Atención:
Instalados desde el día 22/2/2007 nuevos ordenadores.
Llamados erwin, mulliken, koopmans,hund, herzberg.
En breve se publicará la web, sobre la utilización de los mismos.
|
Descripción
Hardware
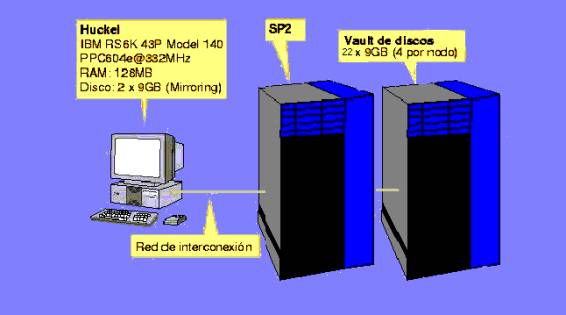
Las características más relevantes del nuevo equipo son:
- Estación de control:
- Nombre: Huckel (Spsrv por el lado del SP2).
- Modelo: IBM RS6K 43P Model 140.
- Procesador: PPC604e@332MHz.
- 128MB de memoria RAM.
- 2 discos de 9GB en mirroring (área útil 9GB y sistema operativo redundante).
- Nodos del SP2: Dos nodos de las siguientes características:
- Nombre: Spn1, Spn2, Spn3, Spn4 y Spn5.
- Modelo: Thin.
- Procesadores: 4 x Power3@375MHz (1.4 GFlops de velocidad de pico).
- 2 discos de 9GB en mirroring (área útil 9GB y sistema operativo redundante).
- Relación de la Memoria Ram. Instalada en cada Nodo.
- Spn1 Tienen instalada 3Gb de Memoria RAM
- Spn2 y Spn4 Tienen instalada
4Gb de Memoria RAM
- Spn3 y Spn5 Tiene instalada 8Gb de Memoria Ram
- Del nodo Spn1 con número de discos 8 de tamaño 9 GB con un área de Scrach 70 Gb en Total U2W 10000RPM (bus de 80MB/s) en stripping situados en un Vault de Discos externo (ver figura).
- Del nodo Spn2 con número de discos 2 de tamaño 136,4 GB, con un área de Scratch de 284 Gb en Total U2W 10000RPM (bus de 80MB/s) en stripping situados en un Vault de Discos externo (ver figura).
- Del nodo Spn3 con número de discos 3 de tamaño 36,4 GB con un área de Scrach 106 Gb en Total U2W 10000RPM (bus de 80MB/s) en stripping situados en un Vault de Discos externo (ver figura).
- Del nodo Spn4 con número de discos 2 de tamaño 36,4 GB con un área de Scrach 70 Gb en Total U2W 10000RPM (bus de 80MB/s) en stripping situados en un Vault de Discos externo (ver figura).
- Del nodo Spn5 Tiene instaladas 2 áreas de
scr llamadas /scr1(con número de discos 9 de
tamaño 9 GB, con un área de Scrach 77 Gb en
Total U2W 10000RPM (bus de 80MB/s) en stripping situados
en un Vault de discos externo (ver figura)) Y /scr2
con un Vault de discos que hacen un total de área de Scratch
de 356 Gb.
- Nuevo ordenador spn6.
- Ordenador IBM PSERIES 650
- Procesadores: 8 x Power4@1200MHz
- 4 discos de 146`8 GB, repartidos de la siguiente en un disco de sistema y 3 discos en stripping con un área de Scrach 428 Gb llamada /scr1.
- Y otros 4 discos en un vault de discos, en un area de scrach de 428 GB llamada /scr2
- Con 16 Gb de Ram.
Software
- Version 5.1 del sistema operativo AIX.
- Compiladores de C/C++ xlc 5.0 y vacC 5.0 Compilador de Fortran77 y Fortran90 xlf 7.1.0.0 (compilador SMP).
