install.packages("spanishoddata")12 Movilidad
12.1 Introducción
La movilidad, tanto urbana como rural, es un componente esencial en la vida diaria de cualquier sociedad moderna. En España y otros países desarrollados, el movimiento de personas y mercancías es clave para el desarrollo económico y social, también para abordar desafíos ambientales y de sostenibilidad. Con la creciente urbanización y la transformación de los hábitos de trabajo y ocio, especialmente en un mundo post-pandemia que ha alterado significativamente los patrones de desplazamiento y fomentado el teletrabajo, disponer de herramientas avanzadas que permitan comprender, gestionar y anticipar los movimientos de la población se ha vuelto más necesario que nunca.
Históricamente, el análisis de la movilidad en España se ha basado en estudios como las encuestas Movilia de 2000/2001 y 2006/2007 (Cascajo y Jordá, 2010). Aunque estos métodos fueron innovadores en su momento, su dependencia de datos estáticos y la limitada escala de las encuestas los hacen insuficientes para capturar la complejidad y la dinámica de la movilidad contemporánea. Estos enfoques carecen de la precisión, escalabilidad y capacidad de actualización en tiempo real que los retos actuales requieren.
La proliferación de datos geolocalizados de dispositivos móviles ha revolucionado el análisis de la movilidad, ofreciendo oportunidades sin precedentes para la recopilación de datos precisos, económicos y dinámicos (Pérez y Aybar, 2024). Estudios previos han demostrado cómo los rastros de telefonía móvil pueden modelar la movilidad intraurbana con una granularidad imposible de alcanzar mediante encuestas tradicionales (Calabrese et al., 2013). Además, la aplicación de Big Data permite a los responsables de la planificación urbana tomar decisiones en tiempo real y adaptarse a entornos urbanos en constante cambio. Por ejemplo, Cao et al. (2021) emplearon datos de telefonía móvil a gran escala para construir redes de movilidad urbana, revelando patrones de desplazamiento y diferencias estructurales en los motivos de viaje de los ciudadanos. Este tipo de análisis proporciona información muy útil para el diseño de políticas de transporte más eficientes y sostenibles.
La pandemia de COVID-19 acentuó aún más la necesidad de contar con datos de movilidad en tiempo real. Willberg et al. (2021) utilizaron datos de telefonía móvil para rastrear cambios en la movilidad entre áreas urbanas y rurales en Finlandia durante la crisis sanitaria, demostrando el potencial de estos datos para mejorar la preparación ante emergencias y la gestión de recursos. De manera similar, en España, el Ministerio de Transportes y Movilidad Sostenible (MITMS) ha impulsado el uso de Big Data en el estudio de la movilidad, proporcionando datos abiertos para comprender y gestionar los desplazamientos a nivel nacional.
El avance de la Inteligencia Artificial (IA) ha llevado aún más lejos el análisis de la movilidad. Las técnicas de Machine Learning permiten mejorar la calidad del servicio en el transporte público, comprender el comportamiento de los viajeros y optimizar la asignación de recursos (Jevinger et al., 2024). Estas soluciones basadas en IA son especialmente eficaces para superar la rigidez de los estudios tradicionales, ya que permiten adaptar la gestión del transporte a variaciones en la demanda, reducir la congestión en tiempo real y prever el uso futuro de infraestructuras urbanas.
Además, la transformación digital en la gestión urbana ha dado lugar a conceptos innovadores como los gemelos digitales urbanos. Xu et al. (2024) exploraron la integración de técnicas de Generative Artificial Intelligence (GenAI) en la creación de escenarios urbanos automatizados, facilitando la planificación inteligente de ciudades y la simulación de soluciones de transporte. Estas herramientas representan un avance sustantivo en la planificación urbana integral, combinando movilidad, sostenibilidad y tecnología.
El impulso por modernizar el análisis de la movilidad no solo responde a necesidades de eficiencia, sino también a los compromisos de sostenibilidad. Tsavachidis y Petit (2022) subrayaron la importancia de la descarbonización del transporte urbano como un pilar clave en la lucha contra el cambio climático en Europa. En esta línea, los sistemas de transporte inteligente integran el llamado Internet de las Cosas (IoT), IA y Big Data para optimizar la movilidad urbana, mejorar la gestión del tráfico y prevenir accidentes (Oladimeji et al., 2023). Sin embargo, estos avances también presentan desafíos como la privacidad de los datos, la interoperabilidad entre sistemas y la escalabilidad de las soluciones, cuestiones que requieren investigación y regulación continua.
En este contexto, el estudio de la movilidad mediante Big Data se ha convertido en una herramienta fundamental para la toma de decisiones en planificación urbana y transporte. En esta sesión, exploraremos los fundamentos del análisis de matrices origen-destino, la aplicación de herramientas en R para su procesamiento y la explotación de datos abiertos proporcionados por el MITMS. A través de ejemplos prácticos, veremos cómo estos enfoques pueden contribuir a mejorar la movilidad en España y a enfrentar los desafíos del futuro.
12.2 Origin-destination data
El análisis de matrices origen-destino (OD) es una metodología fundamental en los estudios de movilidad. Estas matrices representan la cantidad de desplazamientos que se realizan entre diferentes zonas geográficas en un período de tiempo determinado. Su uso ayuda a comprender los patrones de desplazamiento, prever la demanda de transporte y evaluar el impacto (y la necesidad) de nuevas infraestructuras.
En el ámbito de la computación estadística y la ciencia de datos, existen diversas herramientas para procesar y visualizar estos datos. Uno de los paquetes más relevantes en R es stplanr (Lovelace y Ellison, 2018), diseñado para la planificación del transporte y el análisis de datos de movilidad. Este paquete permite trabajar con matrices OD, calcular rutas óptimas y representar gráficamente los flujos de transporte. A partir de stplanr, se desarrolló el paquete od(Lovelace y Morgan, 2024), que se especializa en la manipulación y análisis de matrices origen-destino, facilitando su procesamiento y exploración. Estos paquetes permiten a los investigadores y analistas transformar grandes volúmenes de datos de movilidad en información visualmente comprensible, lo que resulta esencial para la toma de decisiones en transporte y urbanismo.
