4.1 Modelos
Una de las razones por la que interesan las técnicas descriptivas es su capacidad para representar los datos originales. Hemos visto que lo hacen cuantificando características que describen los grupos (tendencia central, variabilidad, asimetría y apuntamiento). Si la representación es fiel, los valores de los estadísticos descriptivos nos da mucha información de los datos, pero no toda la información. Por ejemplo, la Media representa la tendencia central, pero no informa de la variabilidad de los datos.
La representación de los datos se puede mejorar si se modeliza las distribuciones de las variables, es decir, si las sustituimos por un modelo. Un modelo es una representación de las características fundamentales de un objeto. Modelos que interesan especialmente en Psicología son los que representan relaciones entre variables o los que representan distribuciones de datos.
Las principales razones por las que los modelos son especialmente útiles son:
a) Facilitan el tratamiento del objeto que representan (relaciones entre variables, distribuciones, etc.).
b) Son una forma mucho compacta/eficiente de transmitir información.
Modelos de distribuciones
Consideremos los siguientes datos:
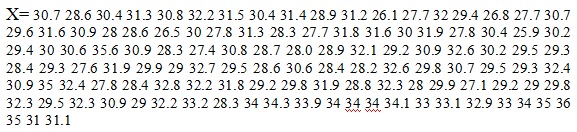
Podemos caracterizar los datos con procedimientos que representan sus características más importantes. Así, podemos sustituirlos por gráficas como el Histograma:

La gráfica nos da una representación intuitiva, pero no nos informa de manera precisa: Hemos perdido información. Otra posibilidad consiste en obtener estadísticos descriptivos, por ejemplo:
![]()
De esta manera tenemos información de la tendencia central, la variabilidad, pero hemos perdido casi toda la información individual.
Los modelos de distribuciones representan de forma compacta y precisa (dentro de ciertos límites) las distribuciones de las variables. Por ejemplo, el modelo
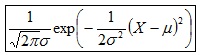
donde m y s simbolizan la Media y la Desviación Típica, representa distribuciones de datos cuya forma es:
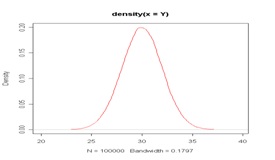
Si superponemos la curva anterior al Histograma que representa los datos del ejemplo podemos apreciar que la curva se acerca bastante bien a la distribución de los datos:
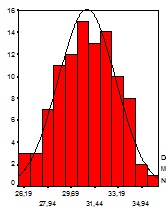
La conclusión es que el modelo representa (aproximadamente) la distribución original y por tanto nos da información más completa de los datos que si solo obtenemos estadísticos descriptivos.