- Documentación exhaustiva de AIX (accesible en entorno gráfico mediante el comando docsearch).
- Sistema de gestión de colas batch LoadLeveler 3.1.0.0.
- Sotware de Química Computacional:
- Gaussian 98 Revisión A7, Revisión A11 (/util/g98).
- Mopac, Gamess, etc...
- Gaussian 03
- nwchen
Acceso al sistema
A Huckel sólo se puede (y debe) acceder desde Qfgate (Slater visto desde la red del campus). Esta máquina sólo proporciona servicios de red a los hosts de la subred de cálculo. Las mismas restricciones de acceso a Huckel se aplican a los nodos del SP2. Además, no es posible iniciar sesiones interactivas sobre los nodos del SP2, aunque se pueden utilizar los servicios de transferencia de ficheros habituales (ftp, rcp y scp) y el sistema de colas LoadLeveler para iniciar trabajos sobre los nodos de cálculo.
Configuración del sistema de colas
La versión actual del sistema de colas LoadLeveler es muy similar a la versión instalada en el antiguo SP2. Sin embargo, presenta algunas diferencias debido a que ha sido necesario acomodar el software a la posibilidad de enviar trabajos multiprocesador en entornos SMP (entorno similar al que podemos encontrar en los ordenadores Jifay Tiberio).
Configuración de las colas
En la tabla siguiente se muestra la configuración actual de las colas batch definidas en LoadLeveler. Como siempre, esta configuración es provisional y es fácil que, cuando la máquina se encuentre en producción, se produzcan modificaciones para adecuar el sistema (maximizar el rendimiento) al número y tipo de los trabajos. Detalles de la configuración en uso en cada momento se pueden obtener mediante el comando llclass -l [nombre_de_la_cola] (en donde los paréntesis [] indican parámetro opcional y la opción -l solicita un long listing). Algunos de los parámetros reflejados en la tabla tienen su explicación más abajo.
El número máximo de trabajos en máquina está en 24 trabajos simultaneos, limitandolo a 4 trabajos por usuario.
Las colas extras y extra-gran solo están funcionando en spn5 y spn5 solo admite este tipo de colas. Spn1, spn2, spn3 y spn4 admitirá solo colas petitas, mitjanas y gran. Mientras que las colas rap_gran, rap_gran_p, rap_extra y rap_extra_p solo funcionan en spn6.
Nombre de la cola: |
petita |
mitjana |
gran |
extra |
extra-gran |
Priority (system): |
100 |
50 |
0 |
0 |
0 |
Max_processors: |
4 |
4 |
4 |
1 |
4 |
Max_node: |
1 |
1 |
1 |
1 |
1 |
Total_tasks: |
4 |
4 |
4 |
4 |
4 |
Maxjobs: |
12 |
10 |
9 |
1 |
2 |
Nice: |
0 |
10 |
15 |
15 |
15 |
Wall_clock_limit(*): |
9:05:00 (9:00:00) |
45:05:00 (45:00:00) |
144:05:00 (144:00:00) |
420:05:00 (420:00:00) |
420:05:00 (420:00:00) |
Job_cpu_limit(*): |
6:05:00 (6:00:00) |
30:05:00 (30:00:00) |
96:05:00 (96:00:00) |
310:05:00 (310:00:00) |
310:05:00 (310:00:00) |
Cpu_limit(*): |
6:05:00 (6:00:00) |
30:05:00 (30:00:00) |
96:05:00 (96:00:00) |
310:05:00 (310:00:00) |
310:05:00 (310:00:00) |
Data_limit(*): |
256 MB |
512 MB |
2 GB |
256 MB |
3 GB |
Core_limit(*): |
10 MB |
10 MB |
10 MB (10 MB) |
10 MB (10 MB) |
10 MB (10 MB) |
Stack_limit(*): |
256 MB |
512 MB |
2 GB |
1 GB |
3 GB |
Rss_limit(*): |
256 MB |
512 MB |
2 GB |
1 GB |
3 GB |
File_limit(*): |
2 GB |
8 GB |
24 GB |
12 GB |
36 GB |
(*) El primer número representa el límite hard. Entre paréntesis se indica el límite soft.
