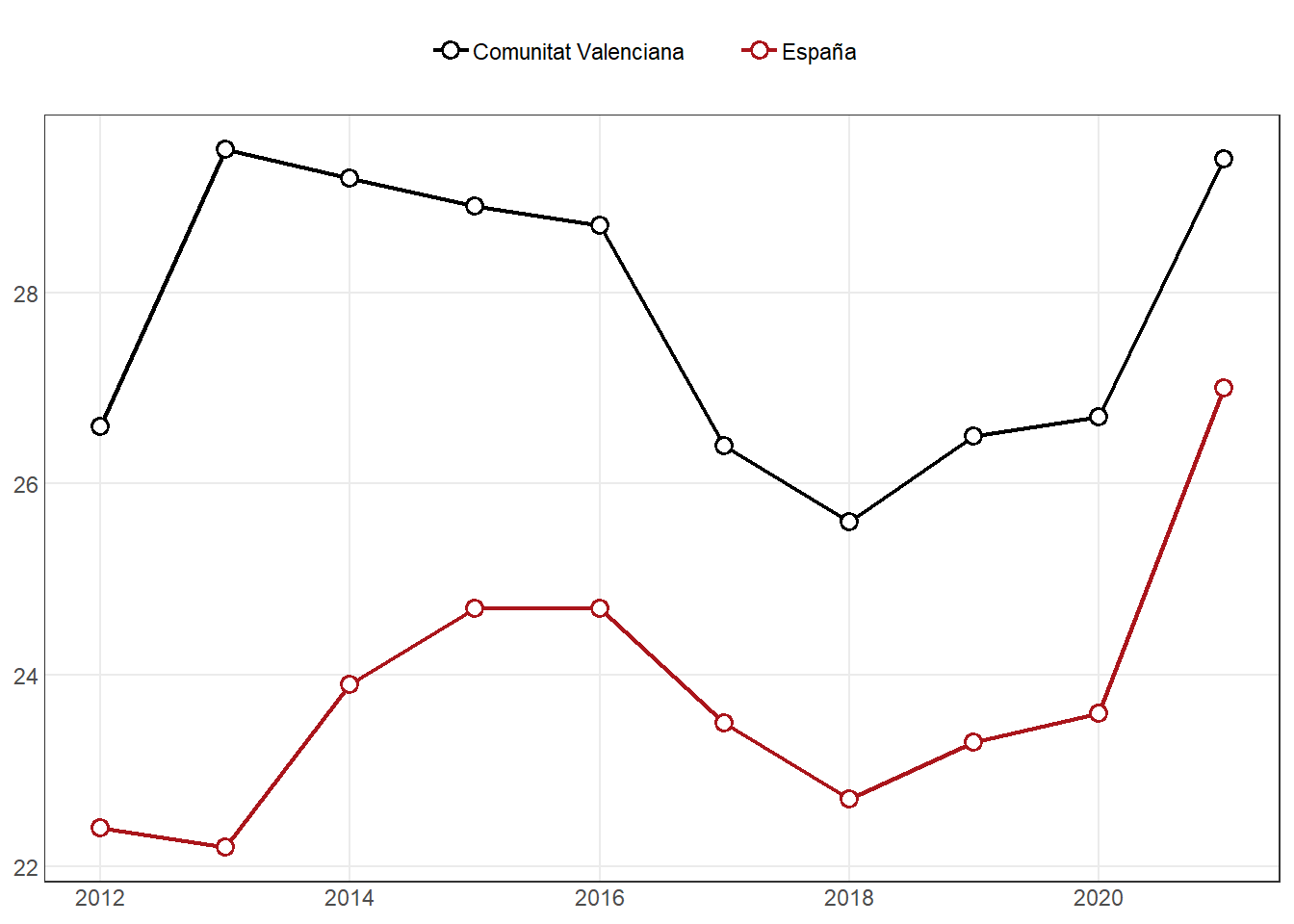
dt21b <- readRDS("datasets/dt21b.rds")
dt21b# A tibble: 20 × 2
...1 `2021`
<chr> <dbl>
1 Cantabria 32.1
2 Galicia 31.4
3 Asturias (Principado de) 31
4 Cataluña 29.9
5 Extremadura 29.5
6 Comunidad Valenciana 29.4
7 Rioja (La) 29.2
8 Aragón 28.6
9 Castilla y León 27.8
10 Balears (Illes) 27.2
11 España 27
12 Navarra (Comunidad Foral de) 27
13 Andalucía 26.8
14 País Vasco 26.8
15 Castilla-La Mancha 26.2
16 Canarias 26
17 Murcia (Región de ) 25.8
18 Ceuta 22.9
19 Melilla 20.1
20 Madrid (Comunidad de) 20 #(p21b <- plot_map(dt21b, paleta = "GnBu"))# plot paso a paso
data <- dt21b
head(data)# A tibble: 6 × 2
...1 `2021`
<chr> <dbl>
1 Cantabria 32.1
2 Galicia 31.4
3 Asturias (Principado de) 31
4 Cataluña 29.9
5 Extremadura 29.5
6 Comunidad Valenciana 29.4colnames(data) <- c("CCAA", "value")
data$value <- as.numeric(data$value)
data <- cod_ccaa(data)
head(data)# A tibble: 6 × 3
codauto CCAA value
<chr> <chr> <dbl>
1 06 Cantabria 32.1
2 12 Galicia 31.4
3 03 Asturias (Principado de) 31
4 09 Cataluña 29.9
5 11 Extremadura 29.5
6 10 Comunidad Valenciana 29.4data <- left_join(mapSpain::esp_get_ccaa(), data, by="codauto") %>%
select(c("codauto","CCAA","value")) %>%
filter(!codauto %in% c("18","19"))
brks <- quantile(data$value, probs = seq(0, 1, 0.25), na.rm = TRUE)
brks <- seq(min(data$value, na.rm = TRUE), max(data$value, na.rm = TRUE), length.out = 6)
labels <- paste0(format(round(brks[-length(brks)], 1), nsmall = 1), " - ",
