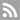El sistema de visió d’aprenentatge profund des de la informàtica i el Laboratori de Intel·ligència Artificial anticipa interaccions humanes mitjançant vídeos de programes televisius.
20 july 2016
*Notícia traduïda de MIT News
Quan vegem a dos persones coneixent-se, podem predir què va a passar: un apretó de mans, una abraçada, o fins i tot un bes. La nostra capacitat per anticipar accions es dona gràcies a les intuicions adquirides durant les experiències de la nostra vida.
Les màquines, d’altra banda, tenen problemes a l’utilitzar coneixements complexes com aquests. Els sistemes informàtics que prediuen accions podrien obrir noves possibilitats que van des de robots que es mouen en l’entorn humà fins a sistemes de resposta d’emergència que prediuen caigudes o auriculars pareguts a les ulleres de realitat augmentada de Google, que t’oferixen suggerències sobre què fer en distintes ocasions.
Aquesta setmana, investigadors del Laboratori de Informàtica i Intel·ligència Artificial (CSAIL) del MIT han realitzat un gran avanç en visió predictiva, han desenvolupat un algoritme que pot anticipar interaccions de forma més precisa que mai.
El sistema pot predir si dos individus se van a abraçar, besar, si es van a donar un apretó de mans o si van a xocar els cinc basant-se en vídeos de Youtube i series com The Office i Mujeres Desesperadas. En un segon pla, també podria anticipar quin objecte és probable que aparega en un vídeo cinc segons després.
Mentre que les salutacions humanes poden paréixer accions arbitràries que predir, aquesta tasca va servir com una prova més fàcil de controlar per als investigadors.
“Els humans aprenen automàticament a anticipar accions a través de l’experiència, això va captar el nostre interés en tractar de crear ordinadors amb el mateix tipus de trellat”, diu l’estudiant de doctorat del CSAIL Carl Vondrick, primer autor d’un article relacionat que presentarà esta setmana en la Conferència internacional sobre visió per ordinador i reconeixement de patrons (CVPR). “Voldríem mostrar que simplement amb mirar molts vídeos, els ordinadors poden adquirir el suficient coneixement com per a fer prediccions de forma consistent sobre el seu entorn”.
Entre els co-autors del treball de Vondrick es troben el professor del MIT Antonio Torralbe i l’ex post-doctorat Hamed Pirsiavash, actualment professor en la Universitat de Maryland.
Com funciona
Anteriors intensius en visió per ordinador predictiva han pres generalment un o dos enfocaments. El primer mètode consisteix en mirar els píxels individuals d’una imatge i utilitzar eixe coneixement per a crear una “futura” imatge foto-realística, píxel a píxel-una tasca que Vondrick descriu com “difícil per a un pintor professional, però molt menys per a un algoritme”. El segon consisteix en fer que els humans marquen l’escena per a l’ordinador prèviament, el que és poc pràctic per a poder predir accions a gran escala.
L’equip del CSAIL, en canvi, va crear un algoritme que pot predir “representacions visuals”, que són bàsicament fotogrames congelats que mostren distintes versions del que podria paréixer l’escena.
“En lloc de dir que el valor d’un píxel és blau, el següent roig, etc., les representacions visuals revelen informació sobre la imatge més gran, com una col·lecció de píxels que representa un rostre humà”, diu Vondrick.
L’algoritme de l’equip utilitza tècniques d’aprenentatge profund, un camp de la intel·ligència artificial que utilitza sistemes anomenats “xarxes neuronals” per a ensenyar als ordinadors a llegir atentament quantitats enormes de dades per a trobar patrons per ells mateixos.
Cadascuna de les xarxes de l’algoritme prediu una representació que automàticament es classifica com una de les quatre accions- en aquest cas: una abraçada, un apretó o un xoc de mans, o un bes. Aleshores el sistema fusiona estes accions en una que s’usa com la predicció. Per exemple, tres xarxes poden predir un bes, mentre que una altra pot utilitzar el fet de que altra persona ha entrat en l’enquadre com a motiu per a predir una abraçada.
“Un vídeo no és com un llibre de ‘Elegeix la teua pròpia aventura’ on pots vore totes les possibles opcions”, diu Vondrick. “El futur és ambigu per naturalesa, pel que és emocionant posar-nos a prova per a desenvolupar un sistema que utilitze aquestes representacions per aniticipar totes les possibilitats”.
Com s’ha fet
Després d’entrenar a l’algoritme amb 600 hores de vídeo sense etiquetar, l’equip ho provà en nous vídeos que mostraren ambdúes accions i objectes.
Quan es mostra un vídeo de gent que està a un segon de realitzar una de les quatre accions, l’algoritme va predir correctament l’acció més del 43% de les vegades, comparat amb els algoritmes existents que només podien acertar-ho el 36% de les voltes.
En un segon estudi, se li mostrà a l’algoritme un fotograma d’un vídeo i se li demanà que predira quin objecte apareixeria cinc segons després. Per exemple, vore a algú obrir un microones pot suggerir la presència futura d’una tasa de cafè. L’algoritme va predir l’objecte en el marc un 30% de forma més precisa que les mides base, encarara que alguns investigadors advertixen que només té una precisió de l’onze per cent de moment.
Cal destacar que fins i tot els humans cometens errors en estes tasques: per exemple, subjectes humans només foren capaços de predir correctament l’acció el 71% de les vegades.
“Hi ha molta sutilesa en l’enteniment i previsió d’interaccions humanes”, diu Vondrick. “Esperem poder subsanar aquest exemple per a ser capaços de predir prompte fins i tot tasques més complexes”.
Perspectiva de futur
Mentre que els algoritmes no són lo suficientment precisos per a aplicacions pràctiques, Vondrick diu que es podrien utilitzar futures versions per a tot, des de robots que desenvolupen de millor forma plans d’acció fins a càmeres de seguretat que puguen avisar al personal d’emergència quan algú cau o es fa mal.
“Estic entusisasmat per vore com milloren els algoritmes si els introduïm els vídeos de tota una vida”, diu Vondrick. “Podríem vore millores significants que ens aproparien a l’ús de visió predictiva en situacions del món real”.
El treball ha comptat amb el suport d’una beca de la Fundació Nacional de Ciències, junt amb un premi Google a la investigació per a Torralba i una beca Google per a Vondrick.