Hasta el momento, todos los ejemplos y modelos vistos en clase eran univariantes (por ejemplo, nivel de Zinc en localizaciones cercanas al río Mosa), es decir, había una única variable de respuesta \(Z\) para cada localización \(s\).
Habitualmente realizamos un análisis o estudio sobre una única variable. No obstante, también podemos estudiar el comportamiento de diferentes variables un una misma localización (por ejemplo, niveles de distintos metales pesados). En este caso, incorporaremos a nuestro análisis otras variables, obteniendo los denominados datos espaciales multivariantes.
En multitud de estudios se han analizado espacialmente diferentes elementos contaminantes, como el monóxido de carbono \(CO\), el oxido nítrico \(NO\) y/o el dióxido de de nitrógeno \(NO_2\), entre otros. Es muy interesante poder predecir los niveles de estos tres (u otros) contaminantes en lugares no muestreados, incorporando información conjunta de las tres variables en todos los lugares (y momentos).
Otro escenario es el inmobiliario. Por ejemplo, en Gelfand et al. (2004) se analizaron los precios de venta y de alquiler de los inmuebles comerciales en Chicago, Dallas y San Diego (Estados Unidos), con el fin de proporcionar información para la financiación inmobiliaria y el análisis de la inversión inmobiliaria.
5.2 Análisis multivariante de datos espaciales
Una vez presentadas las técnicas de análisis espacial univariante, el siguiente paso será analizar la existencia de relaciones entre variables, lo que puede realizarse desde un punto de vista bidimensional o multidimiensional.
Existen diferentes técnicas para el Análisis Exploratorio de Datos Espaciales (AEDE) multivariante, como el diagrama de dispersión, el gráfico de coordenadas paralelas o los mapas condicionales, entre otros. Los veremos a continuación.
5.2.1 Diagrama de dispersión
El diagrama de dispersión o nube de puntos proporciona una buena descripción de la relación o dependencia existente entre dos variables \(X-Y\). Se trata de una representación gráfica de las observaciones de las variables \((X,Y)\) para definir su comportamiento conjunto. La forma que presenta esta nube de puntos refleja el grado de correlación entre las dos variables, que puede ser nula (si los puntos forman un círculo), lineal (si los puntos representan una elipse) o no lineal (si los puntos toman cualquier otra forma.
La función más sencilla y útil en la mayoría de los casos, por su simplicidad, es la recta. En este caso, la dependencia entre las variables es medida a través del coeficiente de correlación lineal de Pearson\(r_{xy}\). El diagrama de dispersión permite determinar la significatividad de este coeficiente, en cuanto que la relación entre ambas variables sea o no lineal, y existan ciertos puntos atípicos que le resten representatividad.
El coeficiente de correlación lineal de Pearson es un índice estadístico que mide la relación lineal entre dos variables continuas\((X,Y)\). Se calcula como el cociente entre la covarianza \(S_{xy}\) y el producto de sus desviaciones típicas: \(r_{xy}= S_{xy}/S_xS_y\). A diferencia de la covarianza, la correlación de Pearson es independiente de la escala de medida de las variables. El valor del coeficiente varía en el intervalo \([-1,1]\). Cuando el coeficiente de correlación es igual a sus valores extremos, diremos que existe una relación funcional directa o indirecta (respectivamente) entre las variables \(X\) e \(Y\). Si \(r_{xy}=0\), no existirá relación lineal entre las variables \(X\) e \(Y\) (aunque pudiera producirse una relación no lineal).
