Objetivo del curso y preliminares
Vicente Coll & Pedro J. Pérez
Junio 2017
Objetivo y mecánica del curso
Como sabéis es un curso de introducción a R.
Creemos que al final seréis capaces de utilizar R para cargar datos, arreglarlos, hacer gráficos y tablas, e informes en Rmarkdown.
Intentaremos que el curso sea fundamentalmente práctico, PERO se necesita un mínimo de conocimiento de como funcionan algunas cosas y también hay que conocer un poco la jerga que se utiliza en la comunidad R.
En lugar de presentar todos los pormenores de R de manera lineal, se irán presentando distintos aspectos de R conforme se vayan necesitando; es decir, no vamos a presentar R como un lenguaje de programación sino como una herramienta para hacer análisis estadísticos.
En la carpeta del curso tenéis todos los materiales: tutoriales, algunos datos, etc….
1. Preliminares
Curso de introducción a R.
En el curso se trabajará con R a través de RStudio y utilizando Rprojects.
Se presentarán las principales funciones de R-base, pero (en general) se priorizará el uso de un conjunto de paquetes englobados bajo el nombre genérico de tidyverse.
Se enfatizará la importancia de la investigación reproducible, para lo cual los informes de resultados se generarán con Rmarkdown
2. Primeras ideas
En la introducción han aparecido unas cuantas palabras nuevas. Todas ellas empiezan con la letra R:
- R
- RStudio
- R-base y packages
- Reproducible Research
- Rprojects
- Rmarkdown
Antes de empezar el curso tenemos que tener una idea de qué significan. Vamos a ello:
R
¿Qué es R?
R es un lenguaje de programación y un entorno para el análisis estadístico y gráfico.
R es parte del sistema GNU y se distribuye bajo la licencia GNU GPL; es decir, es software libre y gratuito.
Es multiplataforma: está disponible para Windows, Macintosh y GNU/Linux.
R fue inicialmente creado por R. Ihaka y R.Gentleman de la Universidad de Auckland en 1993, pero actualmente, el entorno R es el resultado de la colaboración de toda una comunidad de usuarios.
A partir de 1997 el desarrollo del código fuente (o base-R) de R es llevado por un grupo de programadores conocido como “The R-core team”.
La página web oficial de R se llama: The R Project for Statistical Computing. Allí podrás encontrar toda la información oficial acerca de R.
Puedes ver la documentación oficial de R con
help.start(). ¿Hace falta leerla? No
¿Por qué R?
Creemos que es el mejor programa para hacer análisis de datos
R es ampliamente extensible mediante funciones y paquetes
R forma parte de un proyecto colaborativo y abierto. Sus usuarios pueden publicar paquetes que extienden su configuración básica. Existe un repositorio oficial de paquetes: Comprehensive R Archive Network o CRAN
R (junto con sus paquetes) puede implementar una gran variedad de técnicas estadísticas y gráficas.
La comunidad R es muy prolífica y colaborativa: R-bloggers
Precisamente estos 2 aspectos (abundancia de paquetes y comunidad de usuarios) son claves en el éxito de R
Si no nos acabas de creer, o quieres leer algo sobre la importancia y capacidades de R puedes hacerlo aquí o aquí.
Instalación de R
- Sólo tienes que ir a CRAN y descargar la distribución de R adecuada para tu sistema operativo
RStudio
¿Qué es RStudio?
La interfaz de usuario (GUI, Graphical User Interface) de R no es muy amigable ni versátil, así que interactuaremos con R a través de RStudio.
RStudio es un programa que nos permitirá interactuar con R de forma más amigable, además de facilitar muchas de las tareas de programación y análisis de datos en R.
En términos más técnicos, RStudio es más que una GUI, es un entorno de desarrollo integrado para R, en inglés ‘integrated development environment’ o IDE.
El actual científico jefe de RStudio es Hadley Wickham. Wickham es uno de los más prolíficos desarrollador de paquetes para R y creador de un nuevo estilo de programar y analizar datos en R conocido como ‘tidyverse’. Muchos de los packages que utilizaremos en el curso han sido desarrollados por él.