Nombre de la cola: |
rap_gran |
rap_gran_p |
rap_extra |
rap_extra_p |
Priority (system): |
0 |
0 |
0 |
0 |
Max_processors: |
1 |
2 |
1 |
2 |
Max_node: |
1 |
1 |
1 |
1 |
Total_tasks: |
4 |
4 |
4 |
4 |
Maxjobs: |
3 |
1 |
1 |
2 |
Nice: |
15 |
15 |
15 |
15 |
Wall_clock_limit(*): |
144:05:00 (144:00:00) |
144:05:00 (144:00:00) |
420:05:00 (420:00:00) |
420:05:00 (420:00:00) |
Job_cpu_limit(*): |
96:05:00 (96:00:00) |
96:05:00 (96:00:00) |
310:05:00 (310:00:00) |
310:05:00 (310:00:00) |
Cpu_limit(*): |
96:05:00 (96:00:00) |
96:05:00 (96:00:00) |
310:05:00 (310:00:00) |
310:05:00 (310:00:00) |
Data_limit(*): |
1 GB |
1 GB |
3 GB |
3 GB |
Core_limit(*): |
10 MB (10 MB) |
10 MB (10 MB) |
10 MB (10 MB) |
10 MB (10 MB) |
Stack_limit(*): |
1 GB |
1 GB |
5 GB |
5 GB |
Rss_limit(*): |
1 GB |
1 GB |
5 GB |
5 GB |
File_limit(*): |
12 GB |
12 GB |
75 GB |
75 GB |
Límites
Los límites permiten controlar los recursos que usará un proceso o trabajo. Para cada recurso del sistema se definen dos límites, el límite hard y el límite soft. La diferencia entre ambos estriba únicamente en la forma en que el sistema trata el proceso o el batch cuando estos límites se exceden.
- Límite hard: Cuando se excede el límite hard el sistema envia al proceso una señal no enmascarable, eufemismo para indicar que el sistema elimina el proceso directamente. La consecuencia es que un proceso nunca puede superar su límite hard.
- Límite soft: Cuando se excede alguno de los límites soft, el sistema envía al proceso una señal que éste puede capturar, dándole la oportunidad de actuar en consecuencia. Generalmente, esta actuación se limita a vaciar las caches de disco, cerrar ficheros y abandonar el sistema de una forma más o menos digna. Un proceso puede superar temporalmente cualquiera de sus límites soft.
Los límites de las Colas son los siguientes No pueden estar trabajando mas de 12 Trabajos a la vez y cada Usuario podrá tener trabajando un máximo de 3 trabajos, naturalmente los trabajos que No entren en el sistema de Colas quedaran a la espera y cuando el sistema de Colas Loadlever tenga espacio, entrarán los trabajos encolados. Primero entrarán los de mas prioridad los de las Colas Petita y Mitjana dejando a los trabajos de menos prioridad los de la Cola Gran a la espera.