format(round(brks[-1], 1), nsmall = 1))
data$class <- cut(data$value, breaks = brks, labels = labels, include.lowest = TRUE)
p21b <- data %>% ggplot() +
geom_sf(aes(fill = class), color = "grey70", lwd = 0.1) +
geom_sf(data = esp_get_can_box(), color = "grey70", lwd = 0.2) +
labs(title = NULL) +
geom_sf_label(aes(label = number(value, accuracy = 0.1, decimal.mark = ",")),
fun.geometry = st_centroid,
label.size = NA, fill = "white", alpha = .7, size = 3) +
scale_fill_brewer(name=NULL, palette = "Spectral",
guide=guide_legend(direction="horizontal",
nrow = 1,
title.position="top",
title.hjust=.5,
label.position="bottom",
label.hjust=.5,
keywidth=3.5,
keyheight=.5)) +
theme_void() +
theme(plot.title=element_text(hjust=0.5),
legend.position=c(0.7, 0.1)
)
p21b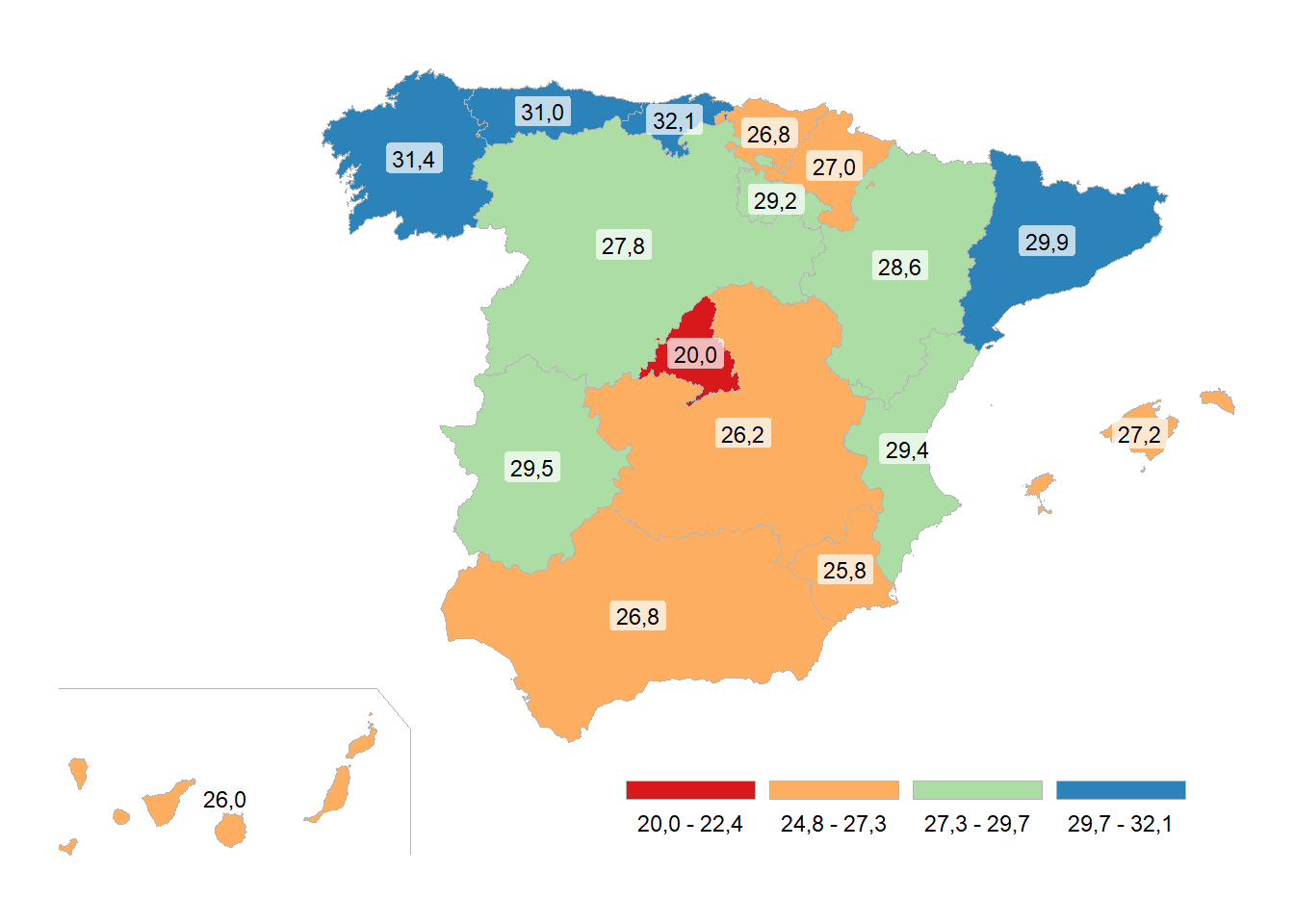
# message("Para ver todas las paletas de colores disponibles ejecuta RColorBrewer::display.brewer.all()")library(cowplot)
p21 <- cowplot::plot_grid(p21a, NULL, p21b, nrow = 1, rel_widths = c(1, 0.1, 1.2))
p21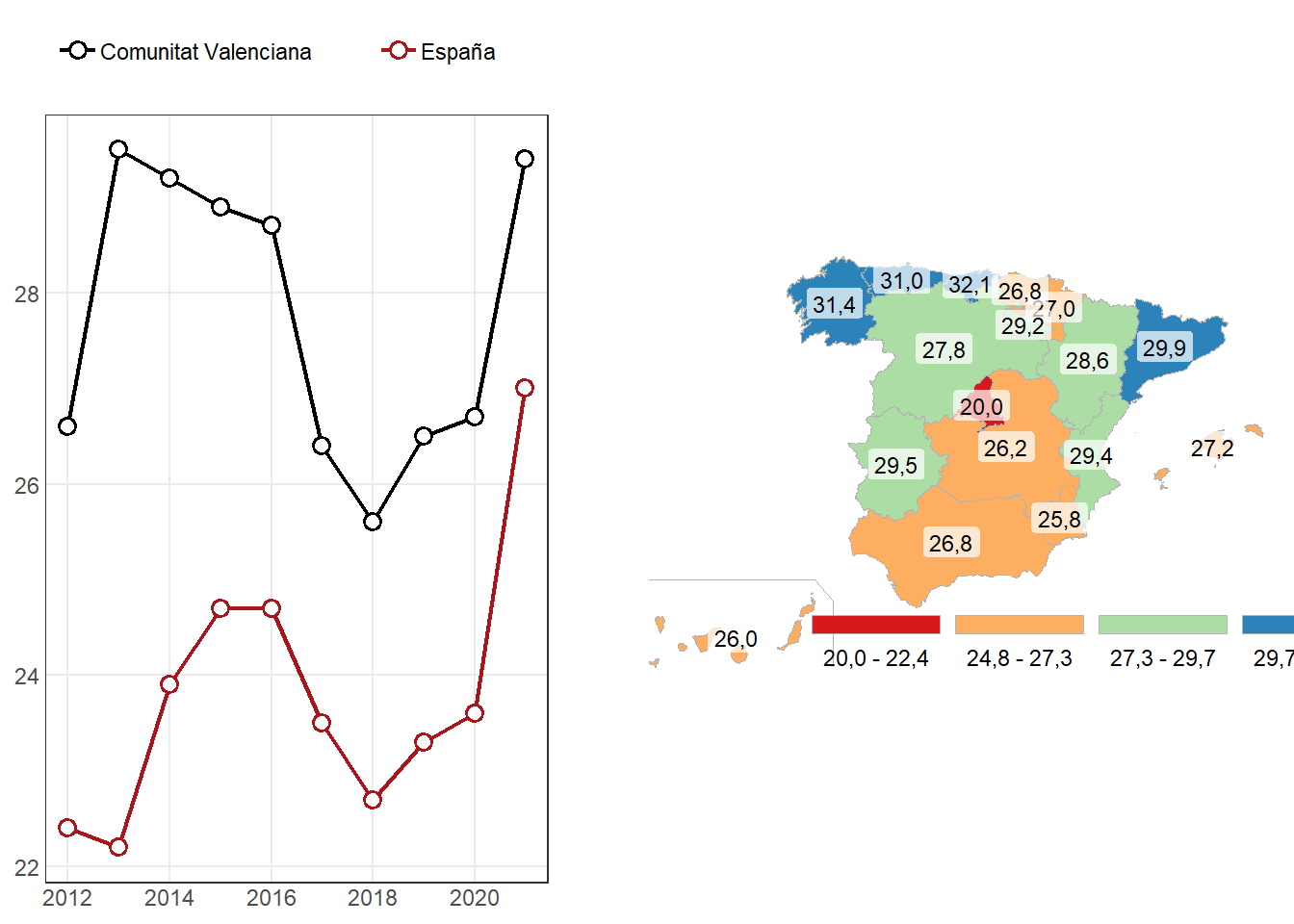
# SATISFACCION ENSEÑANZA PUBLICA -----------------------------------------------------------
# Encuestas CIS sobre satisfaccion servicios públicos (un estudio cada año, en junio o julio, desde 2010)
dt29 <- readRDS("datasets/dt29.rds")
dt29# A tibble: 20 × 6
CCAA ANYO `Muy satisfecho/a` Bastante satisfecho/…¹
<chr> <dbl> <dbl> <dbl>
1 Comunitat Valenc… 2010 7.14 62.2
2 Comunitat Valenc… 2011 6.33 53.6
3 Comunitat Valenc… 2012 4.78 48.6
