Data munging: the tidyverse way
Vicente Coll & Pedro J. Pérez
Junio 2017
1. Introducción
En el tutorial anterior aprendimos a cargar datos en R. Sin embargo, es difícil que en una aplicación real tengamos los datos tal y como los necesitamos para hacer nuestro análisis. Habitualmente tendremos que trabajar los datos para arreglarlos. Este proceso, que en castellano podría llamarse “limpieza” o procesado de datos, se conoce en inglés como data munging or data wrangling.
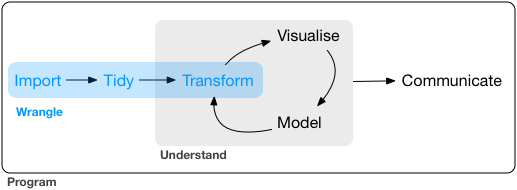
Data wrangling from http://r4ds.had.co.nz/wrangle-intro.html
Se suele decir que el procesado/limpieza de los datos suele ocupar un 80% del tiempo de un análisis de datos. Quizás sea una cifra un poco exagerada, pero, en cualquier caso, es una tarea que ocupa tiempo y que puede llegar a ser tediosa y frustante si no se dispone de las herramientas adecuadas.
Classroom data are like teddy bears; real data are like a grizzly with salmon blood dripping out its mouth. —- [@JennyBryan]
En este tutorial aprenderemos a limpiar y transformar datos en R. Priorizaremos la nueva forma de hacer las cosas en R (o workflow) conocido como tidyverse.
[Aquí] tenéis un post sobre las diferencias entre las funciones de R-base y las del tidyverse para el procesado de datos, y [aquí] otro post de un nuevo convencido de las bondades de esta nueva forma de manipular datos en R. Como ejemplo:
Up until last year my R workflow was not dramatically different from when I started using R more than 10 years ago. Thanks to several R package authors, most notably Hadley Wickham, my workflow has changed for the better using dplyr, magrittr, tidyr and ggplot2. Given how much I’ve enjoyed the speed and clarity of the new workflow, I thought I would share a quick demonstration
Tidyverse
¿Qué es esto del tidyverse?
Con la palabra tidyverse se hace referencia a una nueva forma de afrontar el análisis de datos en R. Se hace uso de un grupo de paquetes que trabajan en armonía porque comparten ciertos principios, como por ejemplo, la forma de estructurar los datos.
La mayoría de estos paquetes han sido desarrollados por (o al menos con la colaboración de) Hadley Wickham.
No es necesario, pero si quieres conocer un poco mejor qué es el tidyverse, puedes hacerlo leyendo The tidy tools manifesto. Está cita es un buen referente de la filosofía o enfoque del tidyverse
“Programs must be written for people to read, and only incidentally for machines to execute –– Hal Abelson
Solamente citaré 2 principios del tidyverse:
- Los scripts deben ser “fácilmente” legibles por las personas
- Resolver problemas complejos encadenando funciones simples con el operador
%>%
The pipe (%>%)
Este operador es básico en el tidyverse, ya que permite encadenar llamadas a funciones para así realizar de forma sencilla transformaciones de datos complejas. El operador pipe se lo debemos a Stefan Bache en su pkg magrittr.

En palabras, lo que hace este operador es pasar el elemento que está a su izquierda como un argumento de la función que tiene a la derecha;
Con expresiones el operador pipe hace:
| – | ||
|---|---|---|
| f(object, argumentos de la función) | ES EQUIVALENTE a | object %>% f(argumentos de la función) |
| – |
Se entiende mejor con un ejemplo sencillo. Las siguientes tres instrucciones de R hacen exactamente lo mismo: permiten ver las 4 primeras filas del iris dataset.
head(iris, n = 4)
iris %>% head(. , n = 4)
iris %>% head(n = 4) #- %>% pasa lo que hay a la derecha como argumento de la funciónPara terminar de entender la sintaxis del operador pipe. Intentad ver si entendéis la siguiente instrucción:
4 %>% head(iris, .)Si no lo sabéis, siempre podéis ejecutar la instrucción en la consola de RStudio
Esto está bien, pero no supone ninguna ventaja, sólo es una forma distinta de ejecutar o llamar a una función. Lo importante para nosotros es que las pipes se pueden encadenar.
El operador pipe podemos leerlo como “entonces” y permite encadenar sucesivas llamadas a funciones.Por ejemplo:
df %>% filter(X1 > 400) %>% group_by(X2) %>% summarise(media = mean(X3))La anterior linea de código R hace:
- coge los datos del dataframe df y selecciona (o filtra) las filas que cumplen que el valor de X1 es, mayor que 400, entonces (o después)
- agrupa los datos por la variable X2, entonces
- calcula la media de X3
En conjunto, encadenando las 3 funciones hemos seleccionado las filas de las personas que tienen un salario (X1) mayor de 400, agrupado las filas que cumplen esta condición por genero (X2) y calculado la media para cada uno de los grupos; es decir, hemos calculado la media salarial para Hombres y Mujeres, teniendo en cuenta sólo a los individuos con salario superior a 400.
Con esta nueva sintaxis (que permite el operador pipe) ya no necesitamos anidar funciones, sino que las instrucciones van una después de otra. Es mucho más fácil de leer y de escribir.
Prueba a ver si entiendes que hace la siguiente linea de código (ya sabes que siempre puedes ejecutarla y ver que hace):
letters %>% paste0("--", . , "--") %>% toupper De forma más técnica. Aquí podéis ver el funcionamiento del operador pipe:
library("magrittr")
#-------- Rule 1
f(xx) es equivalente a xx %>% f
#-------- Rule 2
g(xx, n = 5)
xx %>% g(n = 5)
#-------- Rule 3
g(f(xx), n = 5)
xx %>% f %>% g(n = 5)
Se lee como "Take xx then do f then do g with n = 5".
#-------- Rule 4
f(y, x)
x %>% f(y, .)
#-------- Rule 5
f(y, z = x)
x %>% f(y, z = .)
#(!!!!)------------- BONUS: The input to the pipeline can itself be a placeholder!!
num_unique <- . %>% unique %>% length
num_unique(iris$Species)
iris$Species %>% num_uniqueBien, ya sabemos como funciona “the pipe”. Volvamos al tidyverse y a aprender a manipular datos en R.
Principales pkgs del tidyverse
Los principales packages del tidyverse son:
readr: para importar datostidyr: para convertir los datos a tidy datadplyr: para manipular datosggplot2: para hacer gráficospurrr: para functional programming
- Finalmente estos pkgs se han agrupado en un solo package, el
tidyversepackage.
2. Tidy data (tidyr)
If I had one thing to tell biologists learning bioinformatics, it would be write code for humans, write data for computers. —-— Vince Buffalo (@vsbuffalo)
Y si vamos a manejar datos con R y a la manera del tydiverse, como Jenny Bryan señala en su excelente tutorial sobre tidy data:
An important aspect of “writing data for computers” is to make your data TIDY. —- Jenny Bryan
Antes de comenzar a manipular los datos conviene saber que se entiende por tidy data. Es fácil!!
¿Qué son los tidy data?
Ahora lo veremos, pero enfatizar que si los datos son tidy (si siguen ese formato) será más fácil trabajar con ellos con el tidyverse, ya sea para manipularlos o para hacer gráficos.
De forma sencilla, tidy data son simplemente datos organizados de una determinada manera. Además es justo de la manera a la estamos familiarizados. De forma más precisa se puede leer [aquí] :
Tidy datasets provide a standardized way to link the structure of a dataset (its physical layout) with its semantics (its meaning). —– Hadley Wickham
La mayoría de datos en Ciencias Sociales se ajustan a la categoría de datos tabulares; es decir, están organizados en filas y columnas. En R este tipo de datos se almacenan en dataframes (o tibbles). En esencia, un dataframe será tidy si cada columna es una variable y cada fila es una unidad de análisis (persona, país, región etc…)
A dataset is a collection of values. Every value belongs to a variable and an observation. A variable contains all values that measure the same underlying attribute (like height, temperature, duration) across units. An observation contains all values measured on the same unit (like a person, or a day, or a race) across attributes

Tidy data from http://r4ds.had.co.nz/tidy-data.html
No parece muy alejado de lo que estamos acostumbrados. Pero …. desarrollemos la idea un poco más.
