Políticas y Derecho para el impulso de la inteligencia artificial, tecnologías y recursos de la lengua española
Lorenzo Cotino Hueso
Catedrático de Derecho Constitucional, Universidad de Valencia, coordinador de Regulación y Derechos de OdiseIA.
Tras el inglés, chino y según los casos, el hindi, el español es una de las lenguas con más hablantes nativos del mundo (474.7 millones) y más usuarios (548.3 millones), la tercera en usuarios de la red y también entre las primeras por intercambio económico. Es indudable el potencial cultural, social, económico y estratégico para el español. Pues bien, la lengua, los textos de múltiples procedencias son un alimento de la inteligencia artificial de extraordinario valor. Más de 90% de la información digital disponible es información no estructurada en forma de textos y documentos (escritos o hablados) en múltiples lenguas. Y las tecnologías del lenguaje con la IA a la cabeza son esenciales para extraer su valor, están en el corazón del software que actualmente procesa la información no estructurada y explota la gran cantidad de datos.
Al mismo tiempo, las tecnologías del lenguaje transforman nuestra relación con los sistemas informáticos y artificiales, favorecen la creación de una sociedad multilingüe y están detrás de muchos productos y plataformas digitales. Estas herramientas digitales son el elemento fundamental de la economía del conocimiento y la IA es “uno de los elementos disruptivos fundamentales”.
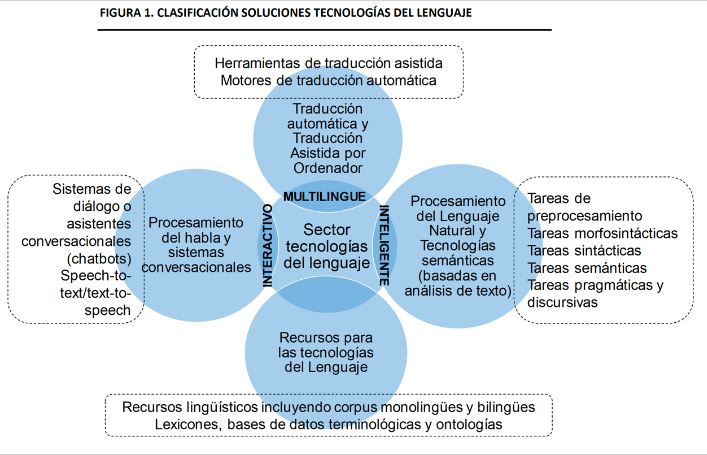
Fuente: SESIAD. (2018). Estudio de caracterización del sector de tecnologías del lenguaje, p. 26.
Cabe recordar las herramientas que hay en el ámbito de la industria del lenguaje:
- herramientas y motores de traducción automática y traducción asistida por ordenador.
- Tecnologías de procesamiento del habla y sistemas conversacionales, que incluye los sistemas de reconocimiento del habla, la comprensión del lenguaje hablado, la conversión a texto y viceversa, la síntesis de voz a partir de texto, interacción, negociación y generación del habla, los sistemas de diálogo o asistentes conversacionales.
Asimismo, los sistemas que realizan tareas de preprocesamiento, que sirven para la clasificación, agrupación, filtrado y enrutamiento de documentos, la creación de resúmenes automáticos, la extracción de datos, el análisis de sentimientos y minería de opinión, el seguimiento y monitorización de la reputación en los medios sociales, la creación de alertas, la corrección ortográfica y gramatical, la ayuda al aprendizaje y la enseñanza de idiomas, la búsqueda inteligente y optimizada de documentos, los sistemas de respuesta automática a preguntas, asistentes personales o la traducción automática de textos
Pues bien, los algoritmos de aprendizaje automático y otras tecnologías que están detrás de todos estos sistemas y herramientas, para su provisión y desarrollo necesitan como “alimento”, como ejemplo del que aprender de las intraestructuras y recursos lingüísticos.
Sin embargo, como se ha adelantado, en buena medida los textos y el lenguaje aparecen como datos no estructurados, necesitan pasar a ser primarios con alguna estructura, y especialmente como datos secundarios con metadatos y anotaciones que añaden valor. Estos conjuntos se combinan en “corpus” y de “bases de datos”, colecciones de datos secundarios, léxicos, lexicones o diccionarios, también las “ontologías” y las gramáticas. Y lo cierto es que el español no cuenta con suficientes recursos e infraestructuras lingüísticas disponibles para entrenar a los algoritmos de IA, a diferencia del inglés y otros idiomas, que están en situación bastante más ventajosa con muchas e importantes las empresas que tienen a su disposición muchos procesadores y recursos lingüísticos, grandes corpus. De ahí que las políticas públicas se centran especialmente en recursos infraestructuras lingüísticas por cuanto
dan soporte como una infraestructura común y reducir así la inversión inicial que permitiría a las PYMES.
Los poderes públicos en España desde hace una década han fijado los objetivos de las políticas en IA y lenguas. Especialmente el Plan de Impulso de las Tecnologías del Lenguaje, de 2015 para 5 años definió correctamente los objetivos, esencialmente
- el desarrollo de infraestructuras lingüísticas en español y lenguas cooficiales: impulsar la industria, asegurar la disponibilidad pública gratuita o a bajo coste de infraestructuras lingüísticas herramientas comunes, interoperabilidad, generación automática de recursos lingüísticos ;
- el impulso de la industrias de las tecnologías del lenguaje, dar más visibilidad al sector, potenciar la investigación y la transferencia de conocimiento a la industria, así como la internacionalización (en especial en Iberoamerica y EEUU); y
- el papel específico del sector público como usuario de las tecnologías de la lengua en sus servicios, la promoción de plataformas, herramientas e infraestructuras comunes, coordinando los recursos lingüísticos desde la interoperabilidad.