12.3 Open Data Movilidad
El Estudio de Movilidad con Big Data del MITMS combina múltiples fuentes de datos y técnicas avanzadas de análisis para generar indicadores detallados sobre la movilidad en España. A diferencia de estudios tradicionales, este enfoque proporciona información continua y precisa, con alta resolución espacial y temporal.
12.3.1 Fuentes de datos
Tal y como se indica aquí, el proyecto ODM (Origin-Destination Mobility) integra diversas fuentes de datos:
- Registros anonimizados de telefonía móvil: Fuente principal que permite inferir patrones de movilidad en tiempo real mediante eventos de conexión a antenas.
- Datos de uso del suelo: Información sobre distribución poblacional, centros de trabajo, zonas comerciales y puntos de interés (SIOSE).
- Datos demográficos: Segmentación por edad, género e ingresos (INE).
- Red de transporte: Infraestructura vial y transporte público (OpenStreetMap, ADIF, AENA).
- Demanda de transporte: Datos de encuestas y estadísticas de movilidad para validación (INE, FRONTUR).
12.3.2 Procesamiento y análisis de datos
Para garantizar la calidad y privacidad de los datos, el estudio sigue estos pasos:
- Anonimización: Se aplican técnicas de pseudonimización para proteger la privacidad de los usuarios (cumplimiento RGPD).
- Preprocesamiento: Limpieza y organización de los datos para su análisis.
- Identificación de actividades y viajes: Algoritmos detectan lugares habituales y clasifican viajes según su propósito (trabajo, ocio, compras).
- Determinación del modo de transporte: Técnicas de map matching (Alkhazraji et al., 2024) asignan trayectos a la red de transporte y determinan si fueron en coche, tren, bus, etc.
- Expansión muestral: Se extrapolan datos de una muestra de 13 millones de líneas móviles al total de la población mediante factores de expansión.
- Ajuste y validación: Comparación con encuestas y estadísticas oficiales para garantizar precisión.
12.3.3 Productos y acceso a los datos
El estudio genera productos clave, accesibles en la plataforma Open Data Movilidad:
- Zonificación: Áreas geográficas de análisis (distritos, municipios, grandes áreas urbanas).
- Estudios básicos: Datos diarios de movilidad (pernoctaciones, desplazamientos por persona, matrices origen-destino).
- Estudios completos: Datos mensuales con segmentación por modo de transporte y análisis temporal detallado.
12.4 Spanish Origin-Destination Data
![]()
spanishoddata Kotov et al. (2026) es una librería de R desarrollada por Egor Kotov y Robin Lovelace que facilita la descarga y el procesamiento de los datos publicados por el Ministerio de Transportes y Movilidad Sostenible (MITMS, 2024). Este paquete permite acceder de forma sencilla a matrices origen-destino y otros conjuntos de datos de movilidad, facilitando su integración en análisis y visualizaciones dentro del ecosistema R.
library(spanishoddata)12.4.1 Obtener datos
Antes de obtener datos, es interesante indicar dónde se deberían descargar, y convertir, los datos:
spod_set_data_dir(tempdir())Si solo necesitamos los datos de un día, agregados por municipio, podemos usar la función spod_quick_get_od(). Esta función tiene 5 argumentos:
