Ejercicios de estimación por intervalos de confianza
IMLE 11/4/2022
#1 Se quiere obtener un intervalo de confianza para el valor de las ventas medias por hora que se producen en un kiosco . Para ello realizamos una muestra consistente en elegir al azar las ventas que se realizaron durante 1000 horas distintas ; muestra cuyos resultados fueron : ventas medias por hora 4000 pts, y varianza de dicha muestra 4000 pts al cuadrado . Obtener dicho intervalo con un nivel de confianza del 95.5 %.
solución https://www.uv.es/ceaces/proble/intermuestras/1/1.htm
# no nos dicen que la población sea normal pero como n es muy grande podemos
# considerar que la distribución de la media muestral es normal por el TCL
#I.C. media de población normal
#n grande ----> varianza muestral la equiparamos a varianza poblacional (conocida)
n=1000 # tamaño muestral
mediamuestral=4000
varianza=4000 #es muestral pero la consideramos poblacional porque n >> 30
dt=sqrt(varianza)
n.confianza=0.955 #nivel de confianza
alfamedios= (1-n.confianza)/2 #cola o p-valor
z.alfamedios=qnorm(alfamedios,0,1, lower.tail = FALSE) # calor crítico
li=mediamuestral-z.alfamedios*dt/sqrt(n)
ls=mediamuestral+z.alfamedios*dt/sqrt(n)
intervalo<-print(paste("[",round(li,2),",",round(ls,2),"]"))## [1] "[ 3995.99 , 4004.01 ]"# grafico intervalo de confianza para la media ( varianza pob conocida)
x <- seq(-4,4,length=100)*dt/sqrt(n) + mediamuestral
hx <- dnorm(x,mediamuestral,dt/sqrt(n))
plot(x, hx, type="l", xlab =" ", ylab=" ",
main=paste("Intervalo de confianza ",n.confianza*100,"%"),sub=paste("[",round(li,2),",",round(ls,2),"]"))
i <- x >= li & x <= ls
lines(x, hx)
polygon(c(li,x[i],ls), c(0,hx[i],0), col="green") 
### Usando la función ic.media del paquete {estadistica}
ic.media(introducir = TRUE,poblacion ="normal",var_pob = "conocida",confianza=0.955,grafico=T)| Introducir el tamaño de la muestra: 1000 Introducir el valor de la media muestral: 4000 Introducir el valor de la varianza poblacional: 4000 [[1]] limite_inferior limite_superior 1 3995.991 4004.009 |
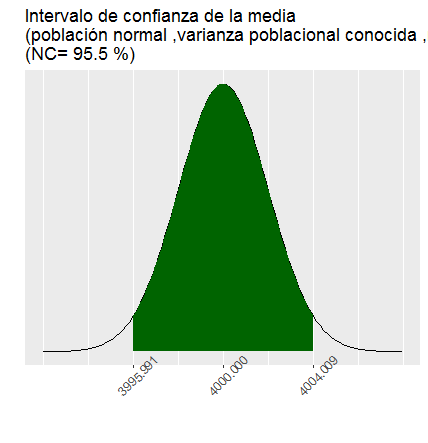
#2 Se desea determinar un intervalo de confianza con nivel de confianza del 99% para la proporción de amas de casa que compran sólo una vez a la semana. Si se sabe que en una muestra aleatoria simple de 400 amas de casa sólo 180 de afirmaron comprar una vez a la semana.