4 Comunitat Valenc… 2013 2.77 36.4
5 Comunitat Valenc… 2014 4.55 32.6
6 Comunitat Valenc… 2015 3.46 34.2
7 Comunitat Valenc… 2016 6.09 38.7
8 Comunitat Valenc… 2017 4.70 35.9
9 Comunitat Valenc… 2018 8.94 50.8
10 Comunitat Valenc… 2023 11.8 42.3
11 España 2010 7.06 55.8
12 España 2011 7.76 57.3
13 España 2012 7.51 46.3
14 España 2013 5.08 38.5
15 España 2014 5.32 39.9
16 España 2015 5.54 41.6
17 España 2016 5.16 42.3
18 España 2017 4.89 43.7
19 España 2018 6.58 47.1
20 España 2023 10.5 43.5
# ℹ abbreviated name: ¹`Bastante satisfecho/a`
# ℹ 2 more variables: `Poco satisfecho/a` <dbl>,
# `Nada satisfecho/a` <dbl>#(p29 <- fn_plot3(dt29))# plot paso a paso
datos <- dt29
head(datos)# A tibble: 6 × 6
CCAA ANYO `Muy satisfecho/a` Bastante satisfecho/…¹
<chr> <dbl> <dbl> <dbl>
1 Comunitat Valenci… 2010 7.14 62.2
2 Comunitat Valenci… 2011 6.33 53.6
3 Comunitat Valenci… 2012 4.78 48.6
4 Comunitat Valenci… 2013 2.77 36.4
5 Comunitat Valenci… 2014 4.55 32.6
6 Comunitat Valenci… 2015 3.46 34.2
# ℹ abbreviated name: ¹`Bastante satisfecho/a`
# ℹ 2 more variables: `Poco satisfecho/a` <dbl>,
# `Nada satisfecho/a` <dbl>lvls = colnames(datos)[3:6]
# Transformar datos con pivot_longer()
datos_long <- datos %>%
pivot_longer(cols = -c(CCAA, ANYO),
names_to = "option",
values_to = "value") %>%
# Convertir option a factor con niveles ordenados
mutate(option = factor(option, levels = lvls))
# Crear el gráfico
p29 <- datos_long %>%
ggplot(aes(x = as.character(ANYO), y = value, fill = option)) +