date: un objeto de tipo character o Date que especifica la fecha de los datos que deseamos obtener. Si es de tipo character, debería estar en formato “YYYY-MM-DD” o “YYYYMMDD”.
min_trips: un valor numérico que especifica el mínimo de viajes para cada origen-destino (por defecto, el valor es 100). Si deseamos obtener todos los datos, el valor debería ser 0.
distances: un vector de tipo character que especifica la distancia del viaje. Los valores son: “500m-2km”, “2-10km”, “10-50km” y “50+km”.
id_origin: un vector de tipo character que especifica los municipios de origen deseados.
id_destination: un vector de tipo character que especifica los municipios de destino deseados.
dt1 <- spod_quick_get_od(
date = "2024-12-15",
min_trips = 1000,
distances = "10-50km"
)summary(dt1) date id_origin id_destination
Min. :2024-12-15 Length:2797 Length:2797
1st Qu.:2024-12-15 Class :character Class :character
Median :2024-12-15 Mode :character Mode :character
Mean :2024-12-15
3rd Qu.:2024-12-15
Max. :2024-12-15
n_trips trips_total_length_km
Min. : 1000 Min. : 10693
1st Qu.: 1230 1st Qu.: 20298
Median : 1656 Median : 30755
Mean : 2831 Mean : 50860
3rd Qu.: 2589 3rd Qu.: 49938
Max. :253886 Max. :3157019 dt1Si queremos obtener los datos para un determinado municipio (o grupo de municipios), debemos conocer los códigos (variable id) disponibles. Para ello, usaremos la función spod_get_zones():
municipios <- spod_get_zones(zones = "municipios", ver = 2)class(municipios)[1] "sf" "tbl_df" "tbl" "data.frame"Como vemos, el objeto resultante es de clase sf, que podemos graficar:
#ggplot() + geom_sf(data=municipios, fill="transparent") + theme_classic()
ggplot() +
geom_sf(data = municipios %>% filter(stringr::str_sub(id, 1, 2) == "28"),
aes(fill = population), color = "white", size = 0.2) +
scale_fill_viridis_c(option = "plasma", trans = "log", name = "# habitantes",
labels = scales::label_comma(big.mark = ".", decimal.mark = ",")) +
labs(title = "Número de habitantes por municipio",
subtitle = "Comunidad de Madrid") +
theme_minimal() +
theme(panel.grid = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
plot.title.position = "plot",
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5),
legend.position = c(0.1,0.8),
legend.title = element_blank()) +
ggspatial::annotation_scale(location = "bl", width_hint = 0.5, text_cex = 0.8) +
ggspatial::annotation_north_arrow(location = "tr", which_north = "true",
style = ggspatial::north_arrow_fancy_orienteering())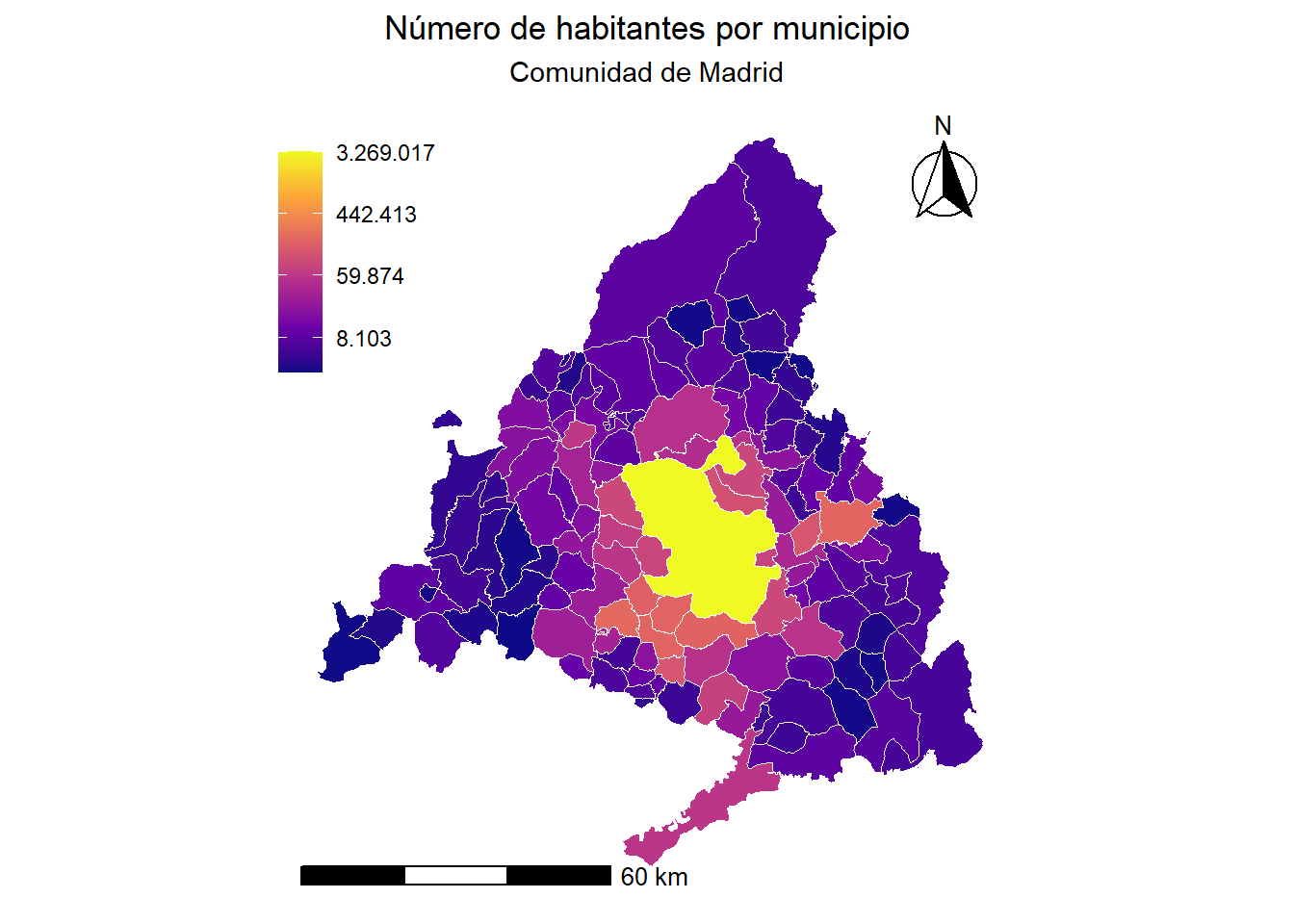
Ahora obtenemos los datos referentes a viajes de largo recorrido (más de 50 km) con destino Valencia (ciudad):
dt2 <- spod_quick_get_od(
date = "2024-12-15",
min_trips = 0,
distances = "50+km",
id_destination = "46250"
)
TipPregunta
¿De qué municipios partieron más viajeros?
De forma análoga, podemos obtener los distritos…
distritos <- spod_get_zones(zones = "distritos", ver = 2)… y las grandes areas urbanas (GAUs):
gaus <- spod_get_zones(zones = "grandes_areas_urbanas", ver = 2)
PrecauciónEjercicio
¿Qué 5 destinos (municipios), de fuera de la Comunidad Valenciana, fueron los más elegidos por los residentes en la ciudad de Valencia el Día de la Constitución de 2024?