solución: https://www.uv.es/ceaces/proble/intermuestras/1/4.htm
rm(list = ls()) #borrar todo lo anterior
#I.C. para una proporción
#
n=400 # tamaño muestral
proporcionmuestral=180/400 # o directamente proporcionmuestral=0.45
# p=q=0.5 consideramos máxima varianza
n.confianza=0.99 #nivel de confianza
alfamedios= (1-n.confianza)/2 #cola o p-valor
z.alfamedios=qnorm(alfamedios,0,1, lower.tail = FALSE) # calor crítico
li=proporcionmuestral-z.alfamedios*0.5/sqrt(n)
ls=proporcionmuestral+z.alfamedios*0.5/sqrt(n)
intervalo<-print(paste("[",round(li,2),",",round(ls,2),"]"))## [1] "[ 0.39 , 0.51 ]"# grafico intervalo de confianza para la proporción( con P=q=0.5)
x <- seq(-4,4,length=100)*0.5/sqrt(n) + proporcionmuestral
hx <- dnorm(x,proporcionmuestral,0.5/sqrt(n))
plot(x, hx, type="l", xlab =" ", ylab=" ",
main=paste("Intervalo de confianza ",n.confianza*100,"%"),sub=paste("[",round(li,2),",",round(ls,2),"]"))
i <- x >= li & x <= ls
lines(x, hx)
polygon(c(li,x[i],ls), c(0,hx[i],0), col="green") 
### Usando la función ic.proporcion del paquete {estadistica} Recordemos que nos dará el intervalo utilizando las proporciones muestrales y no la estrategia de considerar p=q=0.5
ic.proporcion(introducir= T,confianza=0.99)| ic.proporcion(introducir= T,confianza=0.99 ) [1] "Intervalo de confianza de una proporción. El tamaño de la muestra es grande." Introducir el tamaño de la muestra: 400 Introducir el valor de la proporción muestral: 0.45 ¿Quieres aproximar el valor de p por la proporción muestral? 1. "Sí" 2. "No" 1 [1] "Como n es suficientemente grande, se aproxima el valor de p poblacional por su estimación puntual (p muestral)" limite_inferior limite_superior 1 0.3859271 0.5140729 |
### Si queremos usar la estrategia de considerar p=q=0.5 tendremos que suar la función ad-hoc vista en la teoría
iconf.proporcion=function(n,p,confianza=0.95) {
errorest=qnorm((1-confianza)/2,lower.tail=FALSE)*0.5/sqrt(n)
sol = c(p-errorest,p+errorest)
print("el intervalo de confianza para la proporción es ")
print (paste("[",sol[1],",",sol[2],"]"))
print("")
print("habiéndose considerado p=q=0.5")
print("")
print(paste("el error de estimación es de +/- ",errorest))
}
iconf.proporcion(400,0.45,0.99)
| iconf.proporcion(400,0.45,0.99) [1] "el intervalo de confianza para la proporción es " [1] "[ 0.385604267411278 , 0.514395732588723 ]" [1] "" [1] "habiéndose considerado p=q=0.5" [1] "" [1] "el error de estimación es de +/- 0.0643957325887225" |
#3 Para llevar a cabo un control de calidad sobre el peso que pueden resistir los 300 forjados(suelos) de una construcción , realizamos 12 pruebas resultando la resistencia media hasta la rotura de 350kg/cm2 con desviación típica de 20 . Si trabajamos con nivel de confianza de 0,9. a)¿Ante que tipo de muestreo nos encontramos ?¿Por qué ?. b)¿Entre que valores oscila la resistencia media de los 300 forjados , si por experiencias anteriores sabemos que dicha resistencia se distribuye normalmente ?
solución: https://www.uv.es/ceaces/proble/intermuestras/1/10.htm
rm(list = ls()) #borrar todo lo anterior
# se trata de muestreo sin remplazamiento y la población es pequeña (finita)
# habrá que aplicar el FACTOR CORRECTOR PARA POB. FINITAS
#I.C. media de población normal con M.I.