Un ejemplo de datos (no tidy)
Supongamos que la variable (o atributo) a medir es el salario y la unidad de análisis las personas. Hemos recogido datos para 3 personas. Veámoslos:
| year | Pedro | Carla | María |
|---|---|---|---|
| 2014 | 100 | 400 | 200 |
| 2015 | 500 | 600 | 700 |
| 2016 | 200 | 250 | 900 |
Entendemos perfectamente estos datos, visualmente son cómodos, pero ¿son tidy data? NO* porque los individuos (o unidades de análisis) están en columnas.
Un ejemplo de datos (tidy* pero wide)
Exactamente los mismos datos podrían estructurarse así:
data_2 <- data.frame(names = c("Pedro", "Carla", "María"),
W_2014 = c(100, 400, 200),
W_2015 = c(500, 600, 700),
W_2016 = c(200, 250, 900) )
data_2| names | W_2014 | W_2015 | W_2016 |
|---|---|---|---|
| Pedro | 100 | 500 | 200 |
| Carla | 400 | 600 | 250 |
| María | 200 | 700 | 900 |
También es un formato fácil de entender por nosotros, pero ¿son tidy? SI*, pero …
Es el formato al que estamos más acostumbrados (variables en columnas e “individuos” en filas).
En jerga del tidyverse este formato de datos es “wide” (o ancho)
Podemos trabajar tranquilamente con el anterior formato, PERO, si queremos sacar todo el provecho al tidyverse es mejor tener los datos en long format.
Un ejemplo de datos (tidy-tidy y long)
data_3 <- data.frame(names = c("Pedro", "Carla", "María", "Pedro", "Carla", "María", "Pedro", "Carla", "María"), year = c("2014", "2014", "2014", "2015", "2015", "2015", "2016", "2016", "2016"), salario = c(100, 400, 200, 500, 600, 700, 200, 250,900) )
data_3| names | year | salario |
|---|---|---|
| Pedro | 2014 | 100 |
| Carla | 2014 | 400 |
| María | 2014 | 200 |
| Pedro | 2015 | 500 |
| Carla | 2015 | 600 |
| María | 2015 | 700 |
| Pedro | 2016 | 200 |
| Carla | 2016 | 250 |
| María | 2016 | 900 |
Este formato, es más difícil de leer para nosotros, pero es más eficiente para los ordenadores. Y los datos los procesan los ordenadores!!
gather() y spread()
funciones para pasar de wide a long (& viceversa)
Ya hemos dicho que los packages del tidyverse trabajan mejor con tidy data en formato “long”. ¿Qué hacemos si tenemos un dataframe en formato wide? Pues pasarlo a long. Afortunadamente tenemos un pkg que hace muy sencillo pasar los datos de wide a long (y viceversa): tidyr. Concrétamente usaremos las funciones gather() y spread()
El siguiente diagrama ilustra el uso de gather() y spread()

tidyr: wide & long format
De wide a long format con gather()
La función gather() convierte dataframes de wide a long format
#- de wide(ancho) a long(largo) format
library(tidyr)
#- data_2 está en formato ancho (wide)
data_wide <- data_2
#- la funcióm gather() transforma los datos de formato ancho(wide) a formato largo(long)
data_long <- data_wide %>% gather(periodo, salario, 2:4)Si quisiéramos arreglarlo un poco más:
#(!!) gsub() encuentra el texto "W_" en la columna "time" y lo sustituye por ""
data_long <- data_long %>% mutate(periodo = gsub("W_", "" , periodo))De long a wide format con spread()
Pasar pasar de long a wide, tidyr tiene la función spread()
#- spread() convierte un df de long a wide
data_wide2 <- data_long %>% spread(periodo, salario)separate() y unite()
funciones para separar y unir columnas
El pkg tidyr contiene otras 2 funciones: separate() y unite() que facilitan el separar y unir columnas. Veamos un ejemplo:
df <- data.frame( names = c("Pedro_Navaja", "Bob_Dylan", "Cid_Campeador"),
year = c(1978, 1941, 1048) )
df names year
1 Pedro_Navaja 1978
2 Bob_Dylan 1941
3 Cid_Campeador 1048Separamos la primera columna:
df_a <- df %>% separate(names, c("Nombre", "Apellido"), sep = "_")
df_a Nombre Apellido year
1 Pedro Navaja 1978
2 Bob Dylan 1941
3 Cid Campeador 1048Si queremos volver a unirlos, tendríamos que:
df_b <- df_a %>% unite(Nombre_y_Apellido, Nombre:Apellido, sep = "&")
df_b Nombre_y_Apellido year
1 Pedro&Navaja 1978
2 Bob&Dylan 1941
3 Cid&Campeador 10483. DPLYR
dplyr es un pkg que permite manipular datos de forma intuitiva. Tiene 5 funciones o verbos principales. Cada uno de ellos hace “una sola cosa”, así que para realizar transformaciones complejas hay que ir concatenando instrucciones sencillas. Esto se hace con el operador pipe (%>%)
dplyr basics
Tras mucho pensar como estructurábamos este apartado del tutorial, al final nos hemos decidido por usar intensivamente los materiales del curso STAT 545. ¿que quien ha se encarga del curso? Pues Jenny Bryan (always rocks!!). Puedes encontrarlos [aquí]
Dplyr tiene muchas funciones, pero las principales son 5-6, luego las veremos. Con ellas se pueden resolver la mayoría de problemas asociados a la manipulación de datos.
Cada función (o verbo) hace una sola cosa, pero concatenándolas con %>% permiten resolver cuestiones complejas.
Todas las funciones tienen una estructura o comportamiento similar:
- el primer argumento siempre es un df
- los siguientes argumentos describen que hacer con los datos
- el resultado es siempre un nuevo df
Por ejemplo, filter(df, X1 >= 10) devuelve un df con las filas del df original que cumplen la condición de que la variable X1 es mayor o igual a 10
Podemos escribir la anterior instrucción de 3 formas. La más utilizada es la última:
df_new <- filter(df, X1 >= 10)
df_new <- df %>% filter(. , X1 >= 10)
df_new <- df %>% filter(X1 >= 10)4. Principales funciones de dplyr
Hay 6-7 principales.
filter(): permite seleccionar filas (que cumplen una o varias condiciones)arrange(): reordena las filas (arrange()).rename(): cambia los nombres de las columnas (variables)select(): selecciona columnas (variables)mutate(): crea nuevas variablessummarise(): resume (colapsa) unos cuantos valores a uno sólo. Por ejemplo, calcula la media, moda, etc… de un conjunto de valores
Hay una séptima:
group_by(): permite agrupar filas en función de una o varias condiciones
Veámoslas una a una. Veremos sólo algunos ejemplos. Ya iremos practicando
filter()
Esta función (o verbo) se utiliza para seleccionar filas de un dataframe (df). Se seleccionan las filas que cumplen una determinada condición o criterio lógico. Por ejemplo:
#- vamos a trabajar con los datos del [pkg gapminder](https://github.com/jennybc/gapminder)
df <- gapminderSeleccionamos las filas que cumplen determinados criterios:
#- Observaciones de España (country == "Spain")
df %>% filter(country == "Spain")
#- filas con valores de "lifeExp" < 29
df %>% filter(lifeExp < 29)
#- filas con valores de "lifeExp" entre [29, 32]
aa <- df %>% filter(lifeExp >= 29 , lifeExp <= 32)
aa <- df %>% filter(lifeExp >= 29 & lifeExp <= 32)
aa <- df %>% filter(between(lifeExp, 29, 32))
#- observaciones de paises de Africa con lifeExp > 32
aa <- df %>% filter(lifeExp > 72 & continent == "Africa")
#- observaciones de paises de Africa o **Asia** con lifeExp > 32
aa <- df %>% filter(lifeExp > 72 & continent %in% c("Africa", "Asia"))
aa <- df %>% filter(lifeExp > 72 & (continent == "Africa" | continent == "Asia")) La función filter() tiene muchas más posibilidades. ya las iremos viendo. PERO si quieres ver un resumen de las posibilidades del pkg dplyr mira su CHEAT SHEET. La versión antigua de la Cheat sheet contiene también las funciones de tidyr.