Otra forma de obtener los datos es mediante la función spod_get(). Esta función permite obtener los datos completos de cada día, permitiendo ulteriores análisis mucho más completos que los anteriores. No obstante, puesto que implica la descarga de una mayor cantidad de datos (aproximadamente 200 MB por día), el proceso se ralentiza. Veamos un ejemplo:
fechas <- c(start = "2024-12-06", end = "2024-12-08")
dt4_dist <- spod_get(type = "od", zones = "dist", dates = fechas, quiet = T)Deleting source `C:/Users/scorp/AppData/Local/Temp/RtmpKaREj2/clean_data/v2/zones/distritos_mitma.gpkg' failed
Writing layer `distritos_mitma' to data source
`C:/Users/scorp/AppData/Local/Temp/RtmpKaREj2/clean_data/v2/zones/distritos_mitma.gpkg' using driver `GPKG'
Writing 3909 features with 9 fields and geometry type Unknown (any).dt4_muni <- spod_get(type = "od", zones = "muni", quiet = T,
dates = c("20241206","20241207","20241208"))Deleting source `C:/Users/scorp/AppData/Local/Temp/RtmpKaREj2/clean_data/v2/zones/municipios_mitma.gpkg' failed
Writing layer `municipios_mitma' to data source
`C:/Users/scorp/AppData/Local/Temp/RtmpKaREj2/clean_data/v2/zones/municipios_mitma.gpkg' using driver `GPKG'
Writing 2735 features with 9 fields and geometry type Unknown (any).colnames(dt4_dist) [1] "date" "hour"
[3] "id_origin" "id_destination"
[5] "distance" "activity_origin"
[7] "activity_destination" "study_possible_origin"
[9] "study_possible_destination" "residence_province_ine_code"
[11] "residence_province_name" "income"
[13] "age" "sex"
[15] "n_trips" "trips_total_length_km"
[17] "year" "month"
[19] "day" class(dt4_dist)[1] "tbl_duckdb_connection" "tbl_dbi"
[3] "tbl_sql" "tbl_lazy"
[5] "tbl" Los objetos resultantes (dt4_dist y dt4_muni), son de la clase tbl_duckdb_connection, los cuales serán tratados como como data.frames o tibbles. La principal ventaja de este formato es que los datos no se cargan en la memoria RAM del equipo, sino que están almacenados en el disco y se van obteniendo a demanda. Los objetos dt4_dist y dt4_muni se pueden manipular con las funciones habituales del paquete dplyr, tales como select(), filter(), mutate(), group_by(), summarise(), etc. A estas funciones es necesario agregar la función collect(), que permitirá cargar los resultados en memoria en un objeto de tipo data.frame / tibble. Veamos un par de ejemplos:
df4_muni_1 <- dt4_muni %>%
filter(str_sub(id_origin,1,2) == "46") %>%
arrange(hour,date,id_origin,id_destination) %>%
collect()glimpse(df4_muni_1)Rows: 2,393,566
Columns: 19
$ date <date> 2024-12-06, 2024-12-06, 2024-…
$ hour <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ id_origin <fct> 46001_AM, 46001_AM, 46001_AM, …
$ id_destination <fct> 44210_AM, 44216, 46001_AM, 460…
$ distance <fct> 10-50, 10-50, 10-50, 10-50, 10…
$ activity_origin <fct> infrequent_activity, home, fre…
$ activity_destination <fct> infrequent_activity, infrequen…
$ study_possible_origin <lgl> FALSE, FALSE, FALSE, FALSE, FA…
$ study_possible_destination <lgl> FALSE, FALSE, FALSE, FALSE, FA…
$ residence_province_ine_code <fct> 08, 46, 46, 46, 46, 46, 46, 46…
$ residence_province_name <fct> "Barcelona", "Valencia/Valènci…
$ income <fct> >15, 10-15, 10-15, 10-15, 10-1…
$ age <fct> 65-100, NA, NA, NA, NA, NA, NA…
$ sex <fct> male, NA, NA, NA, NA, NA, NA, …
$ n_trips <dbl> 2.372, 1.688, 9.037, 2.313, 3.…
$ trips_total_length_km <dbl> 39.457, 63.173, 113.452, 24.45…
$ year <int> 2024, 2024, 2024, 2024, 2024, …
$ month <int> 12, 12, 12, 12, 12, 12, 12, 12…
$ day <int> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, …viajes_diarios <- dt4_muni %>%
group_by(date, age, sex, income) %>%
summarise(
n_viajes = sum(n_trips, na.rm = TRUE),
.groups = "drop") %>%
group_by(age, sex, income) %>%
summarise(
promedio_viajes = mean(n_viajes, na.rm = TRUE),
.groups = "drop") %>%
collect()glimpse(viajes_diarios)Rows: 39
Columns: 4
$ age <fct> NA, NA, NA, 0-25, 0-25, 0-25, 0-25, 0-25, …
$ sex <fct> NA, NA, NA, NA, NA, NA, female, female, fe…
$ income <fct> <10, 10-15, >15, <10, 10-15, >15, <10, 10-…
$ promedio_viajes <dbl> 5516250.5, 19850764.4, 4249034.6, 514257.5…En el segundo ejemplo, dado que los datos están en intervalos horarios dentro de cada día, primero sumamos el número de viajes por día según grupos de edad, sexo e ingresos. Luego agrupamos nuevamente los datos, eliminando la variable del día, y calculamos el promedio de viajes por día según grupos de edad, sexo e ingresos.
Es probable que los datos completos de los 3 días nunca se hayan cargado en memoria al mismo tiempo. En su lugar, la memoria disponible del equipo se ha utilizado hasta su límite máximo para realizar los cálculos, sin exceder nunca el límite de memoria disponible. Si se realizara la misma operación con 100 días, el proceso sería análogo. Esto se realiza de manera transparente para el usuario con la ayuda de del paquete duckdb (Mühleisen y Raasveldt, 2024).
NotaInfo
Mientras se utilice un objeto de conexión de tabla (tbl_duckdb_connection) creado con la función spod_get(), es mucho más rápido filtrar las fechas utilizando las variables year, month y day, en lugar de la variable date (fecha completa).
12.4.2 Pernoctaciones
El conjunto de datos de pernoctaciones proporciona información sobre la cantidad de personas que han pasado la noche en una determinada zona geográfica durante un día específico. Este dataset permite analizar los patrones de permanencia de la población, identificando zonas con alta concentración de residentes temporales, siendo un recurso muy útil para estudios de movilidad, planificación urbana y gestión turística.
Este dataset contiene las siguientes variables:
date: Día específico para el que se registran los datos, en formato yyyymmdd.
id_residence: Código identificador de la zona de residencia de las personas registradas.
id_overnight_stay: Código identificador de la zona donde las personas han pasado la noche.
n_persons: Cantidad de personas que han pernoctado en la zona especificada.