Los límites pueden ser impuestos por el sistema operativo (en cuyo caso es el propio núcleo del sistema el que mantiene la contabilidad del proceso y genera las señales) o por el sistema de colas. En general, los límites que se aplican a los diferentes procesos que constituyen el trabajo (límites per_job) son impuestos por el sistema de colas mientras que los límites aplicables a los procesos individuales (límites per_process) son impuestos por el sistema operativo. En la siguiente tabla se indica cómo se imponen los límites aplicables:
Límite |
Se impone por... |
Core_limit |
Proceso (per_process) |
Cpu_limit |
Proceso (per_process) |
Data_limit |
Proceso (per_process) |
File_limit |
Proceso (per_process) |
Job_cpu_limit |
Trabajo (per_job) |
Rss_limit |
Proceso (per_process) |
Stack_limit |
Proceso (per_process) |
Wall_clock_limit |
Trabajo (per_job) |
Especificando límites
Un trabajo en una determinada cola nunca podrá solicitar un límite (ya sea hard o soft) superior al especificado en la definición de la cola. Sin embargo, puede,es conveniente y en algunos casos imprescindible que ajuste los límites a los recursos que va a requerir su trabajo. Esto permite al sistema de colas administrar los recursos disponibles. Las consecuencias son que el sistema de colas puede:
- Garantizar que los trabajos que inicien su ejecución dispondrán de los recursos que han solicitado y por tanto se podrán completar (esto no es aplicable al file_limit, ya que el tamaño y número de ficheros que se pueden escribir depende del espacio disponible en el sistema de archivos).
- Maximizar el número de trabajos que se ejecutan simultáneamente en el sistema.
- Ordenar los trabajos de acuerdo con su demanda de recursos, permitiendo que los trabajos más "ligeros" sean ejecutados antes. Un simple cálculo matemático permite comprobar que esta política conduce a la disminución global del tiempo medio que transcurre desde que un trabajo es enviado al sistema de colas hasta que el usuario obtiene los resultados en la consola.
Los límites se especifican en el preámbulo del fichero de comandos (ver ejemplos más abajo). La sintáxis que emplea LoadLeveler para especificar un límite es la siguiente (observe que hay espacios en blanco rodeando el signo "=", pero que no los hay ni antes ni después de la ",") :
tipo_de_limite = limite_hard,limite_soft # Especifica los límites hard y soft
tipo_de_limite = limite_hard # Sólo especifica el límite hard, el límite soft
# aplicable será el del usuario interactivo.
tipo_de_limite = ,limite_soft # Sólo indica límite soft, el límite hard
# aplicable será el definido para la cola.
Las unidades en las que se expresa un límite dependen de su tipo. El valor de un límite se puede especificar mediante un número entero, utilizando unidades de memoria o mediante unidades de tiempo:
- Límites enteros: aplicable a los límites node, task_per_node, etc... Basta con expresar en número de unidades requeridas. En algunos casos se admite la sintáxis:
limite = valor_minimo,valor_maximo
- Límites que utilizan unidades de memoria: data_limit, core_limit, file_limit, stack_limit y rss_limit. Los límites, tanto hard como soft, se expresan como:
entero[.fraccion][unidades]
en donde los [] indican parámetros opcionales y no se puede utilizar espacios entre los diferentes elementos. Si no se indican unidades se entiende que el límite se expresa en bytes. Los valores aplicables para unidades son:
Palabra clave |
Unidades |
b (por omisión) |
bytes |
w |
words |
kb |
kilobytes |
kw |
kilowords |
mb |
megabytes |
mw |
megawords |
gb |
gigabytes |
gw |
gigawords |
- Límites que utilizan unidades de tiempo: cpu_limit, job_cpu_limit y wall_clock_limit. Tanto el límite hard como el soft se expresan como:
[[horas:]minutos:]segundos[.centesimas]
Algunos ejemplos son:
cpu_limit = 12:55:00 # Límite hard 12 horas, 55 minutos
cpu_limit = 12:55:00.10 # Límite hard 12 horas, 55 minutos
cpu_limit = 1:35:00,1:30:00 # Limite hard 1 hora, 35 minutos. Soft 1 hora, 30 minutos.
cpu_limit = ,30 # Límite soft 30 minutos.
cpu_limit = ,30:00 # Límite soft 30 minutos.
cpu_limit = ,30:00:00 # Límite soft 30 horas.