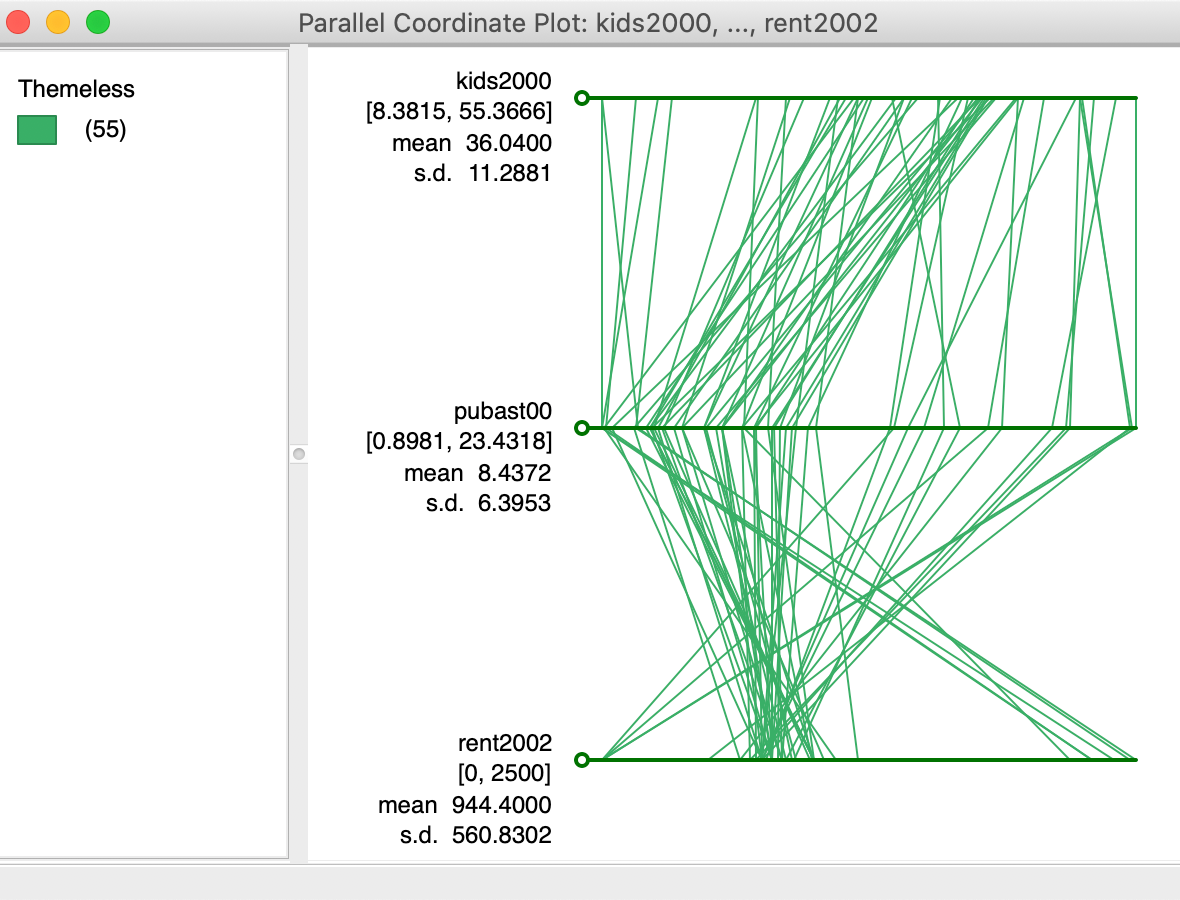
5.2.2 Gráfico de coordenadas paralelas
Se trata de una opción alternativa al diagrama de dispersión, que permite un análisis multivariante superior a dos variables. Los valores de las variables se representan en ejes horizontales paralelos, desde los inferiores (a la izquierda del eje) a los superiores (a la derecha). De este modo, las observaciones se representan en forma de múltiples segmentos que van uniendo su posición en cada eje según los valores de las variables que adoptan.
El gráfico de coordenadas paralelas sería una especie de diagrama de dispersión multivariante (multidimensional) en el que cada variable es re-escalada de forma que el valor mínimo se encuentre en el extremo izquierdo y el máximo en el extremo derecho. La principal utilidad de este gráfico consiste en la identificación de agrupamientos de valores en ciertas observaciones que pueden ser también de naturaleza espacial.
En la siguiente figura, se muestra un PCP (Parallel Coordinate Plot) realizado con GeoDa.
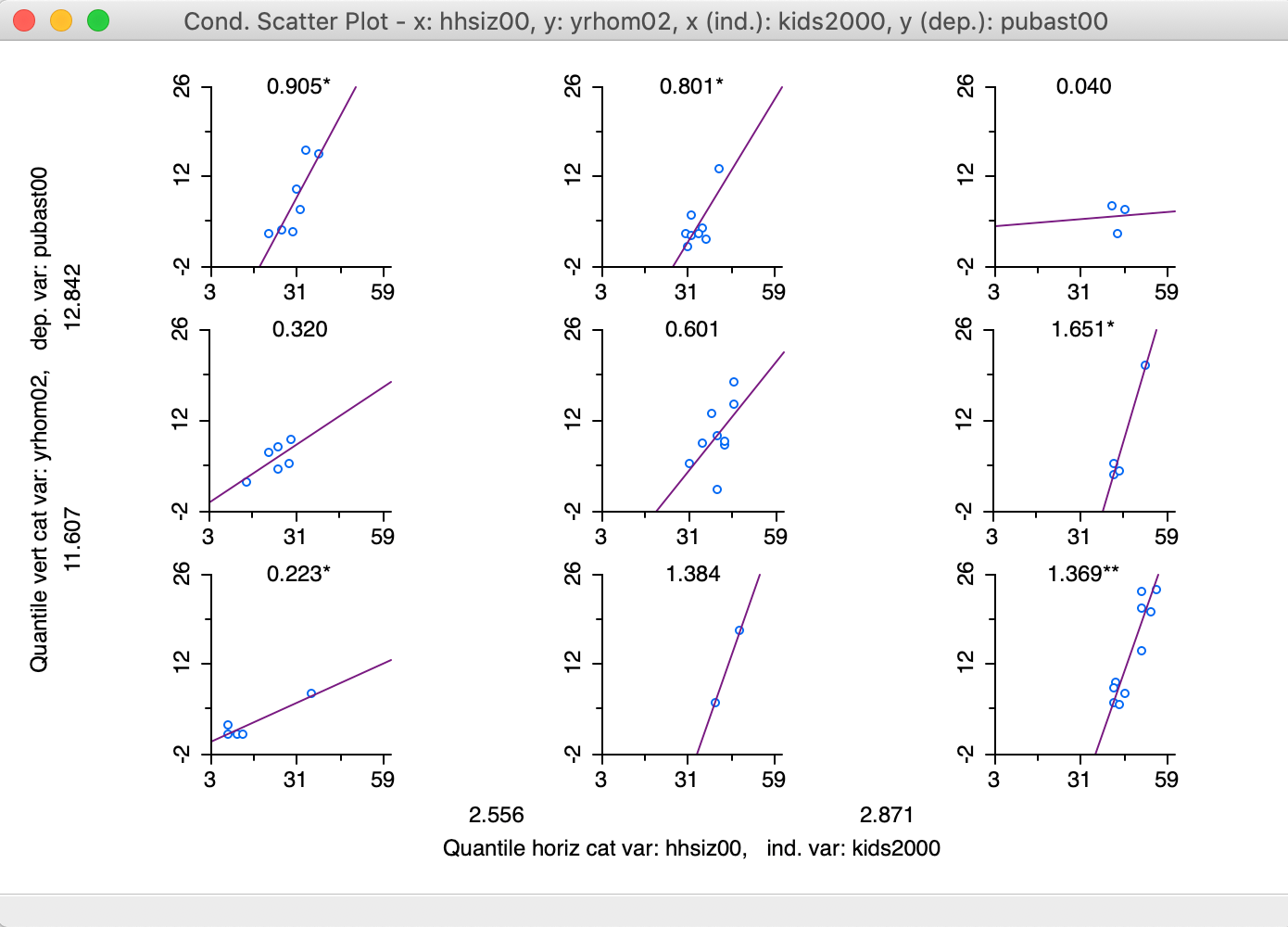
5.2.3 Gráficos (o mapas) condicionales
El principio que subyace en este tipo de gráficos es la utilización de dos variables condicionales que dividen a la muestra de datos en diferentes grupos o categorías. El objetivo de este gráfico consiste en representar, para una tercera variable continua, un gráfico (o mapa) con aquellas observaciones que estén comprendidas dentro de cada categoría.
En la siguiente figura, se muestra un CSP (Conditional Scatter Plot) realizado con GeoDa(Anselin et al., 2021).
5.3 Análisis de datos espacio-temporales
El Análisis Exploratorio de Datos Espacio-Temporales (AEDET) es un caso particular del AEDE multivariante, pues analiza un mismo fenómeno espacial (o corte-transversal) en diferentes momentos del tiempo. Es decir, el AEDET analiza y compara una variable geográfica en dos o más momentos del tiempo. Así al menos lo entienden Anselin et al. (2005) cuando hablan de la correlación espacio-temporal como un caso particular de la correlación multivariante entre variables geográficas.