Veamos un ejemplo:
overnight <- spanishoddata::spod_get(
type = "os",
zones = "dist",
dates = "2024-06-01"
)class(overnight)[1] "tbl_duckdb_connection" "tbl_dbi"
[3] "tbl_sql" "tbl_lazy"
[5] "tbl" colnames(overnight)[1] "date" "id_residence" "id_overnight_stay"
[4] "n_persons" "year" "month"
[7] "day" dt.pernoct <- overnight %>%
select(date,id_residence,id_overnight_stay,n_persons) %>%
collect()glimpse(dt.pernoct)Rows: 625,342
Columns: 4
$ date <date> 2024-06-01, 2024-06-01, 2024-06-01, 202…
$ id_residence <fct> 01001, 01001, 01001, 01001, 01001, 01001…
$ id_overnight_stay <fct> 01001, 01017_AM, 01028_AM, 01047_AM, 010…
$ n_persons <dbl> 2665.890, 2.300, 2.481, 5.469, 3.119, 27…colnames(dt.pernoct) <- c("fecha","zona_residencia","zona_pernoctacion","personas")
dt.pernoct <- dt.pernoct %>%
mutate(provincia_residencia = substr(zona_residencia, 1, 2),
provincia_pernoctacion = substr(zona_pernoctacion, 1, 2))summary(dt.pernoct) fecha zona_residencia zona_pernoctacion
Min. :2024-06-01 2807908: 1762 2807901: 1997
1st Qu.:2024-06-01 2807901: 1658 4109101: 1673
Median :2024-06-01 2807907: 1639 43905 : 1458
Mean :2024-06-01 2807906: 1559 0801902: 1288
3rd Qu.:2024-06-01 2807910: 1517 2807907: 1287
Max. :2024-06-01 2807915: 1515 0801910: 1236
(Other):615692 (Other):616403
personas provincia_residencia provincia_pernoctacion
Min. :0.000e+00 Length:625342 Length:625342
1st Qu.:2.649e+00 Class :character Class :character
Median :3.864e+00 Mode :character Mode :character
Mean :7.682e+01
3rd Qu.:7.290e+00
Max. :2.350e+05
data <- dt.pernoct %>%
mutate(personas = ifelse(personas < 1, NA, personas))# Función para mostrar solo la primera aparición del código
deduplicate_labels <- function(labels) {
duplicated <- duplicated(labels)
labels[duplicated] <- ""
return(labels)
}p1 <- ggplot() +
geom_tile(data = dt.pernoct,
aes(x = as.factor(zona_residencia),
y = as.factor(zona_pernoctacion),
fill = personas)) +
coord_flip() +
labs(
x="Zona de Residencia",
y="Zona de Pernoctación"
) +
scale_x_discrete(
labels=deduplicate_labels(substr(levels(as.factor(dt.pernoct$zona_residencia)), 1, 2))
) +
scale_y_discrete(
labels=deduplicate_labels(substr(levels(as.factor(dt.pernoct$zona_pernoctacion)), 1, 2))
) +
theme_minimal() +
theme(
panel.grid = element_blank(),
panel.background = element_rect(fill = "white", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.title = element_blank(),
axis.title = element_text(size = 14),
axis.text = element_text(size=7),
legend.position = "none"
)
12.4.3 Viajes por persona
El conjunto de datos de viajes por persona proporciona información sobre la cantidad de desplazamientos realizados por individuos en una zona específica durante un día determinado. Este dataset es fundamental para el análisis de la movilidad individual y permite identificar patrones de desplazamiento según factores demográficos como la edad y el género. Su aplicación es clave en estudios de transporte, planificación urbana y gestión de infraestructuras de movilidad.
Este dataset contiene las siguientes variables:
date: Día específico para el que se registran los datos, en formato yyyymmdd.
id: Código identificador de la zona donde se encuentra la persona.
age: Grupo de edad de los viajeros, con valores posibles: “0-25”, “25-45”, “45-65” y “65-100”.
sex: Sexo de los viajeros, con valores posibles: “male” (hombre) o “female” (mujer).
n_trips: Cantidad de desplazamientos realizados por persona, con valores posibles: “0” (sin viajes), “1” (un viaje), “2” (dos viajes) y “2+” (más de dos viajes).
n_persons: Cantidad de individuos en la zona con el mismo perfil de viajes.
year: Componente “año” de la variable “date”.
month: Componente “mes” de la variable “date”.
day: Componente “día” de la variable “date”.
Veamos un ejemplo:
trips <- spanishoddata::spod_get(
type = "nt",
zones = "muni",
dates = c(start = "2024-06-03", end = "2024-06-09")
)colnames(trips)[1] "date" "id" "age" "sex" "n_trips"
[6] "n_persons" "year" "month" "day" viajes <- trips %>% select(-date) %>% collect()glimpse(viajes)Rows: 555,325
Columns: 8
$ id <fct> 01001, 01001, 01001, 01001, 01001, 01001, 01001,…
$ age <fct> 0-25, 0-25, 0-25, 0-25, 0-25, 0-25, 25-45, 25-45…
$ sex <fct> male, male, male, female, female, female, male, …
$ n_trips <fct> 0, 2, 2+, 0, 2, 2+, 0, 2, 2+, 0, 1, 2, 2+, 0, 1,…
$ n_persons <dbl> 140.253, 113.525, 200.594, 121.219, 78.667, 210.…
$ year <int> 2024, 2024, 2024, 2024, 2024, 2024, 2024, 2024, …
$ month <int> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, …
$ day <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, …12.4.4 Matriz Origen-Destino
La matriz origen-destino detalla los flujos de viaje entre diferentes regiones (distritos, municipios o grandes areas urbanas), proporcionando una visión granular de los patrones de movilidad. Este dataset permite identificar las principales rutas de desplazamiento, la distribución de la movilidad según actividades y el impacto de diferentes factores sociodemográficos en los patrones de viaje.