scale_y_continuous(expand = c(0, 0)) +
# Barras apiladas
geom_col(alpha = .8, width = 0.8) +
# Etiquetas dentro de las barras
geom_text(aes(label = ifelse(value >= 2,
scales::label_number(accuracy = 0.1, decimal.mark = ",", big.mark = ".")(value),
"")),
position = position_stack(vjust = 0.5),
size = 3, color = "black") +
# Colores manuales para las categorías
scale_fill_manual(values = c("Muy satisfecho/a" = "#5AB4AC",
"Bastante satisfecho/a" = "#ACD9D5",
"Poco satisfecho/a" = "#EBD9B2",
"Nada satisfecho/a" = "#D8B365")) +
guides(fill = guide_legend(nrow = 1)) +
# Facetas por CCAA
facet_wrap(~ CCAA, nrow=1) +
# Estilo del gráfico
theme_classic() +
theme(axis.title.x = element_blank(),
axis.ticks.x = element_blank(),
axis.line.x = element_blank(),
axis.text.x = element_text(),
axis.title.y = element_blank(),
axis.ticks.y = element_blank(),
axis.line.y = element_blank(),
axis.text.y = element_blank(),
legend.text = element_text(size = 11),
legend.title = element_blank(),
legend.position = "top",
legend.direction = "horizontal",
strip.background = element_blank(),
strip.text.x = element_text(size = 12, face = "bold"))
p29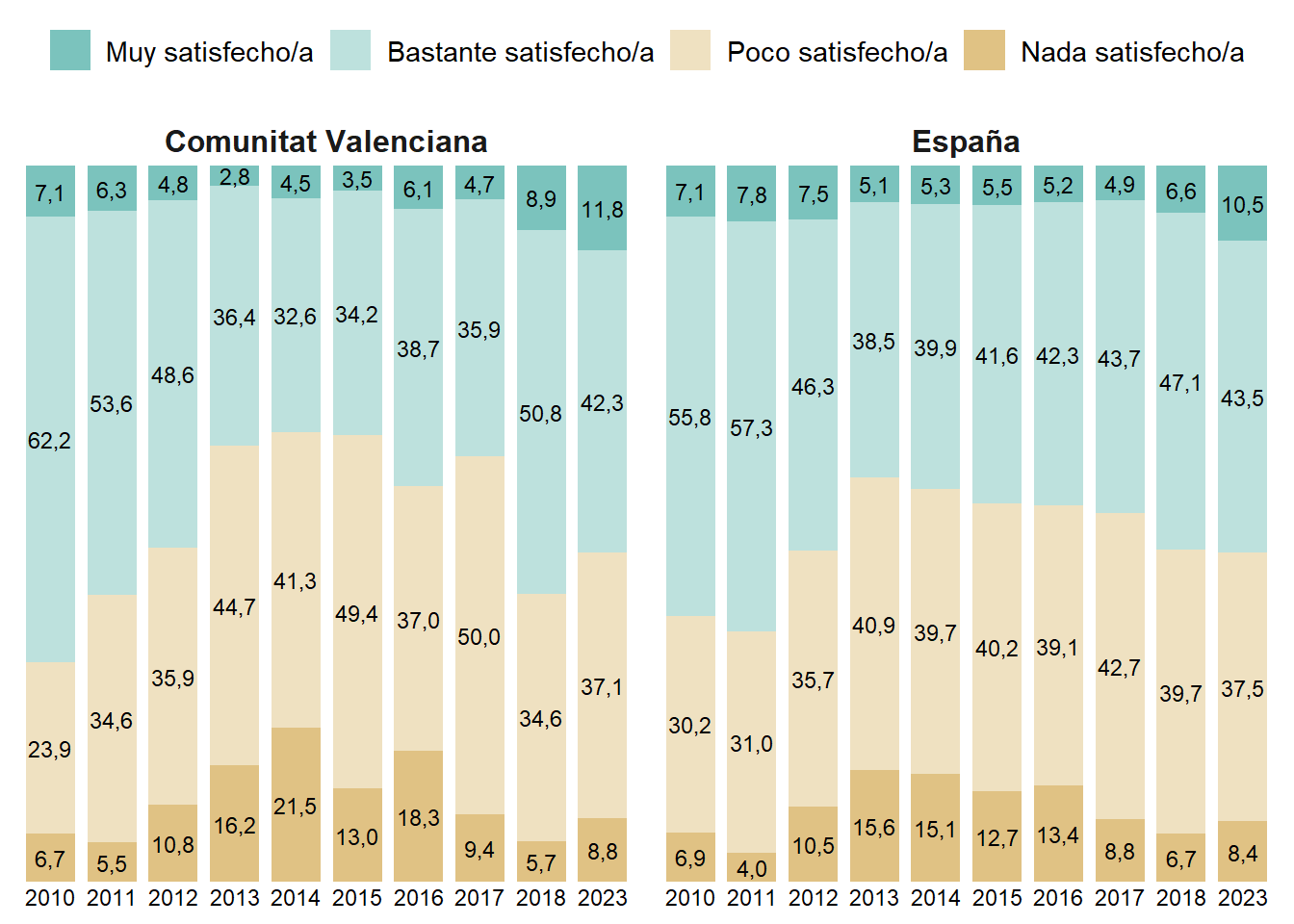
# P30 - AMPI EDUCACION ---------------------------------------------------------------------
dt30a <- readRDS("datasets/dt30a.rds")
dt30a# A tibble: 18 × 12
AMPI `2012` `2013` `2014` `2015` `2016` `2017` `2018` `2019`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 España 100 99.5 102. 103. 103. 103. 104. 104.