slice() y top_n() tambien pueden ser muy útiles para seleccionar filas
Señalamos 2 funciones más para filtrar filas:
slice(): filtra filas por su posición (física en el df)top_n(): filtra filas por su ranking (según el valor de alguna columna)
#- selecciona las observaciones de la decima a la quinceava
df %>% slice(c(10:15))
#- selecciona las observaciones de la 12 a 13 Y de la 44 a 46, Y las 4 últimas
df %>% slice( c(12:14, 44:46, n()-4:n()) ) #- AQUI hay un error, teneis q arreglarlo#- selecciona las 3 filas con mayor valor de lifeExp
df %>% top_n(3, lifeExp)
#- selecciona las 4 filas con MENOR valor de pop
df %>% top_n(-4, pop) arrange()
Esta función (o verbo) se utiliza para reordenar las filas de un dataframe (df).
#- vamos a trabajar con los datos del [pkg gapminder](https://github.com/jennybc/gapminder)
df <- gapminder
#- ordena las filas de MENOR a mayor según los valores de la v. lifeExp
aa <- df %>% arrange(lifeExp)
#- ordena las filas de MAYOR a menor según los valores de la v. lifeExp
aa <- df %>% arrange(desc(lifeExp))
#- ordenada las filas de MENOR a mayor según los valores de la v. lifeExp.
#- Si hay empates se resuelve con la variable "pop"
aa <- df %>% arrange(lifeExp, pop) rename()
Esta función permite cambiar los nombres de las columnas (o variables si los datos son tidy)
#- vamos a trabajar con los datos del [pkg gapminder](https://github.com/jennybc/gapminder)
df <- gapminder
#- cambia los nombres de lifeExp y gdpPercap a life_exp y gdp_percap
df %>% rename(life_exp = lifeExp, gdp_percap = gdpPercap)La función rename() es útil pero, enseguida veremos que la siguiente función select() también permite renombrar las columnas, e incluso reordenar la posición de estas.
select()
Esta función (o verbo) sirve para seleccionar columnas (o variables si el fichero es tidy)
#- vamos a trabajar con los datos del [pkg gapminder](https://github.com/jennybc/gapminder)
df <- gapminderseleccionar variables por nombre
Seleccionamos las variables “year” y “lifeExp” y visualizamos las 4 primeras filas:
#- Se lee como: “Take el df gapminder, then select the variables year and lifeExp, then show the first 4 rows.”
df %>% select(year, lifeExp) %>% head(4)
df %>% select(c(year, lifeExp)) %>% head(4)quitar variables
Seleccionamos todas las variables del df gapminder excepto “year” …
aa <- df %>% select(-cyear)
# excepto year y lifeExp
aa <- df %>% select(-c(year, lifeExp))seleccionar por posición
Seleccionamos las variables del df gapminder siguientes: de la primera a la tercera y también la quinta (mejor seleccionarlas por nombre!!)
aa <- df %>% select(1:3, 5)quitar varibles por posición
Seleccionamos todas las variables del df gapminder excepto las siguientes: de la primera a la tercer y la quinta (mejor seleccionarlas por nombre)
aa <- df %>% select(- c(1:3, 5))La función select() tiene muchas más posibilidades. ya las iremos viendo. PERO si quieres ver un resumen de las posibilidades del pkg dplyr mira su CHEAT SHEET.
renombrando y reordenando columnas con select()
Lo que sí vamos a ver son 2 posibilidades de select() que son muy útiles. Con select() podemos: renombrar y reordenar las columnas:
#- dejamos en aa solamente a las columnas "year" y "pop"
#- además "pop", AHORA irá antes que "year"
aa <- df %>% select(pop, year)#- dejamos en aa solamente a las columnas "year" y "pop" y les cambiamos el nombre
aa <- df %>% select(poblacion = pop, año = year)Imagina que quieres que la última columna pase a ser la primera (manías!!). Podemos hacerlo con select y everything(). everything es una función auxiliar de select:
#- "gdpPercap" que es la última columna pasa a ser la primera
aa <- df %>% select(gdpPercap, everything())
#(!!) otra forma de hacer lo mismo
aa <- df %>% select(ncol(df), everything())
mutate()
Esta función (o verbo) sirve para crear nuevas variables (columnas). Es muy útil en análisis de datos.
#- vamos a trabajar con los datos del [pkg gapminder](https://github.com/jennybc/gapminder)
df <- gapminderCreamos la variable: GDP = pop*gdpperCap
aa <- df %>% mutate(GDP = pop*gdpPercap)summarise()
Esta función (o verbo) sirve para RESUMIR (o “colapsar filas”). Coge un grupo de valores como input y devuelve un solo valor; por ejemplo, haya la media aritmética (o el mínimo, o el máximo …) de un grupo de valores.
#- vamos a trabajar con los datos del [pkg gapminder](https://github.com/jennybc/gapminder)
df <- gapminderObtengamos determinados estadísticos de una variable. Para esto no nos hace falta dplyr pero conviene ir habituándose a su sintaxis.
#- retornará un único valor: la media global de la v. "lifeExp"
aa <- df %>% summarise(mean(lifeExp))
#- retornará un único valor: el número de filas
aa <- df %>% summarise(n()) #- retornará un único valor: el número de filas
#- retornará un único valor: la desviación típica de la v. "lifeExp"
aa <- df %>% summarise(sd(lifeExp))
#- retornará un único valor: el máximo de la variable "pop"
aa <- df %>% summarise(max(pop))
#- retornará 2 valores: la media y sd de la v. "lifeExp"
aa <- df %>% summarise(mean(lifeExp), sd(lifeExp))
#- retornará 2 valores: las medias de "lifeExp" y "gdpPercap"
aa <- df %>% summarise(mean(lifeExp), mean(gdpPercap)) Calculemos determinados estadísticos de todas las variables del df con summarise_all()
#- media de cada una de las 6 variable. las 2 primeras son texto
aa <- df %>% summarise_all(mean)
#- media y sd de las 6 variable. las 2 primeras son texto (***!!!!)
aa <- df %>% summarise_all(funs(mean, sd) ) group_by()
Con esta función ya empezaremos a ver la potencia de dplyr. En análisis de datos muchas operaciones (media etc..) queremos calcularlas para distintos grupos (hombre, mujer …). group_by() permite hacerlo.
group_by()coge un df y lo convierte en un “df agrupado”. En ese nuevo “df agrupado”, las operaciones que hagamos con summarise() se harán por separado para cada uno de los grupos que hayamos definido. Ahora lo vemos.
Si, por ejemplo, agrupamos un df por países, al ejecutar summarise, nos retornara una fila con el resultado para cada país.
Como dice Jenny: Let’s start with simple counting. ¿Cuantas observaciones(rows) tenemos por continente?
#- cogemos df y lo agrupamos por "continent",
#- despues con summarise() calculamos el numero de observaciones o rows
#- retornará un df con una fila por cada continente
aa <- df %>% group_by(continent) %>% summarise(NN = n())
aa# A tibble: 5 x 2
continent NN
<fctr> <int>
1 Africa 624
2 Americas 300
3 Asia 396
4 Europe 360
5 Oceania 24¿Y cuantos países hay en la base de datos? Para este tipo de cosas, se pueden usar funciones de R-base, pero dplyr tiene muchas funciones auxiliares.