Este dataset contiene las siguientes variables:
date: Día específico para el que se registran los datos, en formato yyyymmdd.
time_slot: Franja horaria en la que se origina el viaje, segmentada en 24 intervalos de una hora, con valores entre “00” y “23” (por ejemplo, “00” indica viajes iniciados entre las 00:00:00 y 00:59:59 horas).
id_origin: Código identificador de la zona donde comienza el viaje.
id_destination: Código identificador de la zona donde finaliza el viaje.
distance: Distancia en kilómetros entre la zona de origen y la de destino, con valores posibles: “0.5”, “2-10”, “10-50” y “>50”.
activity_origin: Tipo de actividad realizada en la zona de origen del viaje, con valores posibles: “home”, “work_or_study”, “frequent_activity” o “infrequent_activity”.
activity_destination: Tipo de actividad realizada en la zona de destino, con las mismas categorías que la actividad en origen.
study_possible_origin: Indica si la actividad en el origen puede estar relacionada con la educación. Valores posibles: “yes” o “no”.
study_possible_destination: Indica si la actividad en el destino puede estar relacionada con la educación. Valores posibles: “yes” o “no”.
residence_province_ine_code: Código del INE correspondiente a la provincia de residencia del viajero (valores entre “01” y “52”).
residence_province_name: Nombre de la provincia de residencia del viajero.
income: Nivel de ingresos del viajero en miles de euros, con valores posibles: “<10” (menos de 10 mil euros), “10-15” (entre 10 y 15 mil euros) y “>15” (más de 15 mil euros).
age: Grupo de edad de los viajeros, con valores posibles: “0-25”, “25-45”, “45-65” y “65-100”.
sex: Sexo de los viajeros, con valores posibles: “male” (hombre) o “female” (mujer).
n_trips: Cantidad total de desplazamientos registrados entre las zonas de origen y destino.
trips_total_length_km: Producto del número de viajes (variable “n_trips”) y la distancia entre origen y destino (variable “distance”), proporcionando una métrica del volumen de desplazamientos en función de la distancia recorrida.
year: Componente “año” de la variable “date”.
month: Componente “mes” de la variable “date”.
day: Componente “día” de la variable “date”.
En esta ocasión, obtenemos datos para la semana del 3 al 9 de junio de 2024.
od <- spanishoddata::spod_get(
type = "od",
zones = "dist",
dates = paste0("2024060",3:9)
)Are you sure you would like to continue with this download? (yes/no)
TipPregunta
¿Por qué nos aparece esta pregunta?
colnames(od) [1] "date" "hour"
[3] "id_origin" "id_destination"
[5] "distance" "activity_origin"
