Trazabilidad y explicabilidad de los algoritmos públicos
María Estrella Gutiérrez David
Doctora y profesora. Universidad Complutense de Madrid. Sec. Dptal. Derecho Constitucional. Facultad CC. Información
- #LearningAlgorithmsMatter
- Explíquemelo como si yo tuviera seis años
- Cuánta «inteligencia» contrata nuestra Administración
Cada vez más decisiones administrativas están basadas en la implementación de modelos de clasificación o regresión basados en algoritmos de aprendizaje automatizado o Machine Learning (ML) y el Big Data. Así, por ejemplo, la determinación del perfil de interesados que podrían solicitar un determinado tipo de ayudas públicas (VAN ECK, 2017); la predicción de lugares y momentos de riesgo de comisión de delitos e identificación de potenciales sujetos criminales (CESEDEN, 2013; BABUTA, OSWALD & RINIK, 2018); identificación de establecimientos que deben ser objeto de inspección, sustitución de la red de tuberías de agua según el nivel de concentración de plomo o control de semáforos para optimizar el tráfico de las ciudades (Coglianese & Lerh, 2017); procedimientos de movilidad del profesorado del sistema público de educación (Mancosu, 2019) o de evaluación de su desempeño (O’Neil, 2017); la gestión de las solicitudes de admisión de alumnos a los estudios universitarios de grado superior (CADA, 2019).
Las críticas principales que se hacen a estos sistemas automatizados de toma de decisiones es que pueden favorecer la reglamentación oculta y contra legem, como consecuencia de la traducción de la norma jurídica en lenguaje de código (BOURCIER & DE FILIPPI, 2018); la automatización de los sesgos o complacencia del usuario del sistema en los resultados generados por el algoritmo sin entrar a evaluar la adecuación y validez de los mismos; así como la falta de interpretabilidad de las decisiones adoptadas total o parcial mediante algoritmos ML (BINNS & GALLO, 2019).
1. #LearningAlgorithmsMatter
Cuando desde el Derecho Público se habla, en general, de automatización y algoritmización de la actividad administrativa, formalizada o no, es importante aclarar que no todos los algoritmos pueden generar riesgos de reglamentación oculta y contra legem, favorecer la toma de decisiones opacas y arbitrarias, o tener un impacto lesivo en los derechos de los ciudadanos, por poner algunos ejemplos de los riesgos algorítmicos que se vienen identificando.
Así, por ejemplo, el art. 146.2 de la Ley de Contratos del Sector Público dispone que, ante pluralidad de criterios de adjudicación, se dará preponderancia a aquellos que hagan referencia a características del objeto del contrato que puedan valorarse automáticamente mediante “la mera aplicación de las fórmulas establecidas en los pliegos”. Normalmente, esas fórmulas se identifican en los Pliegos con un algoritmo matemático.
Pero la implementación del algoritmo en la toma de decisiones administrativas puede ser más compleja…
Desde el año 2017, la policía de Durham en el Reino Unido ha venido desarrollando y testando el sistema HART («Harm Assessment Risk Tool») que, a partir de un algoritmo «random forest» y de 34 variables distintas, clasifica a los detenidos bajo custodia policial, según la probabilidad (alta, moderada y baja) de que cometan un delito violento en los dos años siguientes, con la finalidad de remitirlos o no a un programa de rehabilitación, descongestionando así el sistema judicial. Sin embargo, en un estudio publicado donde se evaluaban los riesgos de la implementación del sistema HART, se comprobó que la variable relativa al código postal correspondiente al domicilio de los detenidos condiciona una mayor probabilidad de reincidencia, lo que condicionaba la acción policial en unas zonas en detrimento de otras (OSWALD et al, 2018).
El «bosque aleatorio» es un algoritmo de aprendizaje supervisado, donde ningún árbol (Tree-1, Tree-2, Tree-n) entrena con todos los datos de entrenamiento completos del conjunto del modelo, sino que, con distintas muestras de datos para resolver un mismo problema, de manera que, al combinar los resultados de cada árbol, unos errores se compensan con otros y se consigue una predicción que generaliza mejor (DOMINGOS, 2018; MARTÍNEZ HERAS, 2020).