Algunos límites y parámetros especiales
Es interesante notar que, con respecto a la versión anterior de LoadLeveler, han aparecido nuevos parámetros que tienen su origen en la necesidad de adecuar el sistema de colas a los nuevos nodos con arquitectura SMP (multiprocesadores de memoria compartida con tecnología Bull!). Estos parámetros son:
- job_type = pvm3 | parallel | serial. Indica el tipo de trabajo. El símbolo | representa parámetros mutuamente excluyentes.
- node = minimo,maximo. Especifica el número mínimo y máximo de nodos (no procesadores) que puede solicitar un trabajo. De acuerdo con la configuración actual del sistema de colas, sólo es posible solicitar un nodo. Si alguién está interesado en correr aplicaciones pvm3 o mpi a más de cuatro vías deberá ponerse en contacto con el administrador de LoadLeveler. Palabras clave relacionadas: max_proccesors y min_processors.
- node_usage = shared | not_shared. Indica si el proceso desea o no compartir el procesador con otros trabajos. En la configuración actual este parámetro carece de utilidad porque los nodos siempre son asignados para uso exclusivo.
- total_tasks_per_node = numero. Es el número total de procesos que un trabajo paralelo puede ejecutar en un nodo. Observe que si node_usage = not_shared, el número de procesos coincide con el número de procesadores que se utilizarán. De acuerdo con la configuración actual el valor máximo es 4 (un procesador, un proceso). Este parámetro y el siguiente son mutuamente excluyentes.
- total_tasks = numero. Es el número total de procesos (y por tanto procesadores que se utilizarán) que un trabajo paralelo puede ejecutar en todos los nodos disponibles. Este parámetro y el anterior son mutuamente excluyentes.
- job_cpu_limit = limite. Indica el límite de tiempo de CPU (hard y soft) que pueden utilizar todos los procesos de un trabajo paralelo. Este límite representa el valor máximo que puede alcanzar la suma de los tiempos de CPU utilizados por todos los procesos del trabajo.
- wall_clock_limit = limite. Indica los límites hard y soft del lapso de tiempo (tiempo de reloj transcurrido desde que el trabajo entro en estado running) durante el cual el trabajo puede estar en ejecución. Este límite siempre debe especificarse en el fichero de definición del trabajo de LoadLeveler. El valor es utilizado por el algoritmo de asignación de recursos del sistema de colas (denominado LoadLeveler Backfill Scheduler) para reservar los procesadores necesarios para la ejecución. Lamentablemente, el límite debe existir (no posible utilizar el valor unlimited) y va a suponer un problema para aquellos usuarios cuyo input/output sea el factor limitante de la velocidad de ejecución (si ese es su caso, póngase en contacto con el administrador de LoadLeveler).
Envío de trabajos al sistema de colas
Los trabajos se envían al sistema de colas mediante el comando:
llsubmit fichero.cmd
en donde fichero.cmd es un script de shell con la secuencia de comandos a ejecutar precedido por un preámbulo de LoadLeveler que define la naturaleza y características del trabajo.
Trabajos monoprocesador
La forma de envíar un trabajo que sólo requiere un procesador es muy similar a la utilizada en la versión anterior de LoadLeveler. Por ejemplo, el siguiente fichero .cmd lleva a cabo un cálculo de Gaussian98:
#!/bin/ksh
####################################################
# #
# Preambulo de LoadLeveler -- Secuencial #
# #
# Adaptese al tipo de trabajo (job) #
# #
####################################################
#
# Opciones "cosmeticas"
#
# @ job_name = Mi_primer_job
# @ output = mi_1er_job.out
# @ error = mi_1er_job.err
# @ notify_user = Nombre.Apellido@uv.es
# @ notification = complete
#
#---------------------------------------------------
#
# Cola y caracteristicas del calculo
#
# @ class = mitjana
#
#---------------------------------------------------
#
# Limites del calculo
#
# @ wall_clock_limit = 1:35:00,1:30:00
# @ cpu_limit = ,1:20:00
# @ data_limit = 95mb,95mb
# @ file_limit = 250mb,200mb
# @ stack_limit = 64mb,64mb
# @ rss_limit = 100mb,100mb
#
#---------------------------------------------------
#
# Ultimo comando del preambulo. Requerido
#
# @ queue
#
####################################################
# Fin del preambulo de LoadLeveler #
####################################################
#
####################################################
# #
# Macro de ejecucion de Gaussian 98. #
# #
# Secuencia de comandos que definen el trabajo #
# #
####################################################
#
# Fichero de datos y area de scratch
#
INPUT_FILE=test1
LOCAL_SCRATCH="/scr/$LOGNAME"