#- cogemos df y lo agrupamos por "continent",
#- despues calculamos 2 cosas: el numero de observaciones o rows
#- y el número de países en cada continente (NN_countries)
aa <- df %>% group_by(continent) %>% summarize(NN = n(), NN_countries = n_distinct(country))
aa# A tibble: 5 x 3
continent NN NN_countries
<fctr> <int> <int>
1 Africa 624 52
2 Americas 300 25
3 Asia 396 33
4 Europe 360 30
5 Oceania 24 2Calculemos la esperanza de vida media por continente
#- cogemos df y lo agrupamos por "continent",
#- despues calculamos la media de "lifeExp"
aa <- df %>% group_by(continent) %>% summarize(mean(lifeExp))
aa# A tibble: 5 x 2
continent `mean(lifeExp)`
<fctr> <dbl>
1 Africa 48.86533
2 Americas 64.65874
3 Asia 60.06490
4 Europe 71.90369
5 Oceania 74.32621Guau! Hay que irse a vivir a Oceanía!!
Calculemos la esperanza de vida media por continente en el primer periodo (1952)
#- cogemos df y filtramos para quedarnos con las observaciones de 1952
#- despues lo agrupamos por "continent",
#- despues calculamos la media de "lifeExp"
aa <- df %>% filter(year == "1952") %>% group_by(continent) %>% summarize(mean(lifeExp))
aa# A tibble: 5 x 2
continent `mean(lifeExp)`
<fctr> <dbl>
1 Africa 39.13550
2 Americas 53.27984
3 Asia 46.31439
4 Europe 64.40850
5 Oceania 69.25500Habría sido mejor en lugar de poner filter(year == "1952") haber puesto filter(year == min(year))
Guau! Habría que haber vivido en Oceanía (en 1952)!!
Se pueden calcular varios estadísticos a la vez
#- cogemos df y filtramos (cogemos) las observaciones de 1952 y 2007
#- agrupamos por "continent",
#- despues calculamos la media de "lifeExp" y de "gdpPercap"
aa <- df %>% filter(year %in% c(1952, 2007)) %>% group_by(continent, year) %>% summarize(mean(lifeExp), mean(gdpPercap))
aa# A tibble: 10 x 4
# Groups: continent [?]
continent year `mean(lifeExp)` `mean(gdpPercap)`
<fctr> <int> <dbl> <dbl>
1 Africa 1952 39.13550 1252.572
2 Africa 2007 54.80604 3089.033
3 Americas 1952 53.27984 4079.063
4 Americas 2007 73.60812 11003.032
5 Asia 1952 46.31439 5195.484
6 Asia 2007 70.72848 12473.027
7 Europe 1952 64.40850 5661.057
8 Europe 2007 77.64860 25054.482
9 Oceania 1952 69.25500 10298.086
10 Oceania 2007 80.71950 29810.188Aún mejor con summarise_each y en el formato “recomendado”. Gracias Jenny!!
#- cogemos df y lo agrupamos por "continent", despues calculamos la media de "lifeExp"
aa <- df %>%
filter(year %in% c(1952, 2007)) %>%
group_by(continent, year) %>%
summarise_each(funs(mean, median), lifeExp, gdpPercap)
aa# A tibble: 10 x 6
# Groups: continent [?]
continent year lifeExp_mean gdpPercap_mean lifeExp_median
<fctr> <int> <dbl> <dbl> <dbl>
1 Africa 1952 39.13550 1252.572 38.8330
2 Africa 2007 54.80604 3089.033 52.9265
3 Americas 1952 53.27984 4079.063 54.7450
4 Americas 2007 73.60812 11003.032 72.8990
5 Asia 1952 46.31439 5195.484 44.8690
6 Asia 2007 70.72848 12473.027 72.3960
7 Europe 1952 64.40850 5661.057 65.9000
8 Europe 2007 77.64860 25054.482 78.6085
9 Oceania 1952 69.25500 10298.086 69.2550
10 Oceania 2007 80.71950 29810.188 80.7195
# ... with 1 more variables: gdpPercap_median <dbl>Ya toca una pregunta de verdad!!, ¿en que continente ha aumentado más la esperanza de vida en el periodo 1952-2007?
#- cogemos df y lo agrupamos por "continent", despues calculamos la media de "lifeExp"
aa <- df %>%
filter(year %in% c(1952, 2007)) %>%
group_by(continent, year) %>%
summarize(mean(lifeExp)) %>% ungroup()
aa# A tibble: 10 x 3
continent year `mean(lifeExp)`
<fctr> <int> <dbl>
1 Africa 1952 39.13550
2 Africa 2007 54.80604
3 Americas 1952 53.27984
4 Americas 2007 73.60812
5 Asia 1952 46.31439
6 Asia 2007 70.72848
7 Europe 1952 64.40850
8 Europe 2007 77.64860
9 Oceania 1952 69.25500
10 Oceania 2007 80.71950Casi, pero no!! Sólo hemos conseguido ver la esperanza de vida por continente en 1952 y 2007. Falta restar. En realidad esto ya lo hicimos antes.
Quizás podríamos calcular el máximo, el mínimo y restarlos. No porque supondríamos que lifeExp siempre aumenta. Vamos que el tiempo apremia:
#- se puede hacer de una vez, pero vamos a partir el código en 2 trozos
aa <- df %>% filter(year %in% c(1952, 2007)) %>%
group_by(continent, year) %>%
summarize(media_anyo = mean(lifeExp)) %>% ungroup()
aa1 <- aa %>% group_by(continent) %>%
summarise(min_l = min(media_anyo), max_l = max(media_anyo)) %>%
mutate(dif = max_l-min_l)
aa1# A tibble: 5 x 4
continent min_l max_l dif
<fctr> <dbl> <dbl> <dbl>
1 Africa 39.13550 54.80604 15.67054
2 Americas 53.27984 73.60812 20.32828
3 Asia 46.31439 70.72848 24.41409
4 Europe 64.40850 77.64860 13.24010
5 Oceania 69.25500 80.71950 11.46450Asia son los ganadores. En promedio, en Asía se mejoró la esperanza de vida en 24 años entre 1952 y 2007. Genial, PERO no hemos ponderado por población. ¿Lo hacemos? Precisamente éste es uno de los ejercicios que os dejo para vosotros.
Lo de antes es el proceso que seguí para (intentar) resolver la pregunta. Lo hice muy rápido, así que la solución de Jenny es far-far better que la mía. Está es la solución de Jenny:
#- en realidad este chunk no hace lo que dice el parrafo de arriba que hace (pero casi)!!
aa <- df %>%
group_by(continent) %>%
select(continent, year, lifeExp) %>%
mutate(lifeExp_gain = lifeExp - first(lifeExp)) %>%
filter(year < 1963)
aa# A tibble: 426 x 4
# Groups: continent [5]
continent year lifeExp lifeExp_gain
<fctr> <int> <dbl> <dbl>
1 Asia 1952 28.801 0.000
2 Asia 1957 30.332 1.531
3 Asia 1962 31.997 3.196
4 Europe 1952 55.230 0.000
5 Europe 1957 59.280 4.050
6 Europe 1962 64.820 9.590
7 Africa 1952 43.077 0.000
8 Africa 1957 45.685 2.608
9 Africa 1962 48.303 5.226
10 Africa 1952 30.015 -13.062
# ... with 416 more rowsAdemás Jenny nos advierte que las soluciones a una pregunta no salen a la primera y nos aconseja lo siguiente:
Break the code into pieces, starting at the top, and inspect the intermediate results. That’s certainly how I was able to write such a thing. These commands do not leap fully formed out of anyone’s forehead – they are built up gradually, with lots of errors and refinements along the way. I’m not even sure it’s a great idea to do so much manipulation in one fell swoop. Is the statement above really hard for you to read? If yes, then by all means break it into pieces and make some intermediate objects. Your code should be easy to write and read when you’re done. —- Jenny Bryan always rocks
Otras cuestiones que podemos resolver con dplyr sobre la esperanza de vida:
- ¿Cómo ha evolucionado la esperanza de vida en Spain lustro a lustro?