[7] "activity_destination" "study_possible_origin"
[9] "study_possible_destination" "residence_province_ine_code"
[11] "residence_province_name" "income"
[13] "age" "sex"
[15] "n_trips" "trips_total_length_km"
[17] "year" "month"
[19] "day" Observamos los movimientos internos en la Comunidad de Madrid, por días y franjas horarias:
od_madrid <- od %>%
select(date,hour,id_origin,id_destination,income,n_trips) %>%
collect()glimpse(od_madrid)Rows: 150,109,363
Columns: 6
$ date <date> 2024-06-03, 2024-06-03, 2024-06-03, 2024-0…
$ hour <int> 2, 5, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12,…
$ id_origin <fct> 3304406, 3304406, 3304406, 3304406, 3304406…
$ id_destination <fct> 3304405, 3304405, 3304405, 3304405, 3304405…
$ income <fct> 10-15, 10-15, 10-15, 10-15, 10-15, 10-15, 1…
$ n_trips <dbl> 2.966, 3.554, 3.554, 6.414, 10.662, 9.621, …od_madrid_filt <- od_madrid %>%
filter(str_sub(id_origin,1,2) == "28" & str_sub(id_destination,1,2) == "28") %>%
group_by(date,hour) %>%
summarise(sum_viajes = sum(n_trips, na.rm = T), .groups = "drop")
data_heatmap <- od_madrid_filt %>%
mutate(
date = format(date, "%a %d %b"), # Formato "Mon 03 Jun"
date = factor(date, levels = rev(unique(date))))p2 <- ggplot(data_heatmap, aes(x = hour, y = date, fill = sum_viajes)) +
geom_tile(color = "white", linewidth = 0.75) +
scale_fill_distiller(
palette = "YlGnBu", #RColorBrewer::display.brewer.all()
direction = 1,
name = "Total viajes",
limits = c(0, 1500000),
breaks = seq(0, 1500000, 250000),
labels = scales::comma_format(big.mark = ".", decimal.mark = ",")
) +
scale_x_continuous(
breaks = 0:23,
labels = sprintf("%02d", 0:23)
) +
theme_minimal() +
theme(
legend.position = "bottom",
legend.title = element_text(size = 12, face = "bold", color = "#333333", hjust = 0.5),
legend.title.position = "bottom",
legend.text = element_text(size = 10, color = "#444444"),
legend.key.height = grid::unit(0.4, "cm"),
legend.key.width = grid::unit(2.8, "cm"),
legend.ticks = element_blank(),
legend.margin = margin(t=10, r=0, b=0, l=0),
panel.grid = element_blank(),
axis.text.x = element_text(angle = 0, hjust = 0.5, size = 10),
axis.text.y = element_text(hjust = 1, size = 10, margin = margin(r = -20)),
axis.title = element_blank(),
plot.title = element_blank(),
plot.subtitle = element_blank(),
plot.margin = margin(t = -30, r = -15, b = -30, l = 0)
) +
coord_equal()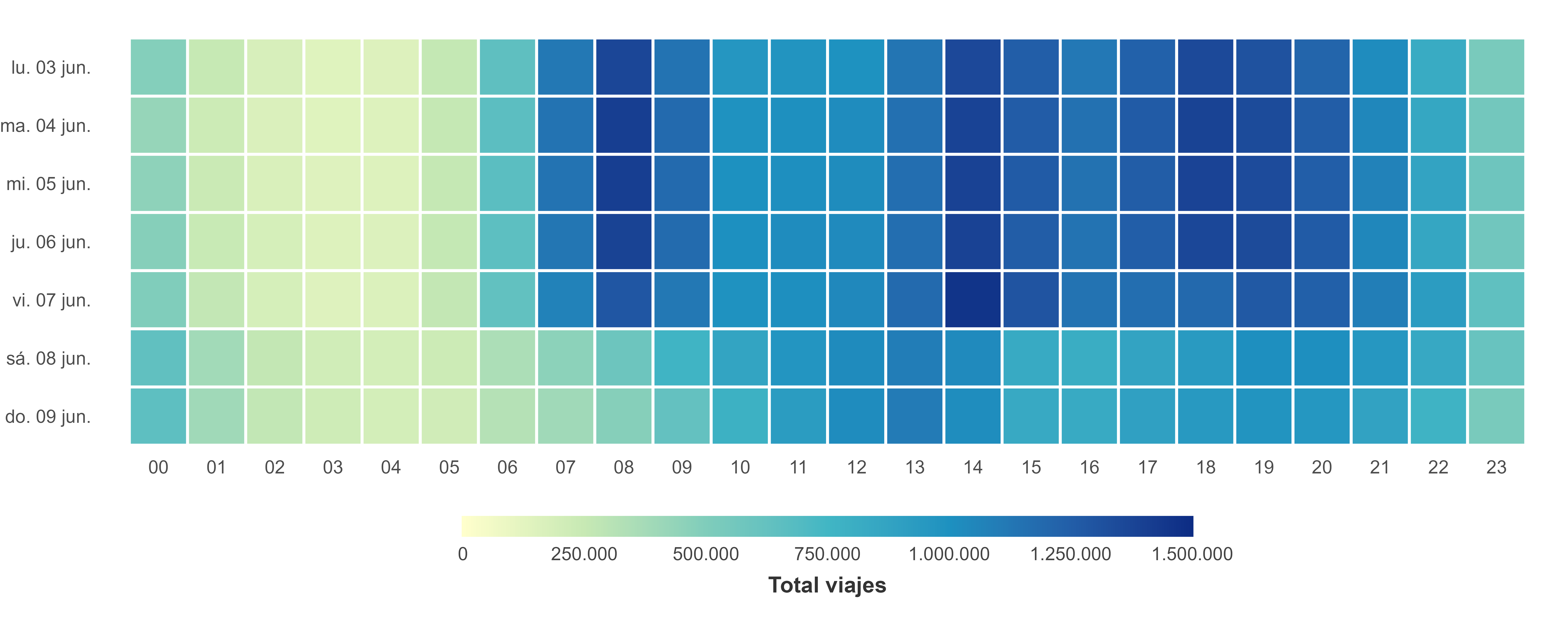
TipPregunta
¿Qué interpretación podemos realizar de esta figura?
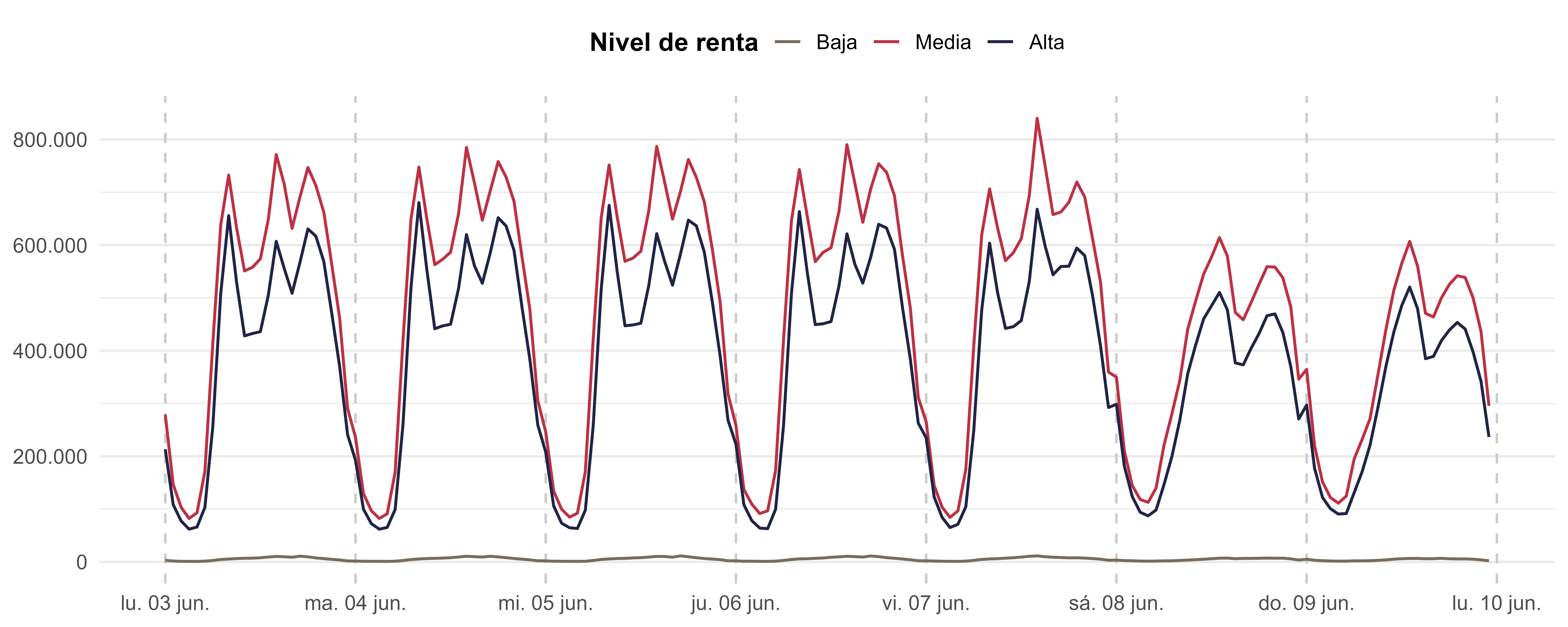