2 Andalucía 97.8 96.7 97.3 98.6 99.1 99.1 99.0 100.
3 Aragón 102. 101. 104. 104. 106. 106. 106. 105.
4 Asturias… 103. 104. 109. 108. 108. 107. 105. 105.
5 Balears,… 96.5 96.9 98.7 97.8 99.0 101. 100. 101.
6 Canarias 95.2 95.5 97.7 99.6 100. 101. 101. 102.
7 Cantabria 103. 102. 107. 107. 107. 106. 109. 109.
8 Castilla… 102. 100.0 103. 104. 104. 104. 104. 106.
9 Castilla… 96.3 95.8 98.6 99.1 99.3 100. 101. 101.
10 Cataluña 101. 100. 103. 104. 104. 105. 106. 107.
11 Comunita… 99.3 99.6 101. 102. 103. 103. 104. 105.
12 Extremad… 96.1 94.6 99.0 100. 100. 100. 100. 101.
13 Galicia 101. 102. 104. 105. 105. 106. 105. 107.
14 Madrid, … 103. 102. 103. 104. 104. 104. 105. 105.
15 Murcia, … 97.9 97.8 98.5 100. 102. 101. 102. 102.
16 Navarra,… 103. 103. 106. 107. 106. 106. 107. 109.
17 País Vas… 109. 109. 109. 111. 111. 111. 110. 111.
18 Rioja, La 104. 102. 103. 105. 104. 103. 101. 103.
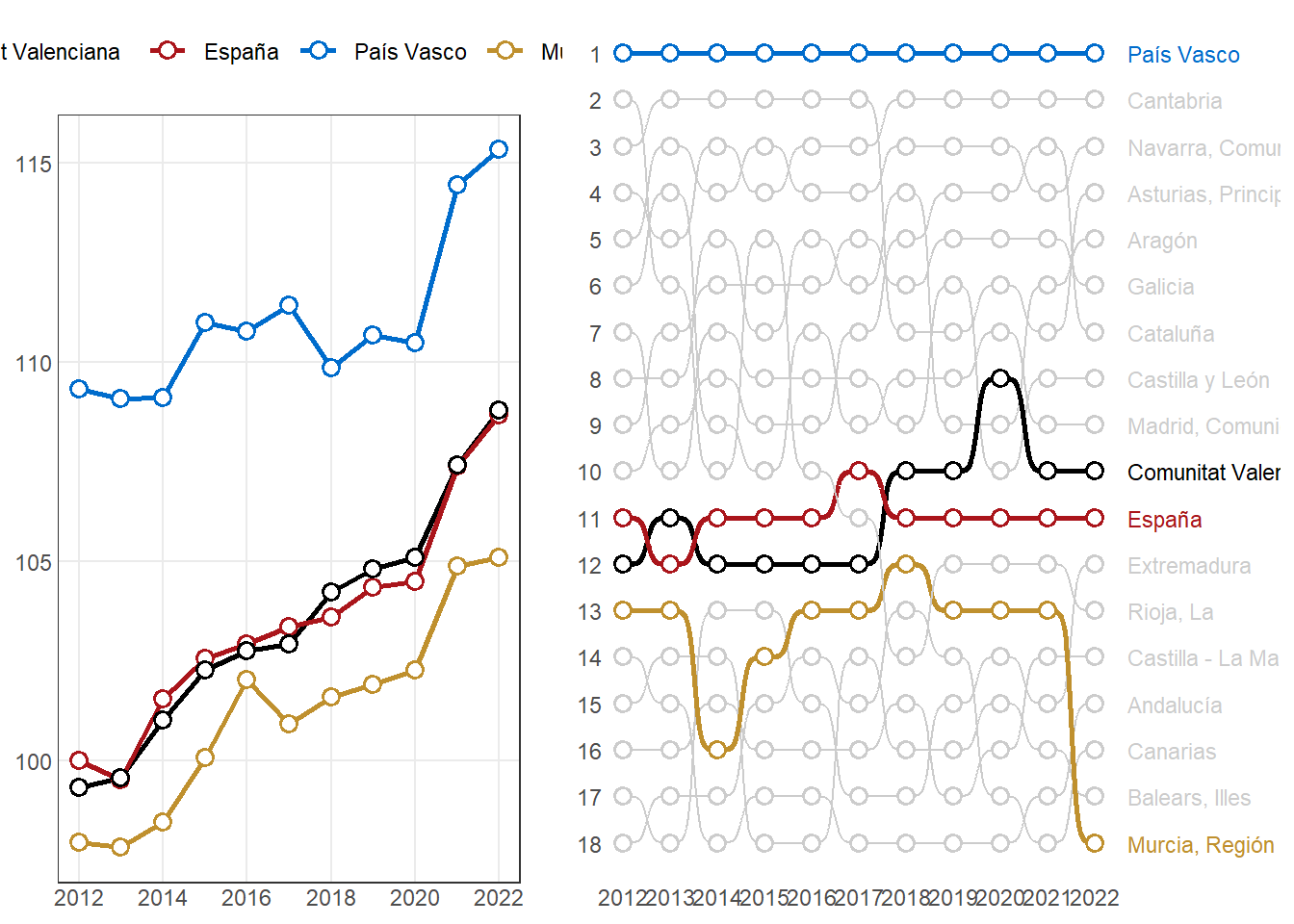
# ℹ 3 more variables: `2020` <dbl>, `2021` <dbl>, `2022` <dbl>#(p30a <- fn_plot4(dt30a))# plot paso a paso
df <- dt30a
# Renombrar la primera columna como CCAA
colnames(df)[1] <- "CCAA"
# Filtrar las CCAA que contienen "esp" o "val" y las de máximo/mínimo en 2022
df_filtrado <- df %>%
filter(
str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "esp|val") |
`2022` == max(`2022`) |
`2022` == min(`2022`)
) %>%
# Transformar el dataframe a formato largo
pivot_longer(cols = -CCAA, names_to = "ANYO", values_to = "value") %>%