#- variación de lifeExp en Spain año a año (bueno lustro a lustro)
aa <- df %>%
group_by(country) %>%
select(country, year, lifeExp) %>%
mutate(lifeExp_gain_every_year = lifeExp - lag(lifeExp)) %>%
filter(country == "Spain" )
aa# A tibble: 12 x 4
# Groups: country [1]
country year lifeExp lifeExp_gain_every_year
<fctr> <int> <dbl> <dbl>
1 Spain 1952 64.940 NA
2 Spain 1957 66.660 1.720
3 Spain 1962 69.690 3.030
4 Spain 1967 71.440 1.750
5 Spain 1972 73.060 1.620
6 Spain 1977 74.390 1.330
7 Spain 1982 76.300 1.910
8 Spain 1987 76.900 0.600
9 Spain 1992 77.570 0.670
10 Spain 1997 78.770 1.200
11 Spain 2002 79.780 1.010
12 Spain 2007 80.941 1.161- ¿Y la variación acumulada? Fácil!! Sólo tendríamos que sumar o acumular la variable “lifeExp_gain_every_year” que hemos generado anteriormente, así que sólo habría que añadir una linea a nuestro código:
#- ganancia acumulada
aa <- df %>%
group_by(country) %>%
select(country, year, lifeExp) %>%
mutate(lifeExp_gain_every_year = lifeExp - lag(lifeExp)) %>%
#--- 2 filas nuevas
mutate(lifeExp_gain_every_year2 = if_else(is.na(lifeExp_gain_every_year), 0, lifeExp_gain_every_year)) %>%
mutate(lifeExp_gain_acumulado = cumsum(lifeExp_gain_every_year2)) %>%
filter(country == "Spain")Al final para hacerlo (como había pensado) me han hecho falta 2 lineas, porque la primera observación de “lifeExp_gain_every_year” es un NA y eso hacía que la función cumsum() no funcionase.
- Otra forma de hacer lo mismo sería (se me ha ocurrido después). Además es más fácil
#- ganancia acumulada
aa <- df %>%
group_by(country) %>%
select(country, year, lifeExp) %>%
mutate(lifeExp_gain_acumulada = lifeExp - lifeExp[1]) %>%
filter(country == "Spain")- Obtener, para cada periodo, los (3) países de Asia con MAYOR lifeExp.
aa <- df %>%
filter(continent == "Asia") %>%
select(year, country, lifeExp) %>%
group_by(year) %>%
top_n(-4, lifeExp) %>%
arrange(year) Para obtener los 4 países con MENOR lifeExp sólo tendríamos que sustituir la quinta linea por top_n(-4, lifeExp)
- Obtener, para cada periodo, los países de Asia con mayor y menor lifeExp.
aa <- df %>%
filter(continent == "Asia") %>%
select(year, country, lifeExp) %>%
group_by(year) %>%
filter(min_rank(desc(lifeExp)) < 2 | min_rank(lifeExp) < 2) %>%
arrange(year) Las 2 últimas funciones que hemos usado: top_n() y min_rank() son funciones de dplyr pero son funciones auxiliares.
Podéis ver las funciones auxiliares que tiene dplyr en la segunda página de CHEAT SHEET. también se pueden usar las funciones de R-base o de otros packages. Aquí tenéis algunas posibilidades sacadas de un tutorial de Hadley
Types of summary functions:
• min(x), median(x), max(x), quantile(x, p)
• n(), n_distinct(), sum(x), mean(x)
• sum(x > 10), mean(x > 10)
• sd(x), var(x), iqr(x), mad(x)
Types of window functions:
• Ranking and ordering
• Offsets: lead & lag
• Cumulative aggregates
• Rolling aggregates
Ejemplos:
• Was there a change? x != lag(x)
• Percent change? (x - lag(x)) / x
• Fold-change? x / lag(x)
• Previously false, now true? !lag(x) & x
• If one of the specialised verbs doesn’t do what you need, you can use do()A ver si entendeis este ejemplo
Una función auxiliar que es muy útil al utilizarla junto a mutate: case_when().
aa <- df %>%
group_by(continent, year) %>%
mutate (media_lifeExp = mean(lifeExp)) %>%
mutate (media_gdpPercap = mean(gdpPercap)) %>%
mutate(GOOD_or_BAD = case_when(
lifeExp > mean(lifeExp) & gdpPercap > mean(gdpPercap) ~ "good",
lifeExp < mean(lifeExp) & gdpPercap < mean(gdpPercap) ~ "bad",
lifeExp < mean(lifeExp) | gdpPercap < mean(gdpPercap) ~ "medium"
)) %>%
filter(country == "Spain")5. Combinando (joining) df’s
OK, ya sabemos manejar/filtrar etc… un conjunto de datos, PERO muchas veces lo que hay que hacer es unir o combinar varios conjuntos de datos (Joinings en inglés).
Vamos a aprender como hacerlo usando dplyr. [Aquí] tenéis la vignette de dplyr para “two table verbs”, también podéis ver un vídeo muy ilustrativo [aquí]. También podéis usar el tutorial de Jenny. En nuestra opinión la CHEAT SHEET es muy-muy buena.
(dos) casos sencillos
Dos casos ideales (sencillos de unir): bind_cols() y bind_rows()
Si los 2 dfs tienen exactamente las mismas filas o unidades de análisis ( y ademas en el mismo orden). En este caso, solo habría que juntar en una misma tabla las columnas de df1 y de df2. Esto lo podemos hacer con
bind_cols()(o con cbind() de R-base)Si los 2 dfs tienen exactamente las mismas columnas ( y ademas en el mismo orden). En este caso, se trataría simplemente de juntar todas las observaciones o filas de los 2 df’s. Esto lo podemos hacer con
bind_rows()(o con rbind() de R-base)
Olvidando ya los 2 casos ideales y sencillos
En dplyr hay 3 tipos de funciones(verbos) que se ocupan de diferentes operaciones para unir datasets:
Mutating joins, añade nuevas variables (o columnas) a un dataframe (df1). Estas nuevas columnas vienen de un segundo df2 (hay varias mutating joins, dependiendo del criterio para seleccionar las filas)
Filtering joins, filtra las filas (observaciones) de un dataframe (df1) basándose en sí las filas de df1 coinciden (match) o no con una observación del segundo df2
Set operations, combina las observaciones de los dos datasets (df1 y df2) as if they were set elements.
Todas estas funciones tienen una estructura similar: sus dos primeros argumentos son 2 df’s (en realidad tablas de datos): df1 y df2. El output de la función es siempre una nueva tabla (del mismo tipo que df1).
Mutating joins
Hay 4 tipos de mutating joins. Su sintaxis es idéntica, sólo se diferencian en que las filas que se seleccionan dependen del criterio para hacer el match:
inner_join(df1,df2): Retorna todas las columnas de df1 y también las de df2, PERO solo retorna las filas de df1 que tienen una equivalencia en df2. (la equivalencia se define en función del valor de una variable o variables comunes en df1 y df2)left_join(df1,df2): Retorna todas las columnas de df1 y también las de df2; en cuanto a las filas, retorna TODAS las filas de df1. (Si hubiesen varios matches entre df1 e df2 se retornan todas las combinaciones!!!!)rigth_join(df1,df2): Retorna todas las columnas de df1 y también las de df2; en cuanto a las filas, retorna TODAS las filas de df2. De df2!! (Si hubiesen varios matches entre df1 y df2 se retornan todas las combinaciones!!!!)full_join(df1,df2): Retorna todas las columnas de df1 y también las de df2; en cuanto a las filas, retorna TODAS las filas de df1 y de df2. Osea, retorna TODAS las filas y TODAS las columnas de las 2 tablas. (Donde no hay matches retorna NA’s)
Ejemplos de mutating joins (los ejemplos son de Hadley)
Sean los siguientes 2 dataframes (tibbles):
(df1 <- data_frame(x = c(1, 2), y = 2:1))# A tibble: 2 x 2
x y
<dbl> <int>
1 1 2
2 2 1(df2 <- data_frame(x = c(1, 3), a = 10, b = "a"))# A tibble: 2 x 3
x a b
<dbl> <dbl> <chr>
1 1 10 a
2 3 10 aInner Join
#- inner_join(df1, df2)
#- only includes observations that match in both df1 and df2.
df_inner <- inner_join(df1, df2)
df_inner# A tibble: 1 x 4
x y a b
<dbl> <int> <dbl> <chr>
1 1 2 10 aLeft Join
#- left_join(df1, df2)
#- includes all observations in df1, regardless of whether they match or not.