Ahora nos fijamos en los viajeros con origen en Madrid y con cualquier destino, y observamos posibles diferencias según su nivel de renta:
od_MAD <- od_madrid %>%
filter(str_sub(id_origin,1,2) == "28") %>%
group_by(date,hour,income) %>%
summarise(sum_viajes = sum(n_trips, na.rm = T), .groups = "drop") %>%
mutate(datetime = lubridate::ymd_h(paste(date,hour)),
income = forcats::fct_recode(income, "Baja" = "<10", "Media" = "10-15", "Alta" = ">15"))
custom_colors <- c("Alta" = "#202547", "Media" = "#BE3144", "Baja" = "#7A6C5D")p3 <- od_MAD %>%
ggplot(aes(x = datetime, y = sum_viajes, color = income)) +
geom_line(linewidth = 0.75) +
scale_y_continuous(labels = scales::comma_format(big.mark = ".", decimal.mark = ",")) +
scale_x_datetime(
date_labels = "%a %d %b",
date_breaks = "1 day"
) +
scale_color_manual(values = custom_colors) +
labs(color = "Nivel de renta") +
theme_minimal(base_size = 14) +
theme(
panel.grid.major.x = element_line(color = "grey80", linetype = "dashed"),
panel.grid.minor.x = element_blank(),
plot.title = element_blank(),
plot.subtitle = element_blank(),
axis.title = element_blank(),
axis.text.x = element_text(hjust = 0.5),
legend.position = "top",
legend.title = element_text(size = 14, face = "bold")
)
Ahora nos fijamos en los viajeros con origen en la Comunidad de Madrid y con destino en Valencia (provincia), y observamos posibles diferencias según su nivel de renta:
od_MAD_VAL <- od_madrid %>%
filter(str_sub(id_origin,1,2) == "28" & str_sub(id_destination,1,2) == "46") %>%
group_by(date,hour,income) %>%
summarise(sum_viajes = sum(n_trips, na.rm = T), .groups = "drop") %>%
mutate(datetime = lubridate::ymd_h(paste(date,hour)),
income = forcats::fct_recode(income, "Baja" = "<10", "Media" = "10-15", "Alta" = ">15"))p4 <- od_MAD_VAL %>%
ggplot(aes(x = datetime, y = sum_viajes, color = income)) +
geom_line(linewidth = 0.75) +
scale_y_continuous(labels = scales::comma_format(big.mark = ".", decimal.mark = ",")) +
scale_x_datetime(
date_labels = "%a %d %b",
date_breaks = "1 day"
) +
scale_color_manual(values = custom_colors) +
labs(color = "Nivel de renta") +
theme_minimal(base_size = 14) +
theme(
panel.grid.major.x = element_line(color = "grey80", linetype = "dashed"),
panel.grid.minor.x = element_blank(),
plot.title = element_blank(),
plot.subtitle = element_blank(),
axis.title = element_blank(),
axis.text.x = element_text(hjust = 0.5),
legend.position = "top",
legend.title = element_text(size = 14, face = "bold")
)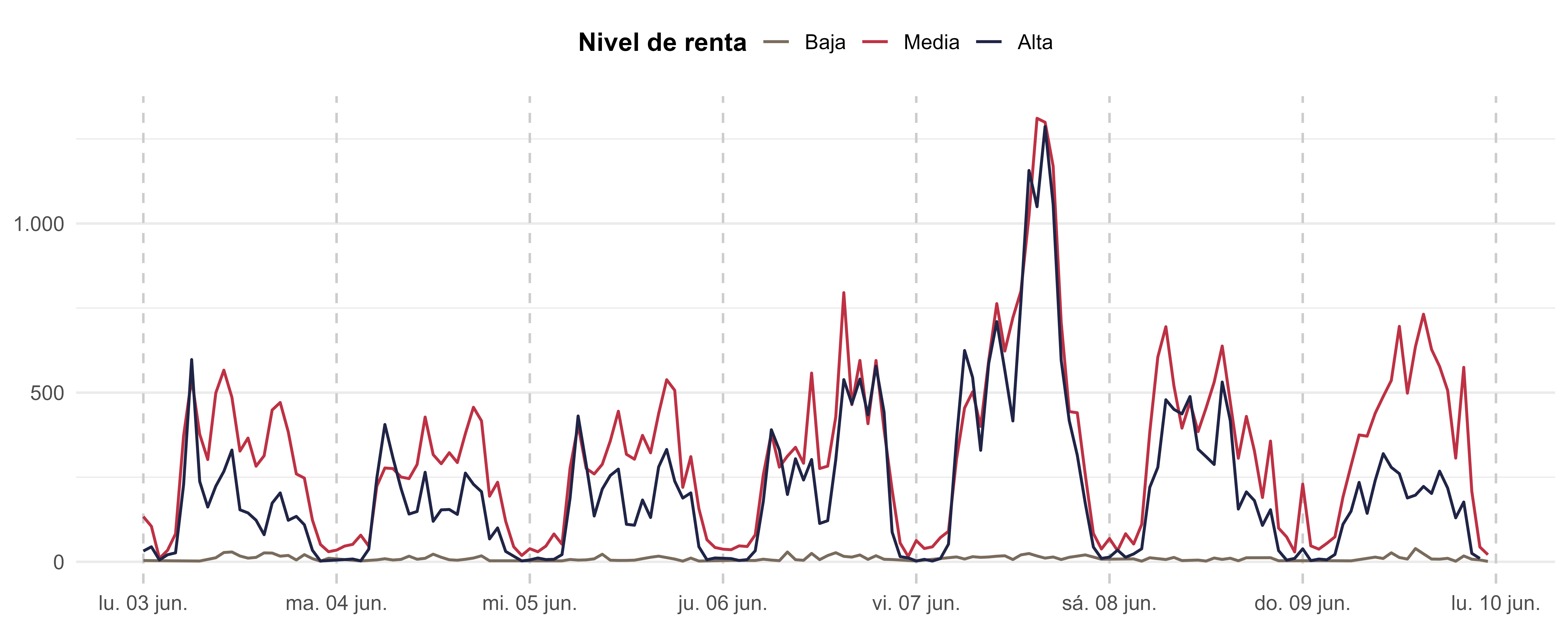
TipPregunta
¿Qué conclusiones podemos extraer tras observar la figura? ¿Qué otras comparativas se podrían hacer?