# la varaianza es desconocida y la muestra pequeña (n< 30)---> estadistico t
n=12 # tamaño muestral
N=300 # tamaño de la población
FCPF= (N-n)/(N-1)
mediamuestral=350
s=20 #desviacion típica muestral
n.confianza=0.9 #nivel de confianza
alfamedios= (1-n.confianza)/2 #cola o p-valor
t.alfamedios=qt(alfamedios,n-1, lower.tail = FALSE) # calor crítico
li=mediamuestral-(t.alfamedios*s/sqrt(n-1))*sqrt(FCPF)
ls=mediamuestral+(t.alfamedios*s/sqrt(n-1))*sqrt(FCPF)
intervalo<-print(paste("[",round(li,2),",",round(ls,2),"]"))## [1] "[ 339.37 , 360.63 ]"# grafico intervalo de confianza para la media ( varianza pob desconocida y poblacion finita )
# como la t de student está centrada en cero y su escala natural es 1
# debemos cambiar la escala a (s/sqrt(n-1))*sqrt(FCPF)
# y desplazar los valores (x) en mediamuestral unidades
# obviamente al calcular la densidad-t-de-Student hay que deshacer esto
x <- seq(-4,4,length=100)*(s/sqrt(n-1))*sqrt(FCPF) + mediamuestral
hx <- dt((x-mediamuestral)/((s/sqrt(n-1))*sqrt(FCPF)),n-1)
plot(x, hx, type="l", xlab =" ", ylab=" ",
main=paste("Intervalo de confianza ",n.confianza*100,"%"),sub=paste("[",round(li,2),",",round(ls,2),"]"))
i <- x >= li & x <= ls
lines(x, hx)
polygon(c(li,x[i],ls), c(0,hx[i],0), col="green") 
### La función ic.media del paquete {estadistica} no contempla la posibilidad de trabajar sobre una población finita (M.I.)
#4 Se desea estimar la diferencia entre el porcentaje de mujeres en puestos de alta dirección en las empresas del sector editorial y en el global de las empresas del país. Para ello se muestrean al azar 64 empresas editoriales e, independientemente, 81 empresas de distintos sectores. Si se quiere realizar la estimación con una confianza del 97% ¿cuál será el resultado si los datos muestrales obtenidos han sido: 31 % de mujeres en puestos directivos en la muestra de empresas editoriales 23 % de mujeres en puestos directivos en la muestra general ?
¿aseguraríamos que el porcentaje es mayor en el mundo editorial?
# se trata de un IC para la diferencia de 2 proporciones
# con dos MAS ( en realidad ,seguramente no pero N infinito)
# independientes de tamaño 64 y 81.
rm(list = ls()) #borrar todo lo anterior
ne=64 # tamaño muestral empresas editoriales
ng=81
pmed=0.31 #proporcion muestral en emp.editoriales
pmg=0.23 # proporcion muestral en el globlalde empresas
# p=q=0.5 en ambos casos ( nótese que tal cosa es imposible , pero se hace) consideramos máxima varianza
n.confianza=0.97 #nivel de confianza
alfamedios= (1-n.confianza)/2 #cola o p-valor
z.alfamedios=qnorm(alfamedios,0,1, lower.tail = FALSE) # calor crítico
li=(pmed-pmg)-z.alfamedios*sqrt((0.25/ne)+(0.25/ng))
ls=(pmed-pmg)+z.alfamedios*sqrt((0.25/ne)+(0.25/ng))
intervalo<-print(paste("[",round(li,2),",",round(ls,2),"]"))## [1] "[ -0.1 , 0.26 ]"# grafico intervalo de confianza para la media ( varianza pob conocida)
x <- seq(-4,4,length=100)*sqrt((0.25/ne)+(0.25/ng))
hx <- dnorm(x,0,sqrt((0.25/ne)+(0.25/ng)))
plot(x, hx, type="l", xlab =" ", ylab=" ",
main=paste("Intervalo de confianza ",n.confianza*100,"%"),sub=paste("[",round(li,2),",",round(ls,2),"]"))
i <- x >= li & x <= ls
lines(x, hx)
polygon(c(li,x[i],ls), c(0,hx[i],0), col="green") 
### Usando la función ic.diferencia.proporciones
del paquete {estadistica} Recordemos que nos dará el intervalo utilizando las proporciones muestrales y no la estrategia de considerar p=q=0.5
ic.diferencia.proporciones(introducir=T,confianza=0.97)| iic.diferencia.proporciones(introducir=T,confianza=0.99) [1] "Primero vas a introducir los datos de la muestra 1 y a continuaciþn introducirás los datos de la muestra 2" [1] "Si los datos provienen de encuestas realizadas antes y después de una determinada acción, introduce primero los datos de la encuesta realizada después de dicha acción" Introducir el tamaño de la muestra 1: 64 Introducir el valor de la proporción muestral 1: 0.31 Introducir el tamaño de la muestra 2: 81 Introducir el valor de la proporción muestral 2: 0.23 limite_inferior limite_superior 1 -0.1115248 0.2715248 |
### Si queremos usar la estrategia de considerar p=q=0.5 tendremos que suar la función ad-hoc vista en la teoría
iconf.diferencia.proporciones=function(n1,p1,n2,p2,confianza=0.95){
alfamedios=(1-confianza)/2
errorest=qnorm(alfamedios,lower.tail =FALSE )*sqrt((0.25/n1)+(0.25/n2))
sol=c(p1-p2-errorest,p1-p2+errorest)
print (paste("[",sol[1],",",sol[2],"]"))
print("")
print("habiéndose considerado p=q=0.5")
print("")
print(paste("el error de estimación es de +/- ",errorest))
}
iconf.diferencia.proporciones(64,0.31,81,0.23,0.97)
| iiconf.diferencia.proporciones(64,0.31,81,0.23,0.97) [1] "[ -0.101467698098691 , 0.261467698098691 ]" [1] "" [1] "habiéndose considerado p=q=0.5" [1] "" [1] "el error de estimación es de +/- 0.181467698098691" > |
#¿aseguraríamos que el porcentaje es mayor en el mundo editorial?