#- This is the most commonly used join because it ensures that you don’t lose observations from your primary table.
df_left_join <- left_join(df1, df2)
df_left_join# A tibble: 2 x 4
x y a b
<dbl> <int> <dbl> <chr>
1 1 2 10 a
2 2 1 NA <NA>Right Joint
#- right_join(df1, df2)
#- includes all observations in df2.
#- It’s equivalent to left_join(df2, df1), but the columns will be ordered differently.
df_right_join <- right_join(df1, df2)
df_right_join# A tibble: 2 x 4
x y a b
<dbl> <int> <dbl> <chr>
1 1 2 10 a
2 3 NA 10 aFull Joint
#- full_join() includes all observations from df1 and df2
df_full_join <- full_join(df1, df2)
df_full_join# A tibble: 3 x 4
x y a b
<dbl> <int> <dbl> <chr>
1 1 2 10 a
2 2 1 NA <NA>
3 3 NA 10 a2 precisiones sobre las mutating joins
Las (left, right and full) joins se llaman colectivamente como “outer joins”. Cuando una fila no tiene match en una outer join, las nuevas variables que se crean se llenan con NA’s.
Las mutating joins se usan principalmente para añadir columnas, PERO en el proceso pueden generarse nuevas filas: si un match no es único, se añadirán todas las combinaciones posibles (el producto cartesiano) de las matching observations. Veamos un ejemplo con una left_join:
(df1 <- data_frame(x = c(1, 1, 2), y = 1:3))# A tibble: 3 x 2
x y
<dbl> <int>
1 1 1
2 1 2
3 2 3(df2 <- data_frame(x = c(1, 1, 2), z = c("a", "b", "a")))# A tibble: 3 x 2
x z
<dbl> <chr>
1 1 a
2 1 b
3 2 aleft_join que crea nuevas filas
df_left_join <- left_join(df1, df2)
df_left_join# A tibble: 5 x 3
x y z
<dbl> <int> <chr>
1 1 1 a
2 1 1 b
3 1 2 a
4 1 2 b
5 2 3 aImportante ¿Cómo decir a las funciones la columnas (o columnas) que se usarán para hacer los matching?
Podemos(DEBEMOS) elegir las columnas (o variables) que nos servirán para unir los 2 df’s. Estas columnas que se usan para para hallar los matchings y que por tanto nos permiten fusionar los 2 df’s se llaman “keys”.
La opción de las funciones para seleccionar estas columnas “keys” es by =.
si ponemos
left_join(df1, df2, by = "X1")se hará una left_join siendo la variable “X1” la que hará de key. Si las variables key no se llamasen igual en los 2 df’s siempre podemos renombrarlas o hacerleft_join(df1, df2, by = c("X1" = "D4")si ponemos
left_join(df1, df2,by = c("X1", "X2")hará falta que una row de df1 tenga los valores tanto de X1 como de X2 iguales a los de esas mismas variables en df2. Si no se llamasen igual las variables en df1 y df2 haríamosby = c("X1" = "D4", "X2" = "D7")
Filtering joins
Filtering joins son similares a los anteriores (Mutating joins); o sea, hacen machting con las filas de la misma manera, PERO afectan a las filas, NO a las columnas. Hay filtering joins de 2 tipos:
semi_join(df1,df2): retorna las observaciones de df1 que tienen un match en df2. En cuanto a las columnas sólo retorna las columnas de df1anti_join(df1,df2): retorna las observaciones de df1 que NO tienen un match en df2; osea, quita las observaciones con match. En cuanto a las columnas sólo retorna las columnas de df1
La semi_join se diferencia de la inner_join en que la inner_join solo retorna una fila de df1 por cada matching, mientras que la semi_join NUNCA duplica filas de df1
Las filtering joins son útiles para diagnosticar mismatches. Si quieres saber sobre los matches, haz una semi_join() or anti_join(). semi_join() and anti_join() NUNCA duplican filas; solo pueden quitar filas.
(df1 <- data_frame(V1 = c(1, 1, 3, 4), V2 = 1:4))# A tibble: 4 x 2
V1 V2
<dbl> <int>
1 1 1
2 1 2
3 3 3
4 4 4(df2 <- data_frame(V1 = c(1, 1, 2), V3 = c("a", "b", "a")))# A tibble: 3 x 2
V1 V3
<dbl> <chr>
1 1 a
2 1 b
3 2 asemi_join
df_semi_join <- semi_join(df1, df2, by = "V1")
df_semi_join# A tibble: 2 x 2
V1 V2
<dbl> <int>
1 1 1
2 1 2anti_join
df_anti_join <- anti_join(df1, df2, by = "V1")
df_anti_join# A tibble: 2 x 2
V1 V2
<dbl> <int>
1 3 3
2 4 4compara la semi_join con la inner_join
df_inner <- inner_join(df1, df2, by = "V1")
df_inner# A tibble: 4 x 3
V1 V2 V3
<dbl> <int> <chr>
1 1 1 a
2 1 1 b
3 1 2 a
4 1 2 bLa inner_join
- añade variables de df2 a df1 (en este caso V3)
- sólo retiene las rows de df1 que tienen un match en df2 (en este caso las 2 primeras filas de df1)
- PERO en este ejemplo ADEMÁS duplica rows. la razón es que hay matching duplicados, hay 2 unos en df1 y otros 2 unos en df2 (con distintos valores de V3) (así que salen 4 rows)
Importante ¿Cómo decir a las funciones la columnas o columnas que se usarán para hacer los matching?
Al igual que con las mutating joins, en las filtering joins también podemos(DEBEMOS) elegir las columnas (o variables) que nos servirán para unir los 2 df’s. Estas columnas que se usan para para hallar los matchings y que por tanto que permiten fusionar los 2 df’s se llaman “keys”.
La opción de las funciones para seleccionar estas columnas “keys” es by =.
si ponemos
semi_join(df1, df2, by = "X1")se hará una semi_join siendo la variable “X1” la que hará de key. Si las variables key no se llamasen igual en los 2 df’s siempre podemos renombrarlas o hacersemi_join(df1, df2, by = c("X1" = "D4")si ponemos
semi_join(df1, df2,by = c("X1", "X2")hará falta que una row de df1 tenga los valores tanto de X1 como de X2 iguales a los de esas mismas variables en df2. Si no se llamasen igual las variables en df1 y df2 haríamosby = c("X1" = "D4", "X2" = "D7")
Set operations
Este tipo de joins es más estricta: hace falta que los 2 df’s tengan las mismas variables (o columnas). Los 2 df’s pueden tener observaciones(filas) diferentes, PERO es necesario que tengan las mismas variables (o columnas).