Con carácter ejemplificativo que no limitativo, se identifican algunos de los tipos de algoritmos ML existentes y las aplicaciones concretas que tienen en el ámbito de la actividad administrativa (TRASK, 2019; ICO, 2017; ICO&ALAN TURING INSTITUTE, 2020):
Fig. 1. Algunas Propiedades y casos de uso de algoritmos ML
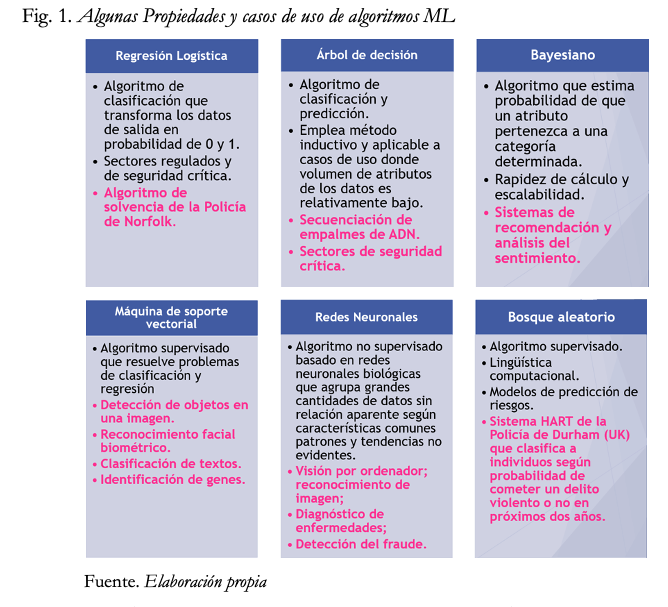
La mayoría de los algoritmos ML más comúnmente utilizados, como el vecino más cercano («Knn nearest neighbour»), árboles de decisión («decision trees»), o redes bayesianas («bayesian networks») son universales en el sentido de que “pueden aprender cualquier cosa”, es decir, puede realizar cualquier tarea o función (tomar decisiones), si son entrenados con una cantidad suficiente de datos adecuados. Aprender de un conjunto finito de datos implica hacer suposiciones y diferentes algoritmos ML “hacen diferentes suposiciones, lo que les convierten en buenos para unas cosas y malos para otras” (DOMINGOS, 2018). Determinar qué algoritmo y qué componentes del sistema generarán las predicciones más precisas es una cuestión de ensayo y error. (COGLIANESE & LEHR, 2017).
La viabilidad y la precisión de las técnicas algorítmicas de aprendizaje automatizado dependen de la clase de problema a resolver o tarea a ejecutar (clasificación o regresión), de la tipología de datos de entrada (inputs) y de los datos de entrenamiento (datos personales/no personales, estructurados/no estructurados), del tratamiento previo de los datos para garantizar su calidad (e.g. completándolos, actualizándolos, eliminando redundancias o datos erróneos, o atribuyendo un valor estimado a aquellos datos que se desconocen), del grado de fiabilidad de la fuente de procedencia de esos datos (e.g. en general se considera que las redes sociales tienen poca fiabilidad), del tipo de algoritmo utilizado y su adecuación al caso de uso y de los parámetros utilizados (ICO & ALAN TURING INSTITUTE, 2020).
2. Explíquemelo como si yo tuviera seis años
Desde Cathy O’Neil (2017) sabemos que los algoritmos pueden ser “armas de destrucción matemática”, y que los modelos algorítmicos de aprendizaje automatizado, en particular, son “por diseño, black boxes inescrutables” a la comprensión del ciudadano medio e incluso la del experto. La herramienta IMPACT se implementó en 2009 por el Distrito de Columbia para evaluar, a partir de un modelo algorítmico, el desempeño del profesorado de los colegios públicos en función de los resultados académicos de los alumnos. La herramienta implementada buscaba “optimizar” el sistema escolar público y reducir las tasas de abandono escolar, desarrollando un modelo algorítmico que calculaba la contribución de un profesor al aprendizaje de un alumno comparando los resultados académicos actuales de sus alumnos en matemáticas y lengua con los resultados de esos alumnos en cursos académicos anteriores y con los de otros alumnos del mismo curso. La consecuencia inmediata de la aplicación de esta herramienta fue el despido de más de 200 profesores en el curso académico 2010-2011, con la paradoja de que, entre los despedidos había también profesores con encuestas de evaluación docente muy positivas por parte de los alumnos y del propio centro. Cuando los docentes cuestionaron la arbitrariedad de las evaluaciones, la respuesta era: “Es el algoritmo y es muy complejo”.