# aunque esto es anticipar lo que es el contrate estadístico de hipótesis
# podemos ver que el intervalo estimado abarca también una pequeña zona negativa
# por lo que no se puede descartar ( al nivel que hemos trabajado) que la diferencia
# sea nula o incluso en el sentido contrario al aparente #5 Intervalo t automatizado Cuando se dispone de toda la información muestral (en una base de datos / dataframe) es posible automatizar la obtención de los intervalos de confianza con R tanto con las funciones ya vistas del paquete {estadistica} como utilizando funciones genéricas(de páquetes básicos) de R ( aunque de los procedimientos de contraste de hipótesis) Vamos a cargar la base de datos : trabajadores para verlo:
rm(list = ls()) #borrar todo lo anterior
trabajadores <- read.table("http://www.uv.es/mlejarza/azar/trabajadores.Rdata")
names(trabajadores) #vemos las variables de la base de datos## [1] "genero" "sector" "ingresos" "segurpen"Vamos a trabajar con la variable “ingresos”.Consideremos que estos datos son los poblacionales veamos lo que valen los parámetros.
ingresos<-trabajadores$ingresos
mediaPoblacion<-mean(ingresos)
varianzaPoblacion<-var(ingresos)
destipPoblacion<-sd(ingresos)
print(paste("media ingresos en poblacion", round(mediaPoblacion,2)))## [1] "media ingresos en poblacion 22095.67"print(paste("varianza ingresos en poblacion",round(varianzaPoblacion,2)))## [1] "varianza ingresos en poblacion 18110002.21"p
print(paste("desviacion tipica ingresos en poblacion",round(destipPoblacion,2)))## [1] "desviacion tipica ingresos en poblacion 4255.58"Suponemos ahora que queremos un IC para la media del 95 % a partir de una MAS de tamaño 26. Como la muestra es pequeña estamos en el caso de intervalo t. Llevamos a cabo la muestra. Podemos aplicar la función ic.media de {estadistica} o podemos Aplicar la función t.test del paquete básico {stats} que, en realidad, sirve para hacer un contraste t ( lo veremos en el próximo tema).Con esta función se genera un objeto complejo uno de cuyos componentes es el intervalo de confianza.
muestra<-sample(ingresos,26)
mean(muestra)#media muestral## [1] 22432.18sd(muestra)#desv.tip. muestral## [1] 4619.491#aplicando la función ic.media
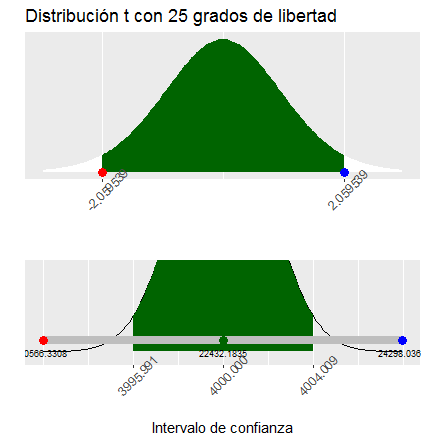
ic.media(muestra,var_pob="desconocida",confianza=0.95,grafico=T)
| ic.media(muestra,var_pob="desconocida",confianza=0.95,grafico=T) Selecciona el valor que quieres utilizar? 1. "Varianza muestral" 2. "Cuasivarianza muestral" 1 [[1]] limite_inferior limite_superior 1 20566.33 24298.04 [[2]] NULL |
# con la función t.test {stats}
t<- t.test(muestra,conf.level = 0.95)
intervalo<-t$conf.int
intervalo##intervalo
[1] 20566.33 24298.04
attr(,"conf.level")