Como los 2 df’s tienen las mismas columnas, entonces es como si se tratasen los dfs como conjuntos:
intersect(df1, df2): devuelve un df con las observaciones comunes en df1 y df2union(df1, df2): devuelve la unión; o sea, las observaciones de df1 y de df2 (quitando las posibles filas duplicadas)union_all(df1, df2): devuelve la unión (sin quitar los duplicados)setdiff(df1, df2): devuelve las filas en df1 que no están en df2
setequal(df1,df2: retorna TRUE si df y df2 tienen exactamente las mismas filas (da igual el orden en el que estén las filas)
(df1 <- data_frame(x = 1:2, y = c(1L, 1L)))# A tibble: 2 x 2
x y
<int> <int>
1 1 1
2 2 1(df2 <- data_frame(x = 1:2, y = 1:2))# A tibble: 2 x 2
x y
<int> <int>
1 1 1
2 2 2intersección
intersect(df1, df2)# A tibble: 1 x 2
x y
<int> <int>
1 1 1unión
union(df1, df2)# A tibble: 3 x 2
x y
<int> <int>
1 1 1
2 2 1
3 2 2setdiff
setdiff(df1, df2)# A tibble: 1 x 2
x y
<int> <int>
1 2 1setdiff(df2, df1)# A tibble: 1 x 2
x y
<int> <int>
1 2 2setqual
Sirve para determinar si 2 df’s son iguales (da igual el orden en que estén las filas)
setequal(df1, df2)FALSE: Rows in x but not y: 2. Rows in y but not x: 2. setequal(union(df1, df2), union(df2, df1))TRUE
Esperando a GODOT/ggplot2
Bueno, pues hemos visto “TODO” sobre manipulación de datos. El próximo tutorial va de visualización: hacia ggplot2
Aquí un pequeño avance:
library("ggplot2")
my_plot <- ggplot(gapminder, aes(x = continent, y = lifeExp)) +
geom_boxplot(outlier.colour = "hotpink") +
geom_jitter(position = position_jitter(width = 0.1, height = 0), alpha = 1/4) +
labs(title = "Experanza de vida (por continente)",
subtitle = "Datos de gapminder. 1952-2007(observaciones cada 5 años)",
caption = "Source: Gapminder. Jenny Bryan rocks in gapminder vignette!!",
x = "Continente", y = "Esperanza de Vida (lifeExp)") 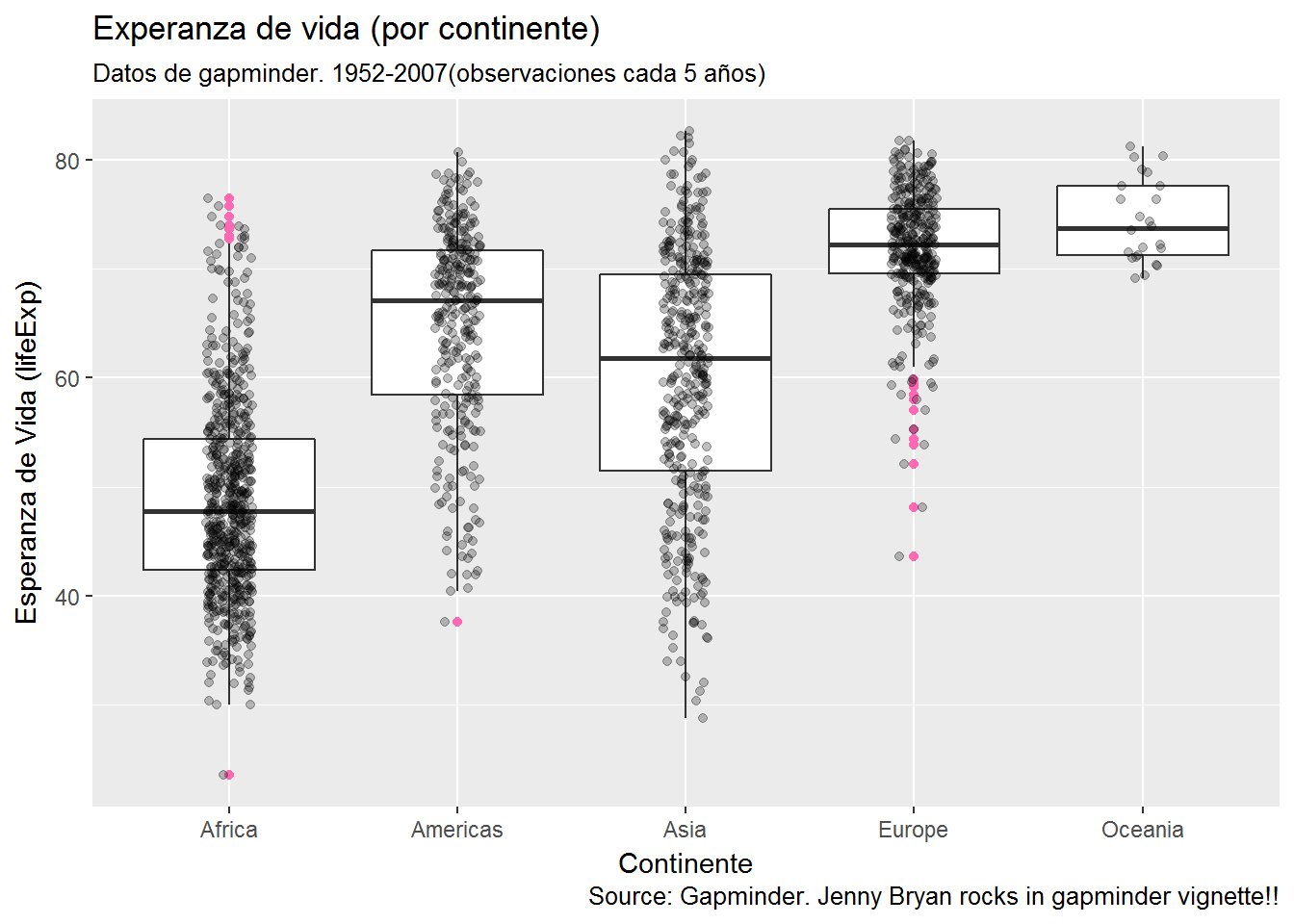
gapminder2 <- gapminder %>% mutate(year = as.factor(year))
library("ggplot2")
my_plot <- ggplot(gapminder2, aes(x = year, y = lifeExp)) +
geom_boxplot(outlier.colour = "hotpink") +
geom_jitter(position = position_jitter(width = 0.1, height = 0), alpha = 1/4) +
labs(title = "Experanza de vida (por año)",
subtitle = "Datos de gapminder. 1952-2007(observaciones cada 5 años)",
caption = "Source: Gapminder. Jenny Bryan rocks in gapminder vignette!!",