El caso del modelo IMPACT debe hacernos reflexionar sobre los riesgos de la automatización de la actividad administrativa mediante algoritmos inteligentes.
En el ámbito administrativo, la implementación de algoritmos de aprendizaje automatizado puede implicar la “priorización” de determinados datos en detrimento de otros con el riesgo de prácticas discriminatorias de los interesados; la “clasificación individualizada”, a partir de un conjunto de datos de entrenamiento, puede generar falsos positivos o negativos; la “asociación o clusterización” puede establecer correlaciones estadísticas erróneas sin que exista una causalidad real; o el “filtrado” puede incluir o excluir información de acuerdo con unos criterios o reglas que no siempre garantizan el interés general desvirtuando así las políticas públicas (DIAKOPOULOS, 2016).
En general, en los sistemas de aprendizaje automatizado, donde las reglas que rigen el código son inherentemente dinámicas y adaptativas, la evolución autónoma de esos sistemas, redefiniendo constante y autónomamente las reglas a partir de los inputs recibidos o recabados, customizando y adaptando el perfil de los destinatarios individuales de la toma de decisiones automatizada, puede quebrar el principio básico de igualdad ante ley y de no discriminación (HASSAN & DE FILIPPI, 2017), y en consecuencia, producir efectos contra legem al limitar o impedir el ejercicio de derechos que están amparados en la norma jurídica (DE LA CUEVA, 2020).
Asimismo, es un lugar común, en buena parte de la literatura científica el cuestionamiento de estos sistemas en base a que el ciudadano ordinario afectado por una decisión total o parcialmente automatizada con esta clase de algoritmos no puede entender ni los resultados ni el procedimiento seguido por el modelo para llegar a los resultados, precisamente porque el algoritmo implementado es un black box. El problema de la «Caja Negra» se define entonces como la incapacidad para comprender totalmente un proceso de toma de decisiones mediante IA y de predecir las decisiones o resultados de un sistema de IA, incluso por el experto humano que diseñó el modelo (DESAI & KROLL, 2018; BOURCIER & DE FILIPPI, 2018).
En el Reino Unido, la Autoridad de Protección de Datos y Transparencia, el Information Commissioner Office, y el Instituto Alan Turing han elaborado una interesante clasificación de los algoritmos de aprendizaje automatizado según su nivel de explicabilidad u opacidad. Así, por ejemplo, mientras que los algoritmos bayesianos, de regresión logística o de árbol de decisión se caracterizan por “buen nivel de interpretabilidad”, en el caso de la máquina de soporte vectorial y del bosque aleatorio presentan niveles muy bajos de explicabilidad, y por lo que respecta a las redes neuronales se consideran la “epítome de las técnicas de blackbox” (ICO & ALAN TURING, 2020).
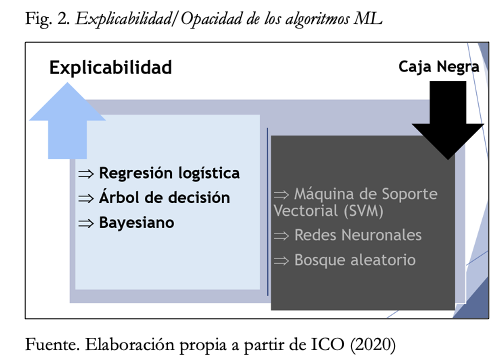
Fig. 2. Explicabilidad/Opacidad de los algoritmos ML
Al referirse al “Estado administrativo automatizado”, CITRON & CALO (2019) consideran que estos sistemas pueden socavar el derecho del interesado al procedimiento administrativo debido, reforzar las desigualdades ya existentes y, a menudo, distorsionar la finalidad de las políticas públicas “al traducir la norma jurídica en código”, con sus sesgos, queridos o no. Y desde la perspectiva del ciudadano en sus relaciones con la Administración automatizada, para algunos autores las consecuencias son claras: “[…] la incapacidad para entender cómo funciona el algoritmo es un vicio que puede en sí mismo afectar la legalidad del procedimiento” (MANCOSU, 2019).
Las consecuencias de una actividad administrativa algorítmica opaca o incomprensible para los destinatarios de las decisiones administrativas empiezan a ser evaluadas por los Tribunales.