[1] 0.95
# 6 Intervalo z automatizado .
Podemos usar la función ic.media ,con la opción var_pob="conocida" o sin fijarla ya que ésta es la opción por defecto . Para el caso de disponer sobre la población de ingresos de una nueva muestra de tamaño 100 pero lo demás igual que en el caso anterior Usaríamos, estas opciones : ic.media(muestra). Eso sí deberíamos introducir el valor de la varianza poblacional ; el auténtico, si lo sabemos, o tomando por poblacional el valor de la varianza muestral .
set.seed(444)#fijamos la semilla para obtener la misma muestra en los dos procesos
muestra<-sample(ingresos,100)
mean(muestra)#media muestral## [1] 22697.65sd(muestra)#desv.tip. muestral## [1] 3979.892
var(muestra)#varianza de la muestra ( que tomaremos como si fuera de la población)
17617115
ic.media(muestra)#las opciones varianza conocida y confianza =0.95, son las "por defecto"
|
Las funciones t.test y prop.test (contrastes e intervalos para proporciones) están incorporadas en los paquetes básicos de R . Sin embargo z.test el equivalente cuando la varianza es conocida ( tamaño muestral grande ) no está disponible a no ser que carguemos el paquete {TeachingDemos}
repitamos el proceo anterior para una muestra de tamaño 100 primero usando la función t.test y después con z.test( bajo TeachingDemos)
t<- t.test(muestra,conf.level = 0.95)
intervalo.t<-t$conf.int
intervalo.t## [1] 21864.81 23530.048
## attr(,"conf.level")
## [1] 0.95library(TeachingDemos)
z<-z.test(muestra,sd=sd(muestra),conf.level=0.95)
intervalo.z<-z$conf.int
intervalo.z## [1] 21874.99 23520.30
## attr(,"conf.level")
## [1] 0.95# Vemos como el procedimiento ic.media {estadistica} y el z.test{TeachingDemos}
# llevan al mismo resultado .
# podremos observar que usando el intervalo z
# asumiendo varianza poblacional igual a la de la poblacion
# difiere muy poco porque la muestra es grande
#7 Diferencia de medias con intervalo t
Si contamos con 2 muestras procedentes de dos poblaciones podemos obtener el intervalo de confianza para la diferencia usando t.test con dos argumentos ( las dos muestras) vamos a obtener un IC del 90% para la diferencia de los ingresos entre hombres y mujeres a partir de dos MAS aleatorias independientes de tamaños 20 (hombres) y 18 (mujeres)
#borramos todos los objetos excepto trabajadores ( nuestro universo)
#rm(ingresos,t,z,destipPoblacion,intervalo,intervalo.t,intervalo.z,mediamuestral,
# mediaPoblacion,varianzaPoblacion,muestra)
#construimos dos sub_universos: Hombres y mujeres
set.seed(444)#fijamos la semilla para obtener la misma muestra aquí y en #8
hombres<-subset(trabajadores,genero=="hombre")
mujeres<-subset(trabajadores,genero=="mujer")
muestra.ingresos.hombres<-sample(hombres$ingresos,20)
muestra.ingersos.mujeres<-sample(mujeres$ingresos,18)
t<-t.test(muestra.ingresos.hombres,muestra.ingersos.mujeres,conf.level=0.90,var.equal=TRUE)