x = "Periodo", y = "Esperanza de Vida (lifeExp)") 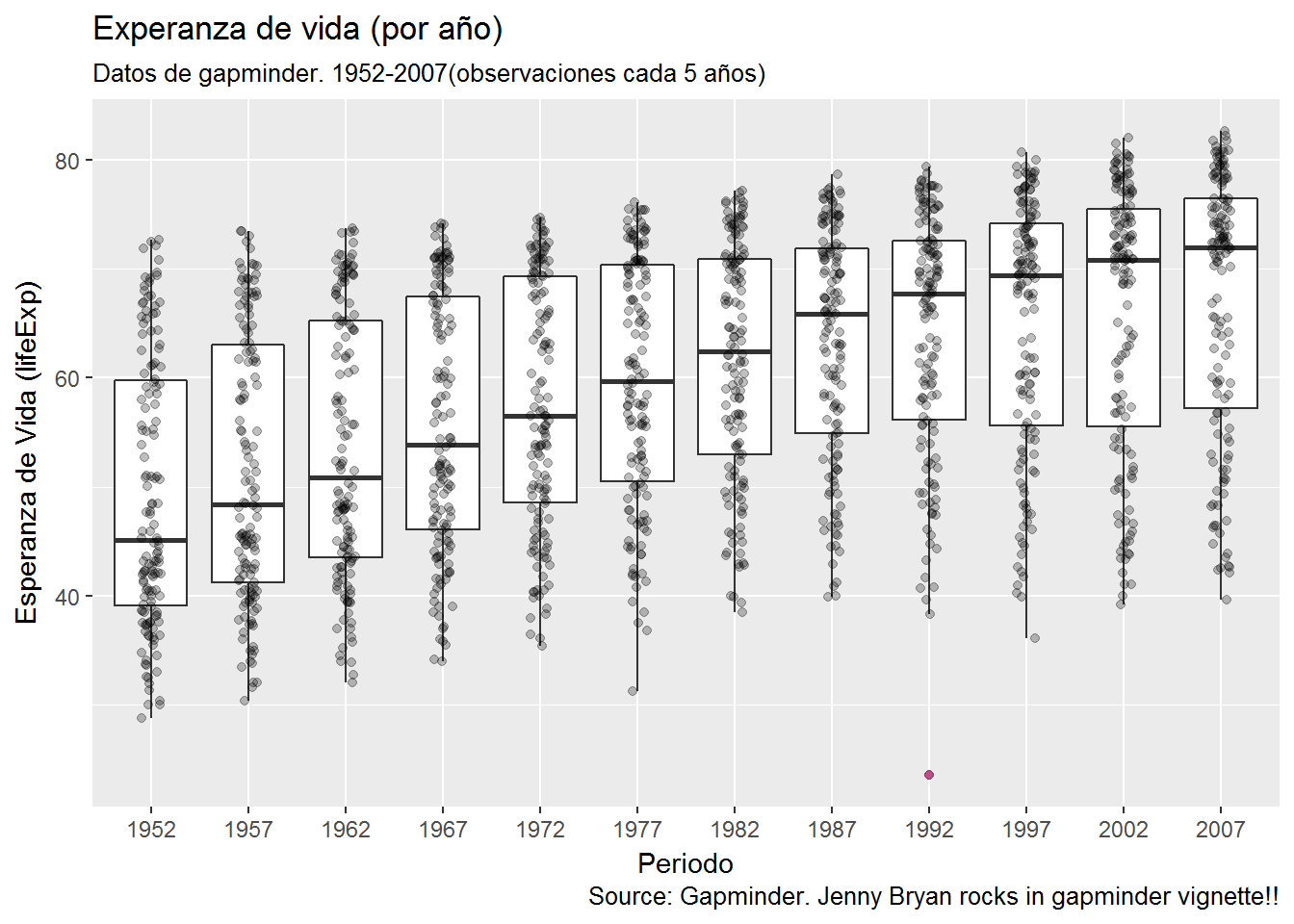
library("ggplot2")
my_plot <- ggplot(gapminder, aes(x = gdpPercap, y = lifeExp, colour = continent)) +
geom_jitter(position = position_jitter(width = 0.1, height = 0), alpha = 1/4) +
labs(title = "Experanza de vida vs. GDP (per cápita)",
subtitle = "Datos de gapminder. 1952-2007(observaciones cada 5 años)",
caption = "Source: Gapminder. Jenny Bryan rocks in gapminder vignette!!",
x = "GDP (per cápita)", y = "Esperanza de Vida (lifeExp)") 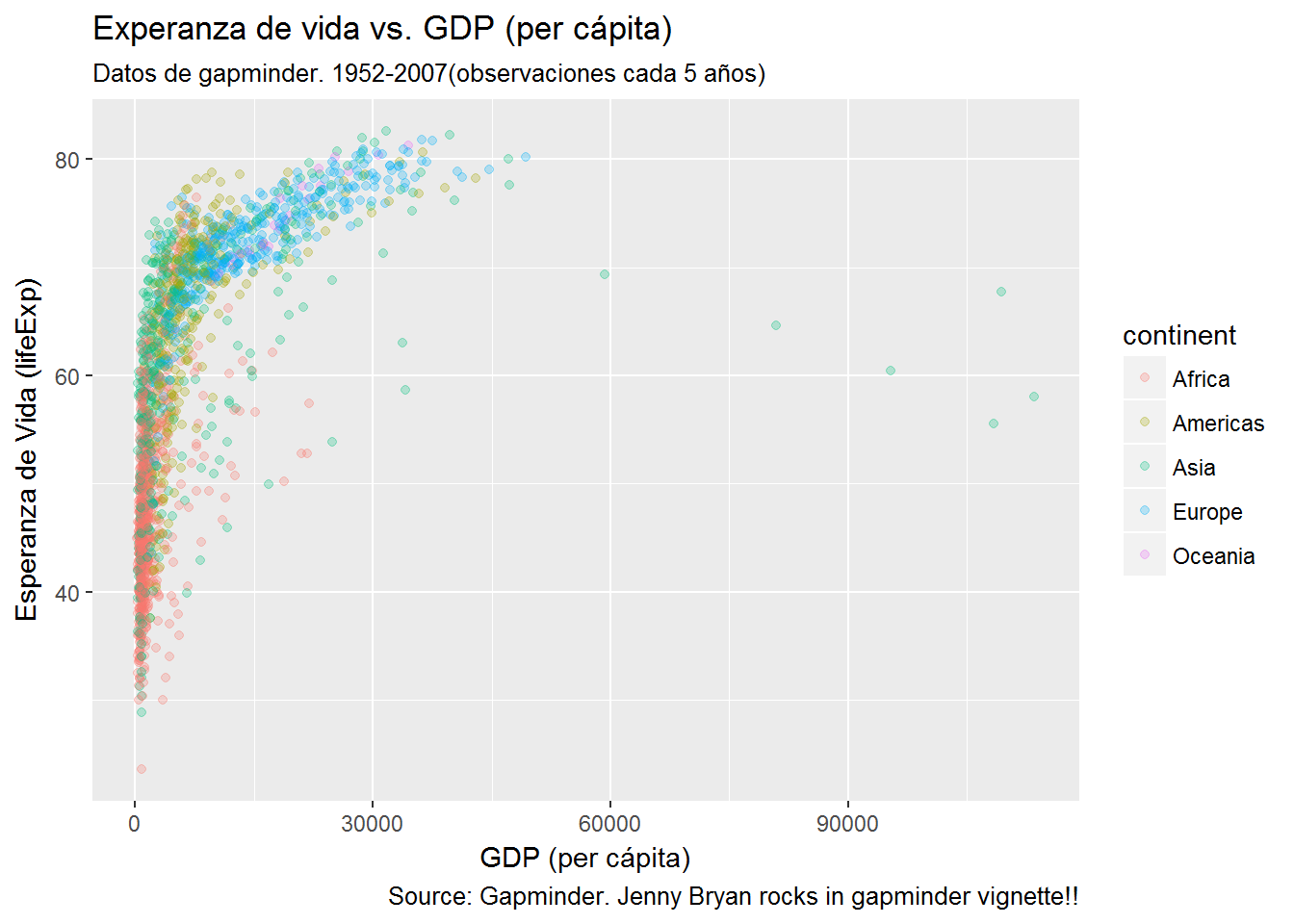
Tidyverse vs. Base R
Todo lo que se puede hacer con dplyr, tidyr etc. ,también se puede hacer con Base-R pero de una manera mucho menos intuitiva.
El siguiente ejemplo esta sacado de este post. Son dos trozos de código que hacen exactamente lo mismo:
Con el tidyverse:
library(dplyr)
mtcars %>%
group_by(cyl, am) %>%
select(mpg, cyl, wt, am) %>%
summarise(avgmpg = mean(mpg), avgwt = mean(wt)) %>%
filter(avgmpg > 20)Con la sintaxis de base R:
filter(
summarise(
select(
group_by(mtcars, cyl, am),
mpg, cyl, wt, am),
avgmpg = mean(mpg), avgwt = mean(wt)),
avgmpg > 20)O puesto en horizontal
filter(summarise(select(group_by(mtcars, cyl, am), mpg, cyl, wt, am),avgmpg = mean(mpg), avgwt = mean(wt)), avgmpg > 20)Otro ejemplo de comparación tidyverse versus Base-R:
df %>% filter(country == "Spain") %>% select(year, lifeExp)
df[df$country == "Spain", c("year", "lifeExp")]
Bibliografía
Introducción a dplyr. Jenny Bryan nos cuenta (en sus FANTASTICOS materiales para el curso STAT545) los rudimentos de dplyr. Buena parte de este tutorial se basa en el suyo.
dplyr functions for a single dataset. Otro material de Jenny del curso STAT545 sobre dplyr
dplyr CHEAT SHEET. FANTASTIQUÉRRIMA!!! Impresionante!!
Cápitulo de R4DS sobre “dplyr”. De Hadley. Fantástico libro y fantástico capítulo sobre manejo de datos (dplyr).
A new data processing workflow for R: dplyr, magrittr, tidyr, ggplot2. Post de un nuevo convencido de las bondades del tidyverse. Un ejemplo sencillo pero ilustrativo.
Wide & Long Data Post que explica los beneficios de trabajar con datos en formato long (tidy).
La biblia del tidy data. Vignette de tidyr package escrita por Hadley Wickham que explica con MUCHO detalle que son los tidy data.