En K.W. v. Amstrong (2016), el Tribunal del Distrito de Idaho resolvió que la implementación por el Estado de Idaho de un algoritmo de caja negra para calcular las prestaciones para la ayuda a la dependencia de personas con discapacidad intelectual correspondientes al Programa de ayudas Medicaid vulneraba su derecho al procedimiento (administrativo) legalmente establecido al reducir de forma arbitraria e injustificada la cuantía de la prestación, impidiendo la impugnación efectiva de las resoluciones administrativas que asignaban la cuantía de la prestación final.
En su Sentencia de 17 de agosto de 2018, el Tribunal Supremo de los Países Bajos (Hoge Raad) consideró que un contribuyente tenía derecho a conocer los datos y parámetros utilizados por el programa informático utilizado por la agencia tributaria en la valoración de un inmueble de su propiedad a efectos del devengo del correspondiente impuesto. El Tribunal estimó que esta información “fáctica y relevante” forma parte del expediente administrativo al que debe tener acceso el interesado y constituye una “garantía específica” del correspondiente control jurisdiccional de la decisión administrativa. Para el Hoge Raad, con independencia de que la decisión administrativa, sea total o parcialmente el resultado de un sistema automatizado, el interesado tiene derecho a comprobar y, en su caso, impugnar, la corrección de los datos, parámetros y elecciones realizadas por el modelo, para lo cual el órgano administrativo deberá garantizar la transparencia y la verificación de tal información. En particular, en el caso de los sistemas automatizados, en todo o en parte, que implementan algoritmos de caja negra, el interesado no puede verificar sobre qué base se toma una decisión particular que le afecta. Sin esta transparencia y verificabilidad, se produce una posición desigual de las partes en el proceso. Por tanto, la obligación de la Administración es facilitar el acceso a dicha información de una manera “transparente y verificable”.
Por lo general, se viene observando en estas resoluciones cierta generalización a la hora de abordar las consecuencias de los tratamientos algorítmicos por parte de la Administración. Sin embargo, en los algoritmos ML, las relaciones entre las variables de entrada y los datos de salida del modelo implementado pueden ser simples o complicadas. Así, por ejemplo, las reglas “si-entonces” que pueden describir los modelos de árbol de decisión pueden ser fácilmente interpretadas.
Fig. 3. Modelo de árbol de decisión
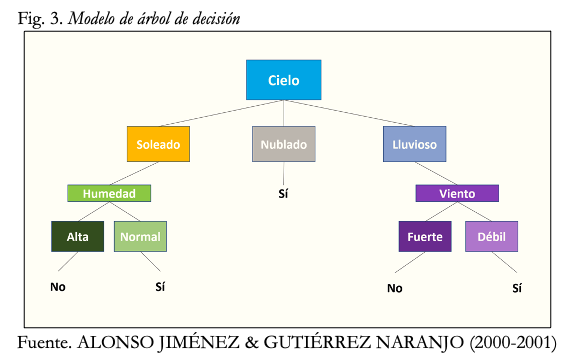
Del mismo modo, las relaciones lineales (donde el valor del resultado se incrementada de manera proporcional al input de entrada), pueden ser más fácil de interpretar que las relaciones no lineales (donde el valor del resultado no es proporcional al input de entrada) o las no-monotónicas (donde el valor del resultado puede incrementar o disminuir según aumente el input de entrada) (BINNS & GALLO, 2019).
En el ámbito de la protección de datos, el RGPD contempla una serie de garantías frente a la aplicación de modelos algorítmicos de IA, al reconocer el derecho del interesado a (i) conocer la “información significativa” sobre la lógica implícita en todo tratamiento automático de datos personales, incluida la elaboración de perfiles, así como la importancia y las consecuencias previstas de dicho tratamiento para el interesado (arts. 13.2.f, 14.2.g, 15.1 h RGPD); (ii) obtener intervención humana por parte del responsable y a expresar su punto de vista; y a impugnar la decisión automatizada, incluida la elaboración de perfiles (art. 22.3 RGPD).