# hemos añadido el argumento var.equal=TRUE,ya que en la teroría suponíamos la homoscedatiscidad.
# Sin embargo R ,en principio prsume lo contrario
t##
## Two Sample t-test
##
## data: muestra.ingresos.hombres and muestra.ingersos.mujeres
## t = -0.083259, df = 36, p-value = 0.9341
## alternative hypothesis: true difference in means is not equal to 0
## 90 percent confidence interval:
## -2582.041 2339.343
## sample estimates:
## mean of x mean of y
## 22735.83 22857.18intervalo<-t$conf.int
intervalo## [1]-2582.041 2339.343## attr(,"conf.level")ic.diferencia.medias(x,variable = NULL,introducir = FALSE,poblacion = c("normal","desconocida"),
## [1] 0.9
#usando la función ic.diferencia.medias de {estadistica}
#
var_pob = c("conocida","desconocida"),iguales = FALSE,confianza = 0.95)# Introducir directamente las muestras obtenidas( argumentos x y variable)no es facil
ya que no tienen el mismo tamaño : por ello ,usaremos la opción introducir= TRUE
habiéndo obtenido previamente los valores de las medias y varianzas muestrales
> mean(muestra.ingresos.hombres)
[1] 22735.83
> mean(muestra.ingresos.mujeres)
[1] 22857.18
> var(muestra.ingresos.hombres)#en R es la cuasivarianza
[1] 22615015
> var(muestra.ingresos.mujeres)#en R es la cuasivarianza
[1] 17341994
ic.diferencia.medias(introducir=T,var_pob="desconocida",iguales=T,confianza=0.9)
| > ic.diferencia.medias(introducir=T,var_pob="desconocida",iguales=T,confianza=0.9) Introducir el tamaño de la muestra 1: 20 Introducir el valor de la media muestral 1: 22735.83 Introducir el tamaño de la muestra 2: 18 Introducir el valor de la media muestral 2: 22857.18 Selecciona el valor que quieres utilizar: 2 1. "Varianza muestral" 2. "Cuasivarianza muestral" Introducir el valor de la cuasivarianza muestral 1: 22615015 Introducir el valor de la cuasivarianza muestral 2: 17341994 [1] "Este es el intervalo que generalmente calculan los softwares (SPSS, Excel, etc.)" limite_inferior limite_superior 1 -2582.042 2339.342 |
#8 en el caso general (var.equal=FALSE) el estadístico y el intervalo son ligeramente diferentes y con distintos grados de libertad ( que son aproximados) Podemos hacerlo con las dos funciones, también .
hombres<-subset(trabajadores,genero=="hombre")
mujeres<-subset(trabajadores,genero=="mujer")
set.seed(444)
muestra.ingresos.hombres<-sample(hombres$ingresos,20)
muestra.ingersos.mujeres<-sample(mujeres$ingresos,18)
t<-t.test(muestra.ingresos.hombres,muestra.ingresos.mujeres,conf.level = 0.90)
#no añadimos el argumento var.equal=TRUE ( por defecto es FALSE)
t##
## Welch Two Sample t-test
##
## data: muestra.ingresos.hombres and muestra.ingersos.mujeres
## t = -0.083855, df = 35.979, p-value = 0.9336
## alternative hypothesis: true difference in means is not equal to 0
## 90 percent confidence interval:
## -2564.580 2321.881
## sample estimates:
## mean of x mean of y
## 22735.83 22857.18 intervalo<-t$conf.int
intervalo## [1]-2564.580 2321.881## attr(,"conf.level")
## [1] 0.9
#los grados de libertad son aproximados ( fraccionarios) y el intervalo es ligeramente distinto
| #usando la función ic.diferencia.medias() > ic.diferencia.medias(introducir=T,var_pob="desconocida",confianza=0.9) Introducir el tamaño de la muestra 1: 20 Introducir el valor de la media muestral 1: 22735.83 Introducir el tamaño de la muestra 2: 18 Introducir el valor de la media muestral 2: 22857.18 Selecciona el valor que quieres utilizar: 1. "Varianza muestral" 2. "Cuasivarianza muestral" 2 Introducir el valor de la cuasivarianza muestral 1: 22615015 Introducir el valor de la cuasivarianza muestral 2: 17341994 [1] "Este es el intervalo que generalmente calculan los softwares (SPSS, Excel, etc.)" limite_inferior limite_superior 1 -2564.542 2321.842 |