Y en los últimos años se han intensificado mucho estas políticas (ENIA, PERTE “nueva economía de la lengua” de 2022, dotado de 1.100 millones de euros).
Desde 2015 el Plan de impulso de Tecnologías del Lenguaje se generaron dos corpus de gran valor para el desarrollo de la IA en español. De un lado, el corpus CAPITEL está realizado en colaboración y es de propiedad conjunta de la SEDIA y la RAE. Es el mayor corpus anotado en español existente en la actualidad, con 300 millones de palabras. También se han desarrollado por la RAE el “Corpus de Referencia del Español Actual” (CREA), el “Corpus Diacrónico del Español” (CORDE), el Corpus del Español del Siglo XXI (CORPES XXI), liderado por la RAE y el modelo MarIA en colaboración con el Barcelona Supercomputing Center. También el Corpus científico-técnico (CCT). Tras la ENIA y los planes de digitalización de 2021, el PERTE “Nueva Economía de la Lengua” de 2022 da clara continuidad y profundidad a los corpus CREA, CORPES XXI y el modelo MarIA.
Pues bien, la regulación aplicable a estos recursos lingüísticos es ciertamente compleja y compuesta por la regulación de propiedad intelectual, secretos industriales y reutilización de la información pública (con las continuas novedades introducidas por directivas y reglamentos europeos). Esta regulación es un elemento que condiciona las políticas, planeación y modelos de explotación y sostenibilidad de los mismos. Especialmente hay que poner la atención en el enfoque de la propiedad intelectual y el régimen de reutilización de datos. Y a partir de la regulación actual los promotores y titulares de los corpus y otros recursos lingüísticos no están claramente obligados a abrir estos recursos y tienen el derecho “sui géneris” de propiedad intelectual de bases de datos, ello les permite a que expresamente puedan condicionar y que no se pueda hacer minería de datos u otros procesados sin su autorización. Pese al principio de que los datos son minables por defecto, el titular puede reservarse la facultad de hacer minería de datos sobre los mismos. Asimismo, con la normativa europea y española más reciente, hoy por hoy aún son muy limitadas las excepciones a favor de la investigación.
En cualquier caso, la articulación de estas políticas de apertura a la explotación de recursos lingüísticos pasa por la elección de licencias permisivas para las empresas que quieran utilizarlos para desarrollar sus tecnologías de la lengua. Y para ello se cuenta con la larga experiencia de ELRA, que es la distribuidora europea de recursos y herramientas lingüísticos desde 1995. En su contexto, la Alianza Tecnológica Multilingüe de Europa (META) es una red de excelencia creada por la Comisión Europea. Así se han desplegado las licencias Meta-Share, desde el contexto de ELRA, con dos décadas de experiencia en la materia e integrando a los actores de las tecnologías y recursos de la lengua. Estas licencias son el marco de referencia al que acudir. Se trata de un conjunto de licencias que incorporan las nuevas tendencias permisivas y recursos libres en la órbita de Creative Commons. Así, se proporcionan recursos para infraestructura abierta, distribuida, segura e interoperable en el ámbito de las tecnologías lingüísticas.
Sobre estas bases regulatorias y el apoyo de estos conjuntos de licencias, debe desarrollarse la planificación y adopción de modelos de explotación y sostenibilidad de los recursos lingüísticos en España. Se requiere una estrategia para la puesta a disposición. Ello implica la integración de recursos lingüísticos en catálogos, la distribución y difusión de los recursos con sus diferentes usos, la concesión de licencias, el mantenimiento y la conservación, las infraestructuras para los recursos lingüísticos, la identificación y el intercambio de recursos, la evaluación y validación, la interoperabilidad y las cuestiones normativas. El desarrollo del plan y modelo exige también determinar los actores en el ecosistema y la cadena de valor de la explotación de datos (desde particulares hasta instituciones educativas y de investigación, responsables políticos, agencias de financiación, Pymes y grandes empresas, proveedores de servicios y medios). En España se cuenta con unos 200 agentes del sector de tecnologías del lenguaje, asociaciones y grupos de investigación. Hay que elegir un modelo de distribución gratuita o de pago dependiendo del tipo de usuario/entidad (Gran empresa, PyME, investigador…) y/o del fin para el que se vaya a utilizar el recurso (investigación, uso comercial…). Cabe especialmente tener en cuenta recursos sobre explotación de datos de ELRA (“Data Management Plan”) y el modelo del proyecto FlaReNet
La presente aportación es una síntesis del estudio “Inteligencia artificial, tecnologías y recursos del lenguaje: políticas y Derecho para la explotación de corpus y bases de datos lingüísticas”, de próxima publicación.

Catedrático de Derecho Constitucional de la Universitat de Valencia (4 sexenios Aneca), Magistrado del TSJ Comunidad Valenciana 2000-2019, vocal Consejo de Transparencia C. Valenciana desde 2015. Doctor y licenciado en Derecho (U. Valencia), Máster en Derechos Fundamentales (ESADE, Barcelona), Licenciado y Diplomado de Estudios Avanzados de Ciencias políticas (UNED). Director de privacidad y derechos de OdiseIA. www.cotino.es