Ante la ausencia de determinación de criterios concretos en el RGPD a la hora de determinar el contenido y alcance del derecho a conocer la información significativa sobre la lógica implícita en todo tratamiento automatizado de datos personales con algoritmos ML o que incluya elaboración de perfiles, el ICO y el Instituto Alan Turing han determinado cuál ha de ser el contenido de la explicación fundamentada que garantice la transparencia e interpretabilidad no sólo del procedimiento seguido por el modelo algorítmico, sino también de los datos utilizados por el modelo. En concreto, la explicación fundamentada debe incluir los extremos que se indican a continuación: (i) Cómo se ha ejecutado y comportado el sistema ML para conseguir el resultado de la decisión; (ii) De qué forma se ha diseñado el sistema e implementado el flujo de trabajo, incluyendo la obtención de los datos de entrada y su preparación y su forma de selección; (iii) Cómo los diferentes componentes del sistema ML han transformado los datos de entrada en datos de salida de una forma específica, de manera que puedan identificarse las variables, las interacciones y los parámetros más significativos del modelo implementado y el peso o influencia real de esos componentes en la producción de un resultado concreto; (iv) De qué manera los componentes técnicos de la lógica subyacente en el resultado pueden proporcionar una evidencia de apoyo a la decisión tomada; (v) En qué medida la lógica subyacente puede transmitida de manera comprensible y fácil a los destinatarios de una decisión; (vi) En qué medida el modelo algorítmico o el conjunto de modelos proporciona un grado de interpretabilidad coherente con el impacto en los destinatarios de la decisión; (vii) Qué tipo de herramientas de explicación suplementaria que ayudan a explicar lo suficientemente bien la complejidad del sistema y a proporcionar una información comprensible y precisa de la lógica subyacente del sistema (ICO & ALAN TURING INSTITUTE, 2020).
Particularmente, resulta decisivo garantizar la corrección de los procedimientos implementados por el algoritmo y los resultados obtenidos para tomar decisiones y sus resultados, mediante la utilización de herramientas complementarias de explicabilidad, especialmente, en el caso de que el modelo opere con algoritmos de caja negra. Así, por ejemplo, un método para gestionar la baja interpretabilidad de un modelo ML puede ser el uso de “explicaciones locales” mediante el empleo de métodos como LIME o Explicación Agnóstica al Modelo de la Interpretabilidad Local que proporciona una explicación específica de un resultado concreto, en lugar de explicar el modelo en general. LIME puede ayudar a detector errores (e.g. ver qué parte específica de una imagen ha conducido al modelo a clasificarla incorrectamente en un sistema de reconocimiento facial biométrico). Sin embargo, ese modelo de explicación no representa la lógica real subyacente en el sistema ML y puede conducir a conclusiones engañosas si se emplea incorrectamente (ICO & ALAN TURING INSTITUTE, 2020; BINNS & GALLO, 2019; COGLIANESE & LEHR, 2017).
Consideramos, sin embargo, que el problema de la explicabilidad/opacidad de los algoritmos ML excede del mero impacto en protección de datos, ya que el uso de algoritmos opacos puede predeterminar el diseño inadecuado de políticas públicas y tener impactos adversos de tipo económico, social, cultural, ambiental o político si existen sesgos derivados de la implementación de dicho modelo opaco cuya mitigación o eliminación no va a ser posible dada la falta de explicabilidad del modelo. Por ello, las recomendaciones del ICO y del Instituto Alan Turing pueden ser también aplicables a otros modelos algorítmicos de actividad administrativa que no impliquen tratamiento de datos personales.
3. Cuánta «inteligencia» contrata nuestra Administración
Evaluar los riesgos de las decisiones administrativas automatizadas mediante modelos algorítmicos ML requiere primero conocer en qué medida nuestra Administración está implementando estos modelos, si existe previamente alguna evaluación de impacto con carácter previo a la implementación del modelo y si en tal implementación se están adoptando las garantías adecuadas para evitar los riesgos identificados al principio (reglamentación oculta, automatización de sesgos y ausencia de explicabilidad del sistema).
En el Derecho comparado, el caso del Reino Unido es especialmente singular porque la Oficina de Inteligencia Artificial ha elaborado la Guía para la Compra Pública de Inteligencia Artificial (Guidelines for AI Procurement, junio 2020). Entre las recomendaciones que la Guía hace a los órganos de contratación a la hora de preparar y elaborar los pliegos para la adquisición de soluciones que implementen IA:
Realizar una evaluación de impacto previa del modelo de IA a licitar que determine los riesgos y beneficios del modelo que incluya: las necesidad internas a cubrir dentro de la organización administrativa y el beneficio público concreto -y no genérico- a satisfacer con el modelo; los impactos humanos y socio-económicos de tu sistema IA; las consecuencias del modelo implementado en tu entorno técnico y procedimental; la calidad de los datos y cualquier inexactitud o sesgo potencial; cualquier potencial consecuencia no intencionada; el ciclo de vida del modelo, incluyendo los requerimientos continuos de soporte y mantenimiento.