Instalación de RStudio
La versión de escritorio de RStudio también es libre y gratuita. Se puede descargar aquí. Tienes que descargarte el ‘installer’ adecuado para tu sistema operativo.
Al abrir RStudio verás que tiene 4 paneles: la consola es lo más parecido a R y allí se pueden ejecutar instrucciones de R directamente.
R-base y Packages
Todas las funciones, datos y utilidades de R disponibles para ser utilizadas están almacenados en paquetes (packages en inglés).
Un paquete es simplemente un conjunto de funciones, datos y documentación; por ejemplo el paquete
varssirve para estimar modelos VAR.Cuando abrimos RStudio, se cargan automáticamente 7 paquetes: son los paquetes de R-base. Puedes ver sus nombres tecleando en la consola
loadedNamespaces()Con los 7 packages de R-base se pueden hacer análisis estadísticos completos; sin embargo, la comunidad de usuarios de R publica constantemente nuevos paquetes que extienden los métodos y capacidades de R
La gran cantidad de paquetes disponibles es una de las claves del éxito de R. Ya aprenderemos a instalar paquetes.
Podemos ver los paquetes que tenemos instalados con
library().El repositorio oficial de packages de R está en The Comprehensive R Archive Network o CRAN
En enero de de 2017 se superaron los 10.000 pkgs en CRAN. Puedes ver un listado agrupado por temas aquí. Aunque quizás sea más útil para bucear entre los +10.000 packages este buscador de R-documentation
Puedes ver una lista con los packages más populares aquí
Si quieres ver una AWESOME lista de recursos de R pincha aquí
Para tener una idea de lo dinámica que es la comunidad R os recomendamos que durante las 2 semanas de duración del curso sigáis a R-bloggers en Twitter(@Rbloggers).
2 ejemplos curiosos
Por ejemplo, veamos dos análisis curiosos que hemos visto últimamente:
- Mapeo de datos sobre biodiversidad: llegué aquí por el artículo rOpenSci: cómo acceder de forma reproducible a repositorios de datos públicos, que utiliza el package rgeospatialquality
# http://revistaecosistemas.net/index.php/ecosistemas/article/view/1416
# https://github.com/ropenscilabs/rgeospatialquality
# install.packages("rgbif")
# install.packages("ggmap", type = "source")
# install.packages("mapr")
library("rgbif")
library("mapr")
dat <- occ_search(scientificName = "Ursus americanus", limit = 50)
map_ggmap(dat, zoom = 4)
- Proyecto Gutenberg(https://www.gutenberg.org/)
# https://github.com/ropenscilabs/gutenbergr
# install.packages("gutenbergr")
library("dplyr")
library("gutenbergr")
df <- gutenberg_works()
df <- gutenberg_works(languages = "es")
df <- gutenberg_works(languages = "es") %>% filter(author == "Cervantes Saavedra, Miguel de")
dfa <- df %>% filter(grepl("Cervantes.", author))
Quijote <- gutenberg_download(2000, meta_fields = c("title", "author"))Una vez tenemos El Qujote, podemos hacer un wordcloud (ya lo veremos!!):

Reproducible Research
Investigación Reproducible (IR) o Reproducible Research (RR), en inglés.
Cada vez más se requiere que los estudios científicos sean reproducibles. Creemos que se convertirá en un futuro, posiblemente lejano, en el estándar
Hacer una investigación reproducible es COSTOSO; de hecho, hay cursos completos sobre el tema, por ejemplo éste, y muchos proyectos que tratan de promoverla; por ejemplo éste que pretende favorecer el uso de datos abiertos a través de R.
Afortunadamente, cada vez hay más herramientas que facilitan hacer la IR: Make, Git, Docker, Pandoc, Knitr, markdown ….
Hacer una investigación (completamente) reproducible no siempre es posible; OK, PERO al menos acercarse … un poco.
En el entorno R cada vez es más fácil acercarse al ideal de la IR.
