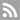El pixelado ya no funciona. Nosotros no podemos ver lo que esconde, pero un ordenador sí.
20 de septiembre de 2016
EL PIXELADO HA SIDO durante mucho tiempo la hoja de parra que ha escondido la mayoría de las partes privadas de los medios visuales. Las partes borrosas de texto o caras y matrículas oscurecidas aparecen en las noticias, en documentos escritos y en línea. La técnica no es elegante pero ha funcionado lo suficientemente bien porque la gente no puede ver o leer a través de la distorsión. Sin embargo, el problema es que los humanos ya no somos los únicos que podemos reconocer magistralmente imágenes. A medida que la visión por ordenador se hace cada vez más fuerte, está empezando a ver cosas que nosotros no podemos.
Investigadores de la Universidad de Texas en Austin y Cornell Tech dicen que han entrenado una pieza de software que puede poner en peligro los beneficios de la privacidad de las técnicas de enmascaramiento de contenido estándar, como la distorsión y el pixelado, al haber aprendido a leer o a ver lo que se supone que está escondido en las imágenes (desde el número borroso de una casa hasta la imagen de una cara pixelada en el fondo de una foto). El equipo descubrió que los métodos de aprendizaje automático de las máquinas (el proceso de "entrenar" un ordenador con una serie de datos como ejemplo en vez de programarlo) se han prestado fácilmente a este tipo de ataque.
Los investigadores han sido capaces de derrotar tres tecnologías de protección de privacidad, empezando con la propia herramienta de distorsionar de YouTube. YouTube permite a sus usuarios seleccionar objetos o figuras que quieren desdibujar, pero el equipo utilizó su ataque para identificar caras distorsionadas en los vídeos. Otro ejemplo de su método es cuando los investigadores atacaron el pixelado. Para crear diferentes niveles de pixelado, utilizaron su propia aplicación de una técnica de pixelado estándar que los investigadores dijeron que se puede encontrar en Photoshop y en otros programas comunes. Y, finalmente, atacaron una herramienta llamada Privacy Preserving Photo Sharing (P3), que encripta los datos de identificación en fotos .JPEG para que los humanos no podamos ver la imagen general, mientras dejan otros componentes nítidos para que los ordenadores puedan hacer cosas con los archivos como comprimirlos.
Para ejecutar los ataques, el equipo entrenó redes neuronales para el reconocimiento de imagen proporcionando, para su análisis, datos de cuatro conjuntos de imágenes grandes y conocidas. Cuantas más palabras, caras u objetos «vea» una red neuronal, mejor es a la hora de localizar el blanco. Una vez que las redes neuronales han conseguido un 90 % de precisión o han mejorado en identificar objetos relevantes en las imágenes, los investigadores oscurecieron las imágenes utilizando las tres herramientas de privacidad y, después, entrenaron sus redes neuronales para interpretar las imágenes borrosas y pixeladas basadas en el conocimiento de las originales.
Finalmente, utilizaron pruebas de imágenes oscurecidas a las que las redes neuronales aún no habían sido expuestas de ninguna forma para ver si el reconocimiento de imagen podía reconocer caras, objetos y números escritos a mano. Si los ordenadores hubieran identificado mediante adivinación de forma aleatoria las caras, formas y números, los investigadores calcularon que la media de éxito de cada test habría sido del 10 % como mucho y, como poco, un 5 %, lo que significa que incluso un índice de éxito bajo en la identificación era mejor que adivinar.
Incluso si el método de aprendizaje de la máquina del grupo no siempre accediera a los efectos de redacción de una imagen, aún representa un fuerte golpe para el pixelado y la borrosidad como herramienta de privacidad, dice Lawrence Saul, un investigador de aprendizaje automático en la Universidad de California, San Diego. «Con el objetivo de derrotar la privacidad, no necesitas en verdad mostrar que el 99,9 % de las veces puedes reconstruir» una imagen of trozo de texto, dice Saul. «Si el 40 o el 50 % de las veces pueden adivinar la cara o averiguar qué es el texto, entonces es suficiente para dictaminar que el método de privacidad es obsoleto».
El principal objetivo de los investigadores es avisar a las comunidades de privacidad y seguridad de que los avances en aprendizaje automático como herramienta para la identificación y colección de datos no se puede ignorar. Saul indica que hay formas de defenderse de este tipo de ataques, como usar cajas negras que ofrecen una cobertura total en lugar de distorsiones de imágenes que dejan trazas de contenido detrás.
Artículo original publicado en Wired.