Definir claramente en los pliegos del contrato cuál es el beneficio público o interés general concreto del sistema de IA a licitar, considerando posibles soluciones tecnológicas alternativas a la IA que consigan el mismo beneficio público. Los resultados de la evaluación de impacto previa deben ser tenidos en cuenta a la hora de definir claramente los criterios de adjudicación en los pliegos y documentación contractual complementaria.
Incluir en los pliegos requisitos técnicos para evitar la implementación de algoritmos de caja negra y la dependencia tecnológica del contratista («vendor lock-in»), exigiendo como criterio de adjudicación la “explicabilidad e interpretabilidad de los algoritmos” implementados por el modelo, que posibiliten a funcionarios y empleados públicos encargados de la ejecución del contrato o a futuros proveedores (que, por ejemplo, deban actualizar o revisar la solución implementada) comprender el modelo y sus resultados, limitando así el riesgo de dependencia tecnológica del contratista.
Incluir en los pliegos cláusulas éticas que aseguren que el modelo desarrollado por el adjudicatario posibilita la rendición de cuentas algorítmica y evita los resultados discriminatorios y sesgados, o en su caso, exigir como posible requisito de solvencia la experiencia previa del licitador en el desarrollo de modelos éticos de IA.
Establecer mecanismos adecuados de supervisión del sistema IA a lo largo de todo su ciclo de vida, teniendo en cuenta la evaluación de impacto previa, los objetivos concretos del modelo, el caso de uso y el perfil de riesgo del proyecto implementado.
Un análisis de los expedientes de contratación pública, y particularmente, de los pliegos de las licitaciones que se vienen realizando en los últimos años pone de relieve cómo cada vez más las Administraciones españolas y su sector público institucional están licitando soluciones tecnológicas que buscan la implementación de sistemas expertos o de aprendizaje automatizado basados en algoritmos ML.
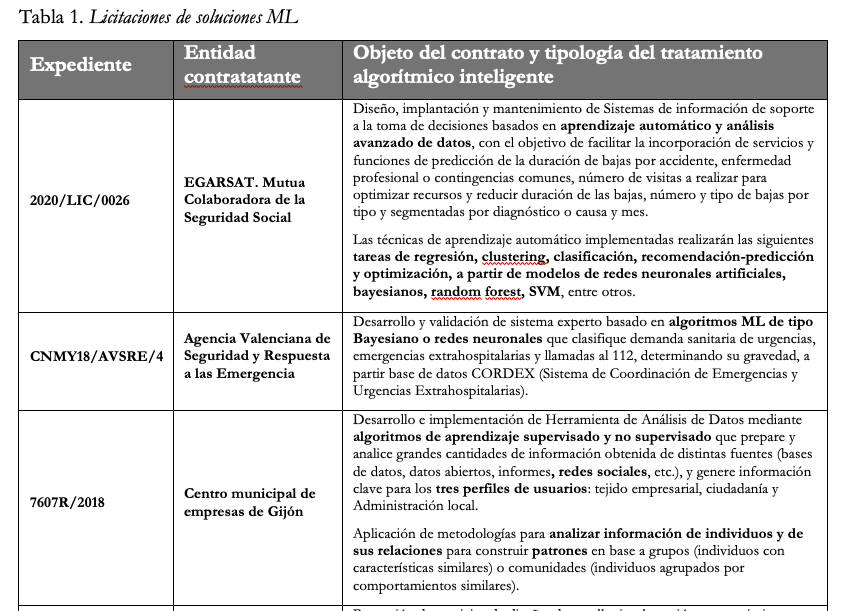
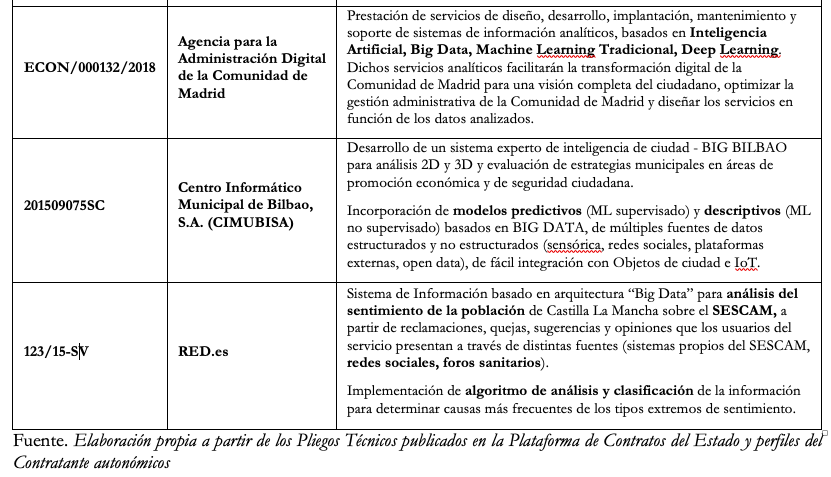
En la siguiente tabla se identifican algunos contratos relevantes licitados en el periodo 2015-2020, donde la entidad contratante ha buscado implementar soluciones tecnológicas que incorporen desarrollos de ML, con mayor o menor explicitud.