# Convertir años a numéricos y definir los factores correctamente
mutate(ANYO = as.integer(ANYO))
ccaa_max <- df$CCAA[df$`2022` == max(df$`2022`)]
ccaa_min <- df$CCAA[df$`2022` == min(df$`2022`)]
# Definir la paleta de colores para los seleccionados
colores_ccaa <- c("España" = "#AA151B",
"Comunitat Valenciana" = "#000000")
if (ccaa_max %in% df_filtrado$CCAA) {
colores_ccaa <- c(colores_ccaa, setNames("#006CCC", ccaa_max))
}
if (ccaa_min %in% df_filtrado$CCAA) {
colores_ccaa <- c(colores_ccaa, setNames("#BF902E", ccaa_min))
}
# Definir el orden de las CCAA en el gráfico
df_filtrado <- df_filtrado %>%
mutate(CCAA = factor(CCAA, levels = c("Comunitat Valenciana", "España", ccaa_max, ccaa_min)))
# Generar el gráfico
p30a <- df_filtrado %>%
ggplot(aes(x = ANYO, y = value)) +
geom_line(aes(color = CCAA, group = CCAA), linewidth = 1) +
geom_point(aes(color = CCAA), shape = 21, size = 2.5, stroke = 1, fill = "white") +
scale_color_manual(values = colores_ccaa) +
scale_x_continuous(breaks = scales::breaks_pretty(n = 7)) +
labs(title = NULL, x = NULL, y = NULL) +
theme_bw() +
theme(legend.title = element_blank(),
legend.text = element_text(),
legend.position = "top",
panel.grid.minor = element_blank(),
axis.ticks = element_blank())
p30a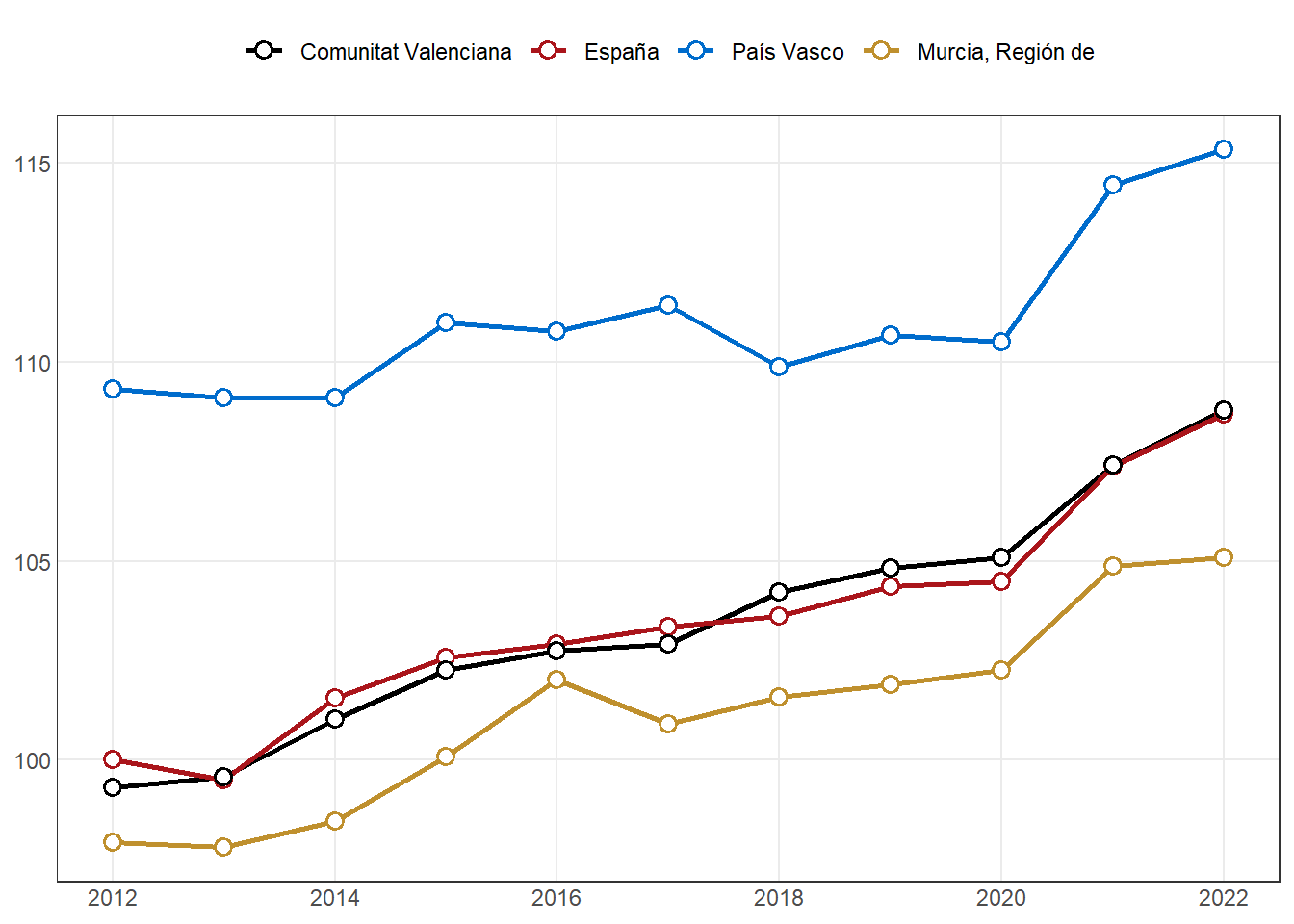
dt30b <- readRDS("datasets/dt30b.rds")
dt30b# A tibble: 18 × 12
AMPI `2012` `2013` `2014` `2015` `2016` `2017` `2018` `2019`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 España 11 12 11 11 11 10 11 11
2 Andalucía 14 15 18 17 17 18 18 18