#
# Definiciones de Gaussian98
#
. /util/g98/private/g98.profile
#
# Ejecucion de Gaussian98.
#
runG98 -s $LOCAL_SCRATCH $INPUT_FILE
#
# Fin de ejecucion.
#
exit |
Observe que ha sido necesario especificar el wall_clock_limit. Si este parámetro no está presente en el preámbulo LoadLeveler rechazará el trabajo.
Trabajos paralelos
El envío de trabajos que solicitan más de un procesador requiere añadir cierta información adicional en el preámbulo de LoadLeveler. Por ejemplo, el siguiente fichero .cmd envía al sistema de colas un trabajo de Gaussian 98 que utiliza 2 procedadores:
#!/bin/ksh
####################################################
# #
# Preambulo de LoadLeveler -- Paralelo #
# #
# Adaptese al tipo de trabajo (job) #
# #
####################################################
#
# Opciones "cosmeticas"
#
# @ job_name = Mi_primer_paralelo
# @ output = mi_1er_paralelo.out
# @ error = mi_1er_paralelo.err
# @ notify_user = Nombre.Apellido@uv.es
# @ notification = complete
#
#---------------------------------------------------
#
# Cola y caracteristicas del calculo
#
# @ class = mitjana
# @ job_type = parallel
# @ node = 1
# @ tasks_per_node = 2
#
#---------------------------------------------------
#
# Limites del calculo
#
# @ wall_clock_limit = 65:00,60:00
# @ job_cpu_limit = ,1:20:00
# @ cpu_limit = ,50:00
# @ data_limit = 110mb,110mb
# @ file_limit = 250mb,200mb
# @ stack_limit = 64mb,64mb
# @ rss_limit = 128mb,128mb
#
#---------------------------------------------------
#
# Ultimo comando del preambulo. Requerido
#
# @ queue
#
####################################################
# Fin del preambulo de LoadLeveler #
####################################################
#
####################################################
# #
# Macro de ejecucion de Gaussian 98. #
# #
# Secuencia de comandos que definen el trabajo #
# #
####################################################
#
# Fichero de datos y area de scratch
#
INPUT_FILE=test_par1_p2
LOCAL_SCRATCH="/scr/$LOGNAME"
#
# Definiciones de Gaussian98
#
. /util/g98/private/g98.profile
#
# Ejecucion de Gaussian98.
#
runG98 -s $LOCAL_SCRATCH $INPUT_FILE
#
# Fin de ejecucion.
#
exit |
Es interesante destacar:
- Se utiliza la directiva job_type para indicar que el trabajo requerirá más de un procesador. Si no se especifica, LoadLever rechazará el trabajo cuando se intente solicitar más de un procesador.
- Se indica que el trabajo requerirá un nodo (node = 1) y que utilizará dos procesadores / dos procesos (tasks_per_node = 2).
- Se indica el job_cpu_time. Este límite representa el valor máximo que puede alcanzar la suma de los tiempos de CPU utilizados por todos los procesos (en este caso 2) del trabajo.
- Como en el ejemplo anterior, se indica el wall_clock_limit: el tiempo de reloj máximo que el trabajo puede estar en la cola de ejecución (independientemente del tiempo de CPU que haya consumido). Es conveniente ajustar este valor a la baja ya que influye directamente en la prioridad que el sistema de colas le asigna al trabajo.
|