Tabla 1. Licitaciones de soluciones ML
Teniendo en cuenta algunas de las recomendaciones realizadas por la Oficina de Inteligencia Artificial del Reino Unido, es posible adelantar algunos de las carencias observadas en las soluciones tecnológicas de IA aquí identificadas a partir de un análisis general de los Pliegos y documentación complementaria.
En primer lugar, no se identifica en la documentación contractual la existencia de análisis de impacto previo del modelo de IA a licitar que determine los riesgos y beneficios de la solución. Tampoco si existe una Evaluación de Impacto en la Protección de Datos en el caso de que la solución a implementar exija el acceso del futuro contratista a datos personales en poder de la entidad contratante o procedentes de fuentes externas (expedientes 7607R/2018, 201509075SC, 123/15-SV). Por ejemplo, en el caso del Expediente 201509075SC entre los casos de usos que debe contemplar la solución tecnológica licitada se encuentra el análisis de flujos en la ciudad que comprende análisis de flujos de ciudadanos y patrones de comportamiento o la monitorización y análisis del sentimiento y alerta de información en social media para la detección temprana de situaciones de alerta o prevención de incidentes en base a información de redes sociales. Desde el punto de vista no sólo de la transparencia contractual, del derecho a la información pública o del derecho a la protección de datos tales evaluaciones de impacto deberían ser objeto de publicidad activa.
Salvo en alguno de los casos analizados (expedientes 2020/LIC/0026 y CNMY18/AVSRE/4), la mayoría de las licitaciones no concretan el algoritmo a implementar por la solución tecnológica licitada, dejándose al contratista la “libertad” de desarrollar el modelo algorítmico que, en principio, satisfaga las necesidades a cubrir por el contrato. Ello significa que el futuro contratista podrá implementar algoritmos de caja negra siempre que se consigan cumplir con las prestaciones exigidas por el objeto del contrato.
En otros casos, la Administración predetermina en los Pliegos el modelo del algoritmo de aprendizaje a desarrollar por el futuro contratista, optando en algunos casos, claramente, por algoritmos de caja negra, como las redes neuronales, bosque aleatorio o SVM (expedientes 2020/LIC/0026 o CNMY18/AVSRE/4), sin que se establezcan requisitos técnicos específicos garantizar la “explicabilidad e interpretabilidad de los algoritmos”, evitando riesgos de automatización del sesgo y de resultados arbitrarios o discriminatorios. De hecho, en ninguno de los Pliegos examinados se encuentra la especificación de esta clase de requisitos.
Tampoco existen cláusulas éticas que limiten la implementación de modelos de IA con impacto adversos en los posibles destinatarios de la actuación administrativa automatizada implementada por la solución tecnológica, ni siquiera, por ejemplo, cuando se introducen de manera transversal y preceptiva criterios sociales que guarden relación con el objeto del contrato.
Se trata, en todo caso, de un análisis preliminar y general de las soluciones que están siendo licitadas y que exigirá desarrollos futuros, así como un examen cauteloso de los documentos contractuales de las soluciones que se vayan licitando, mientras esperamos a que llegue una regulación coherente y garantista de la actuación administrativa automatizada, formalizada o no, más allá del a todas luces insuficiente régimen del art. 41 de la Ley de Régimen Jurídico del Sector Público…, a que nuestros Tribunales se pronuncien sobre el control de la corrección de las decisiones automatizadas, total o parcialmente, o sobre el alcance del derecho de acceso del ciudadano al código fuente y al algoritmo embebido en el mismo, y particularmente, el derecho a una explicación de la lógica subyacente en el mismo…, o que la legislación sobre contratos establezca requisitos específicos para evitar la implementación de sistemas opacos en la línea de lo planteado por el Reino Unido.