3 Aragón 8 8 5 7 5 6 4 9
4 Asturias… 3 2 2 2 2 2 7 7
5 Balears,… 15 14 14 18 18 14 16 16
6 Canarias 18 17 17 15 14 15 13 14
7 Cantabria 4 5 3 4 3 3 2 2
8 Castilla… 16 16 15 16 16 16 15 17
9 Castilla… 7 10 7 8 8 8 9 6
10 Cataluña 10 9 8 9 9 7 5 4
11 Comunita… 12 11 12 12 12 12 10 10
12 Extremad… 17 18 13 13 15 17 17 15
13 Galicia 9 7 6 6 6 5 6 5
14 Madrid, … 6 4 9 10 7 9 8 8
15 Murcia, … 13 13 16 14 13 13 12 13
16 Navarra,… 5 3 4 3 4 4 3 3
17 País Vas… 1 1 1 1 1 1 1 1
18 Rioja, La 2 6 10 5 10 11 14 12
# ℹ 3 more variables: `2020` <dbl>, `2021` <dbl>, `2022` <dbl>#(p30b <- fn_plot5(dt30b))# plot paso a paso
df <- dt30b %>% rename("CCAA" = 1)
# Último año disponible
year_col <- df %>%
select(-CCAA) %>%
names() %>%
as.integer() %>%
max(na.rm = TRUE) %>%
as.character()
# CCAA con mejor y peor posición en el último año
ccaa_extremos <- df %>%
select(CCAA, all_of(year_col)) %>%
summarise(
ccaa_max = CCAA[which.max(.data[[year_col]])],
ccaa_min = CCAA[which.min(.data[[year_col]])]
)
ccaa_max <- ccaa_extremos$ccaa_max
ccaa_min <- ccaa_extremos$ccaa_min
# Transformar a formato largo
df_long <- df %>%
pivot_longer(cols = -CCAA, names_to = "FECHA", values_to = "posicion") %>%
# Convertir años a formato Date
mutate(FECHA = ymd(paste0(FECHA, "-01-01")),
cluster = case_when(
str_detect(str_to_lower(str_replace_all(CCAA, "\\s+", "")), "esp|val") ~ CCAA,
CCAA == ccaa_max ~ "mejor",
CCAA == ccaa_min ~ "peor",
TRUE ~ "CCAA"
))
# Definir la paleta de colores con los destacados y el resto en gris
colores_ccaa <- c(