#8 bis La función t-test también recoge la posibilidad de las muestras no sean independientes sino aparejadas . No puedes ser el caso de nuestro ejemplo. Pero sí podría ser si se muestrean dos características distintas de los mismos individuos seleccionados basta aquí introducir el argumento paired = TRUE ( por defecto es falso)
#9 Con la función prop.test podemos calcular intervalos de confianza para la porporción y diferencia de proporciones. Pero el resultado de estas funciones no es el que obtenemos cuando realizamos los intervalos y contrastes usando un estadístico z ( distribución normal) sino usuando un estadístico dieferente de distribución chi-cuadrado. Por esta razón no usaremos, en general, la función prop.test , sino la función ic.proporcion {estadistica} si consideramos la estrategia "prop.muestrales" o la función iconf.proporcion definida en la teoría si consideramos la estrategia p=q=0.5
Estimemos la proporcion de trabajadores terciarios cin IC del 99 % Seleccionemos al azar 200 trabajadores y contabilicemos la proporción de trabajadores del sector terciario
trab.terciariosset.seed(444)
seleccion<-sample(250000,200)
muestra<-trabajadores[seleccion,]
trab.terciarios<-table(muestra$sector)[3]
trab.terciarios
p.muestral=trab.terciarios/200;p.muestral
terciario
122
> p.muestral=trab.terciarios/200;p.muestral
terciario
0.61
ic.proporcion(introducir=T,confianza=0.99) # considerando la proporción muestral
| ic.proporcion(introducir=T,confianza=0.99) [1] "Intervalo de confianza de una proporción. El tamaño de la muestra es grande." Introducir el tamaño de la muestra: 200 Introducir el valor de la proporción muestral: 0.61 ¿Quieres aproximar el valor de p por la proporción muestral? 1. "Sí" 2. "No" 1 [1] "Como n es suficientemente grande, se aproxima el valor de p poblacional por su estimación puntual (p muestral)" limite_inferior limite_superior 1 0.5211619 0.6988381 |
iconf.proporcion(200,0.61,0.99) #considerando p=q=0.5
| iconf.proporcion(400,0.45,0.99) [1] "el intervalo de confianza para la proporción es " [1] "[ 0.385604267411278 , 0.514395732588723 ]" [1] "" [1] "habiénndose considerado p=q=0.5" [1] "" [1] "el error de estimación es de +/- 0.0643957325887225" > iconf.proporcion(200,0.61,0.99) [1] "el intervalo de confianza para la proporción es " [1] "[ 0.518930681614078 , 0.701069318385922 ]" [1] "" [1] "habéndose considerado p=q=0.5" [1] "" [1] "el error de estimacón es de +/- 0.0910693183859225" > |
#10 Nos proponemos ,ahora, estimar la diferencia entre la porporción de trab terciarios entre hombres y mujeres NC=99% 200 hombres y 200 mujeres elegidas al azar.
set.seed(444)
seleccion<-sample(185500,200)
muestra.hombres<-hombres[seleccion,]
trab.terciarios.hombres<-table(muestra.hombres$sector)[3]
seleccion2<-sample(64500,200)
muestra.mujeres<-mujeres[seleccion2,]
trab.terciarios.mujeres<-table(muestra.mujeres$sector)[3]
prop.hombres=trab.terciarios.hombres/ 200
prop.mujeres=trab.terciarios.mujeres/200
| > trab.terciarios.hombres terciario 119 > trab.terciarios.mujeres terciario 112 > prop.hombres= trab.terciarios.hombres/ 200 > prop.mujeres= trab.terciarios.mujeres/200 > prop.hombres terciario 0.595 > prop.mujeres terciario 0.56 |
#usando la función ic.diferencia.proporciones con la estrategia de considerar las proporciones muestrales.
#usando la función icon.diferencia.proporciones con la estrategia px=qx=py=qy=0.5iconf.diferencia.proporciones(200,0.595,200,0.56,confianza=0.99) |
| iconf.diferencia.proporciones(200,0.595,200,0.56,confianza=0.99) [1] "[ -0.0937914651774451 , 0.163791465177445 ]" [1] "" [1] "habiéndose considerado p=q=0.5" [1] "" [1] "el error de estimación es de +/- 0.128791465177445" |