.svg)





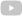

La Universitat i el CSIC analitzen una nova tècnica de seqüenciació gènica que ajuda a desxifrar malalties com el càncer

Un flowcell o cambra de flux, element de seqüenciació transcriptòmica de lectures llargues mitjançant nanoporus, avaluat per l’equip del I2SysBio (CSIC - Universitat de València). Crèdits: Pablo Atienza.
Científiques de l’Institut de Biologia Integrativa de Sistemes (I2SysBio), centre mixt del Consell Superior d’Investigacions Científiques (CSIC) i la Universitat de València (UV), han publicat una revisió de la tecnologia de seqüenciació transcriptòmica de lectura llarga, que permet analitzar amb més precisió que els mètodes tradicionals les molècules d’ARN presents a totes les cèl·lules i que contenen informació genètica essencial per a la vida. Aquesta tècnica resulta fonamental per a comprendre millor l’envelliment, les malalties neurodegeneratives o el càncer. L’article ha sigut publicat en la revista Nature Reviews Genetics.
La transcriptòmica engloba l’estudi de totes les molècules d’ARN (àcid ribonucleic) presents en una cèl·lula o teixit. Aquestes són molècules intermèdies entre l’ADN i les proteïnes. Si bé l’ADN conté la informació genètica, l’ARN és el que permet la síntesi de proteïnes i que la informació siga compresa per les cèl·lules. Permet entendre quins gens estan actius en un moment concret i quin és el seu grau d’activació en els diferents organismes, cosa que és clau per a comprendre l’origen i desenvolupament de moltes malalties humanes. També es pot fer servir per a estudiar les plantes resistents a la sequera o a la calor, per a examinar organismes menys estudiats com els virus i bacteris, i fins i tot va ser usada pel personal científic del CSIC que va visitar recentment l’Antàrtida per a estudiar la grip aviària.
Segons explica Ana Conesa, professora d’investigació del CSIC en l’I2SysBio, “amb aquesta investigació hem proveït la comunitat científica d’una guia essencial per a comprendre la tecnologia de seqüenciació transcriptòmica de lectura llarga, tant els fluxos de treball experimentals com les anàlisis computacionals. Presentem una visió integral de les tècniques de seqüenciació d’ARN de lectura llarga i abracem des del disseny experimental fins al processament de dades, la identificació de les diferents molècules d’ARN i les anàlisis posteriors”.
Fins fa pocs anys, la transcriptòmica s’estudiava utilitzant la seqüenciació amb lectures curtes, i això implicava trencar les molècules d’ARN en fragments petits d’entre 50 i 300 nucleòtids, unitats bàsiques dels àcids nucleics ADN i ARN (les famoses lletres ATCG). Això implicava que per a esbrinar quina era la molècula original d’ARN, s’havia de reconstruir el puzle de fragments d’ARN, cosa que ocasionava gran quantitat d’errors, en haver seqüencies molt similars entre ARNs.
Com explica la també investigadora del CSIC en el I2SysBio Carolina Monzó, “la seqüenciació amb lectures llargues llig fragments de milers de nucleòtids, i això permet seqüenciar molècules completes i estudiar l’ARN sense necessitat de fer puzles. A més, en seqüenciar molècules d’ARN una en una, les lectures llargues possibiliten identificar les seues modificacions petites, i això es denomina epitranscriptòmica, que són fonamentals per a la seua funció. Això no era possible amb les tecnologies anteriors”.
Aplicacions científiques
En obtenir seqüències de molècules completes d’ARN, aquesta tecnologia facilita tot tipus d’aplicacions i estudis en què és important conèixer de manera precisa la composició i estructura de l’ARN. Per exemple: l’expressió d’isoformes (diferents formes d’ARN provinent del mateix gen), el descobriment de noves formes d’ARN, l’anotació de gens en genomes d’espècies poc estudiades o l’estudi de l’expressió diferencial d’ARN entre el produït pel cromosoma heretat del pare i el cromosoma heretat de la mare, entre d’altres.
Segons detalla Monzó, “aquests estudis tenen interès perquè podrien contribuir a l’avanç en la comprensió de malalties neuropsiquiàtriques i neurodegeneratives. En aquests moments se sap que hi ha diferències en l’isoforma expressada en diverses regions del cervell i que estan associades amb múltiples complicacions neuronals”.
En l’article, també ha participat Tianyuan Liu, estudiant predoctoral del Grup de Genòmica de l’Expressió Gènica en el I2SysBio (CSIC – Universitat de València), que actualment té un contracte predoctoral en el marc de la beca Marie Skłodowska-Curie Actions Doctoral Network LongTREC de la Unió Europea.
Referencia: Monzó, C., Liu, T. i Conesa, A. Transcriptomics in the era of long-read sequencing. Nat Rev Genet (2025). DOI: https://doi.org/10.1038/s41576-025-00828-z
Categories: Investigació a la UV , Institut de Biologia Integrativa de Sistemes (I2SYSBIO) , Producció científica , Finançament recerca , Recerca, innovació i transferència , Internacionalització recerca
Other News