"España" = "#AA151B",
"Comunitat Valenciana" = "#000000",
"mejor" = "#BF902E", # Azul para la mejor CCAA en 2022
"peor" = "#006CCC", # Marrón para la peor CCAA en 2022
"CCAA" = "grey80" # Gris para el resto de CCAA
)
anchos_linea <- c(
"CCAA" = 0.5,
"España" = 0.9,
"Comunitat Valenciana" = 0.9,
"mejor" = 0.9,
"peor" = 0.9
)
# Generar el gráfico
#pak::pak("davidsjoberg/ggbump")
library(ggbump)
p30b <- df_long %>%
ggplot(aes(x = FECHA, y = posicion, group = CCAA)) +
ggbump::geom_bump(aes(color = cluster, linewidth = cluster)) +
geom_point(aes(color = cluster), shape = 21, size = 2.5, stroke = 1, fill = "white") +
scale_color_manual(values = colores_ccaa) +
scale_linewidth_manual(values = anchos_linea) +
scale_y_reverse(breaks = seq(1, 20, 1)) +
scale_x_date(expand = c(0, 0),
limits = c(ymd("2011-09-01"), ymd("2025-12-01")),
breaks = seq(ymd("2012-01-01"), ymd("2022-01-01"), "1 year"),
labels = as.character(2012:2022)) +
theme_bw() +
# Agregar etiquetas en 2022
geom_text(data = df_long %>% filter(FECHA == ymd("2022-01-01")) %>% arrange(posicion),
aes(color = cluster, label = CCAA),
size = 3, nudge_x = 250, hjust = 0) +
# Ajustar tema
theme(
axis.title = element_blank(),
axis.ticks = element_blank(),
axis.line = element_blank(),
panel.border = element_blank(),
panel.grid = element_blank(),
legend.position = "none"
)
p30b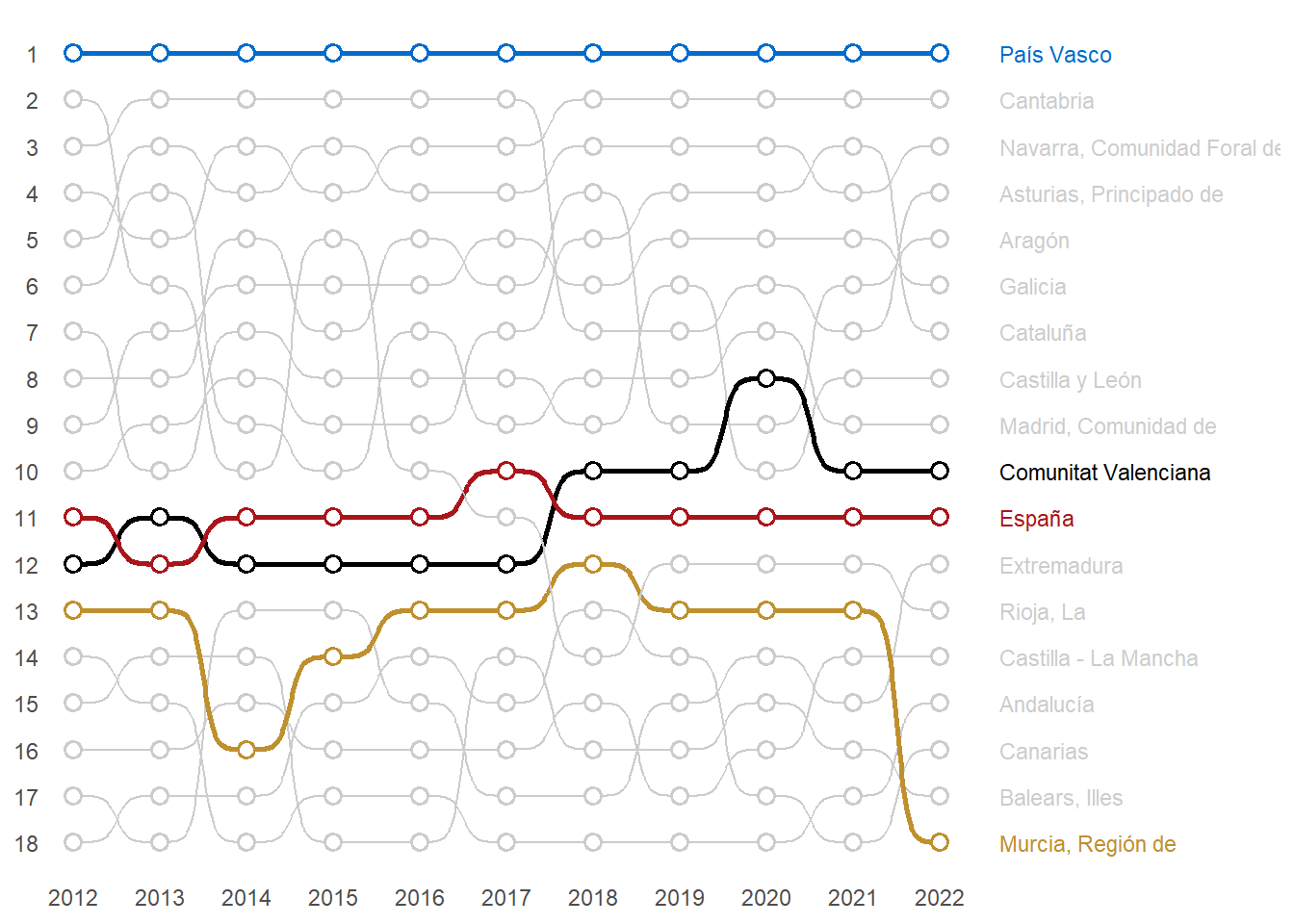
p30 <- cowplot::plot_grid(p30a, NULL, p30b, nrow = 1, rel_widths = c(0.95, 0.05, 1.3))
p30