5. Referencias
AINOW INSTITUTE (2018). Litigating algorithms: challenging government use of algorithmic decision systems, p. 8. Disponible en https://ainowinstitute.org/litigatingalgorithms.pdf.
ALONSO JIMÉNEZ, JOSÉ A.; GUTIÉRREZ NARANJO, M.A. (2001), Árboles de decisión. Dpto. de Ciencias de la Computación e Inteligencia Artificial, Universidad de Sevilla. Disponible en https://www.cs.us.es/~jalonso/cursos/ra-00/temas/tema-12.pdf
BABUTA, A.; OSWALD, M.; RINIK, C. «Machine Learning Algorithms and Police Decision-Making». Legal, Ethical, and Regulatory Challenges. Universidad de Winchester, RUSI Whitehal Report, 2018, pp. 3-18.
BOURCIER, D.; DE FILIPPI, P. (2018). «La transparence des algorithmes face à l’Open Data: Quel statut pour les données d’apprentissage?», Revue française d’Administration Publique, ENA, 2018, pp. 7, 12-14.
CESEDEN (2013), Big data en los entornos de Defensa y Seguridad. Documento de investigación 03/2013. Instituto Español de Estudios Estratégicos.
COGLIANESE, C. & LEHR, D. (2017) «Regulating by Robot: Administrative Decision Making in the Machine-Learning Era», Faculty Scholarship at Penn Law. 1734.
CRITRON, D.; CALO, R. (2019). The Automated Administrative State. Harvard Kennedy School, Shorenstein Center, 2019. Disponible en https://ai.shorensteincenter.org/ideas/2019/4/3/the-automated-administrative-state.
DE LA CUEVA, J. (2020) «Código fuente, algoritmos y fuentes del Derecho». El Notario del Siglo XXI, Núm. 89, Enero-Febrero. Disponible en: http://www.elnotario.es/index.php/opinion/8382-codigo-fuente-algoritmos-y-fuentes-del-derecho
DESAI, D. R.; KROLL, J. A. (2018). «Trust but verify: A guide to algorithms and the law». Harvard Journal of Law & Technology, vol. 31, núm. 1 (2018), pp. 3, 36 y 38.
DIAKOPOULOS, N. (2016). «Accountability in Algorithmic Decision Making». Communications of the ACM, 59(2), págs. 57-58. DOI:10.1145/2844110.
HASSAN, S.; DE FILIPPI, P., (2017). «The Expansion of Algorithmic Governance: From Code is Law to Law is Code», Field Actions Science Reports, Special Issue 17, pp. 88-90.
INFORMATION COMMISSIER OFFICE (2017). Big data, artificial intelligence, machine learning and data protection, 4 de septiembre, Versión 2.2, pp. 6-10.
INFORMATION COMMISSIONER OFFICE, ALAN TURING INSTITUTE (2020), Explaining decisions made with AI, 20 May-1.0.312.
MARTÍNEZ HERAS, J. (2020), Guía rápida de IArtificial.net. https://www.iartificial.net/inteligencia-artificial/machine-learning/
NÚÑEZ SEOANE, J., Las «actuaciones administrativas automatizadas» en las Leyes 39/2015 y 40/2015. Consejo General de la Abogacía Española, ENATIC, 2017. Disponible en https://www.abogacia.es/2017/02/06/el-bot-administrativo/.
BINNS, R. & GALLO, V. (2019). Automated Decision Making: the role of meaningful human reviews, Information Commissioner’s Office.
OFFICE FOR AI (2020). Guidelines for AI procurement. UK Government. Disponible en https://www.gov.uk/government/publications
OSWALD, M.; GRACE, J.; URWIN, S & BARNES, G. C. (2018). «Algorithmic risk assessment policing models: lessons from the Durham HART model and ‘Experimental’ proportionality», Information & Communications Technology Law, Vol. 27, núm. 2, págs. 223-250.
SCHARTUM, D. W (2016), «Law and algorithms in the public domain», Etikk i praksis. Nordic Journal of Applied Ethics, Núm 1, pág. 16.

Doctora y profesora. Universidad Complutense de Madrid. Sec. Dptal. Derecho Constitucional. Facultad CC. Información