IR no significa sólo proporcionar los datos originales. Como mínimo-mínimo se debería:
- proporcionar los datos originales (obviamente documentar las fuentes)
- todo el proceso a través de código (scripts)
- documentar el proceso de trabajo
En concreto, en el curso usaremos RStudio para hacer análisis de datos. Gestionaremos los análisis a través de Rprojects y generaremos los informes y resultados del análisis con documentos en Rmarkdown.
Estos documentos
.Rmdson reproducibles. En breve veremos que significa esto y sus utilidades tanto para la investigación como para la DOCENCIA
Rprojects
Gestionar tus análisis utilizando Rprojects tiene ventajas: puedes gestionar varios proyectos a la vez y facilita el compartir tus análisis; es decir, favorece la RR.
Podemos pensar que un Rproject es una carpeta, pero es más que eso: cada Rproject tiene su propio directorio de trabajo, espacio de trabajo (environment), historial de instrucciones; además, permite crear una estructura de carpetas donde guardar los documentos asociados al proyecto en carpetas separadas (p.ej: una carpeta para datos, otra para imágenes, …).
Cuando abres un Rproject en RStudio ocurre lo siguiente:
- Comienza un nuevo proceso de R
- El directorio de trabajo se fija a la carpeta que contiene el Rproject.
- Se restaura la sesión tal y como estaba la ultima vez que se cerró el proyecto (pestañas activas, objetos etc…)
Siempre que un proyecto requiera una estructura de subcarpetas, merece la pena gestionarlo a través de un Rproject.
Cuidado con los paths
Un gran inconveniente para conseguir informes (plenamente) reproducibles son los paths o rutas de ficheros. Si un programa necesita llamar a un fichero de datos, has de especificar la ruta y si alguien quiere ejecutar tus scripts en su ordenador deberá cambiar la ruta.
Trabajar con Rprojects permite solventar este problema, ya que el directorio de trabajo del Rproject coincide con la carpeta donde está alojado el Rproject y esto permite (ya lo veremos en el próximo tutorial) trabajar con rutas (o paths) relativas en lugar de absolutas. (!!)
- En palabras de Jenny Bryan aquí , si empiezas tus scripts con
setwd(), Jenny nos dice PLEASE STOP DOING THAT !!
This makes your script very fragile, hard-wired to exactly one time and place. As soon as you rename or move directories, it breaks. Or maybe you get a new computer? Or maybe someone else needs to run your code?
- Para Jenny la solución es usar el pkg
here, y tiene razón, pero nosotros (de momento) sólo usaremos Rprojects (suficiente!!).
RMarkdown
Los documentos RMarkdown son ficheros con extensión
.Rmd.Si acabas utilizando R para hacer análisis estadísticos, los ficheros
.Rmdte permitirán escribir muy-muy fácilmente informes, tutoriales y transparencias para presentaciones.Estos ficheros .Rmd son (plenamente) reproducibles.
Es un poco largo, que no difícil, de explicar ahora, pero podemos pensar que RMarkdown = knitr + chunks + markdown + pandoc (puff!!) ….
… pero muy-muy sencillo de hacer y muy-muy útil, tanto en docencia como en investigación.
Lo veremos, pero en esos ficheros .Rmd se mezclan trozos de texto escritos en Markdown (narratives) y trozos con código R (chunks) para hacer análisis estadísticos.
Estos ficheros se procesan con un paquete de R llamado
knitrdesarrollado por Yihui Xie … y salen unos informes o transparencias fantásticas … en una gran variedad de formatos.Con RStudio es muy fácil: solo hay que usar los menús desplegables de RStudio para crear un documento Rmarkdown, escribir lo que quieres contar y darle al botón Knitr y
knitrtejerá el documento y lo transformará a …. pdf, word, html …
3. Recursos para aprender R
Nosotros recomendamos :
Mas recursos de R:
Como veis, hay muchísimos!!!, tanto libros, como blogs, como MOOCs, vídeos etc…
Por ejemplo, aquí tienes dos post con propuestas completas para aprender R (con links a los materiales):
- Si al final acabas utilizando R para, seguramente acabaras utilizando éste sitio. Es Stack Overflow, una comunidad de programadores, en la que muchas veces resolverás las dudas que te puedan surgir.
Cuestiones de repaso
- ¿Cual es la diferencia entre R y RStudio?
- ¿Qué es un package? ¿Para qué sirven?
- ¿Qué es R-base o base-R?
- ¿Por qué utilizamos Rprojects?
- Haga una frase que tenga sentido con las palabras knitr, archivo, markdown, Rmd, Yihui Xie, package.
Nota: puedes ver las soluciones al final, PERO está prohibidísimo!! 🙀
Bibliografía
R en Nada es Gratis. Post en castellano sobre las bondades de R como entorno para el análisis de datos
Why R is the best data science language to learn today. Un post sobre la importancia de R en el campo de análisis de datos o Data Science.
Data Science in Minutes. Una buena primera aproximación a R. Un post que se lee en 15 minutos y presenta más o menos los tópicos que veremos en el curso.
Why you should master R. Otro post, esta vez dando consejos sobre como afrontar el aprendizaje de R.
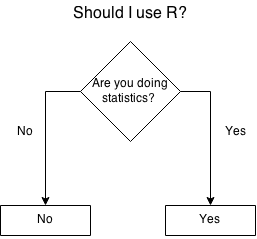
Adopting R for experienced developers. A pesar del título, es un buen post sobre orígenes de R, consejos de como afrontar su aprendizaje y … más cosas. Tiene un gráfico/flowdiagram que te ayudará a decidir si te merece la pena aprender R.
Why has R, despite quirks, been so successful?. Post muy corto pero que muestra (desde un punto de vista técnico de programación) las ventajas de R
CRAN now has 10,000 R packages. Here’s how to find the ones you need. Post que te ayuda a encontrar el package apropiado para tus necesidades.
Investigación reproducible. Post en español sobre la importancia de la IR
Investigación reproducible con R. Unas buenas transparencias en castellano sobre RR (o IR) y Rmarkdown.
Hey, prohibido mirar las soluciones 😄!!!
Soluciones
Hey, prohibido mirar las soluciones 😄!!!
1.
¿Cual es la diferencia entre R y RStudio?
Bueno, en realidad hay muchas diferencias porque los dos son programas de ordenador (libres y gratuitos), PERO programas distintos!!!
Podemos pensar que la principal diferencia es que R es quien realmente hace los cálculos, gráficos etc… y RStudio es un programa que nos permite usar R de forma más cómoda.
2.
¿Qué es un package? ¿Para que sirven?
Un package es un conjunto de funciones, datos y documentación que están agrupados en una carpeta.
Los packages sirven para algo; por ejemplo el package tabulizer sirve para hacer unas tablas muy chulas. El repositorio oficial de packages es CRAN. Los packages incluyen funciones para hacer algo (por ejemplo tablas), a lo mejor datos y documentación para enseñar como se utilizan las funciones
3.
¿Qué es R-base o base-R?
R-base en realidad el código fuente de R y un grupo de paquetes básicos (7) que se cargan siempre que se abre R. Con los paquetes de R-base ya se pueden hacer análisis estadísticos completos.
4.
¿Por qué utilizamos Rprojects?
Para no tener problemas con el working directory
Facilita la RR, ya sea con otras personas o con nosotros mismo en el futuro. Ya que al estar todo el proyecto encapsulado en una sola carpeta y con el working directory es la misma carpeta. Los scripts funcionaran en el ordenador de otra persona y también en nuestro futuro ordenador.
5.
Haga una frase que tenga sentido con las palabras knitr, archivo, markdown, Rmd, Yihui Xie, package, reproducible, pandoc
Por ejemplo: Yihui Xie es un programador que ha desarrollado el package knitr. Este package permite mezclar texto y análisis estadísticos hechos con R en archivos con extensión .Rmd. Esto favorece la investigación reproducible (RR). En estos archivos Rmarkdown, el texto debe estar escrito en Markdown. Cuando procesas los archivos .Rmd con knitr y pandoc puedes convertirlo fácilmente a diferentes formatos: html, pdf, word, ….
Esto parece muy complicado, pero en RStudio está chupado.