Otros autores, como Bivand et al. (2013), hacen una clara distinción entre los datos (análisis y métodos) espacio-temporales y los multivariantes, puesto que la variable temporal no debe ser tratada como el resto de variables.
Dentro del mundo socioeconómico, hay fenómenos que requieren del análisis espaciotemporal, como sucede con los modelos macroeconómicos de crecimiento y convergencia o en los fenómenos de difusión o lanzamiento de nuevos productos, entre otros.
5.3.1 Variograma multivariable
Como ya hemos comentado, en geoestadística usamos el término multivariable cuando se analizan conjuntamente múltiples variables especiales dependientes.
En el análisis geoestadístico multivariante es importante discernir dos situaciones. Si en cada lugar de observación tenemos todas las variables medidas hablaremos de datos coubicados (collocated data). En caso contrario, hablaremos de datos no coubicados (non-collocated data).
La principal herramienta para estimar semivarianzas entre diferentes variables es el variograma cruzado, definido para datos coubicados como
\[
\begin{equation}
\gamma_{ij}(h)=\frac{1}{2}E[(Z_i(s)-Z_i(s+h))(Z_j(s)-Z_j(s+h))]
\end{equation}
\] y para datos no coubicados como \[
\begin{equation}
\gamma_{ij}(h)=\frac{1}{2}E[((Z_i(s)-m_i)-(Z_j(s)-m_j))^2]
\end{equation}
\] siendo \(m_i\) y \(m_j\) las medias de las respectivas variables.
Como el análisis multivariable puede involucrar numerosas variables, necesitamos comenzar por organizar la información disponible. Por esa razón, recopilamos todas las especificaciones de datos de observación en un objeto gstat, creado por la función gstat(). Esta función no hace más que ordenar (y, de hecho, copiar) la información necesaria más adelante en un solo objeto.
data:
logCd : formula = log(cadmium)`~`1 ; data dim = 155 x 12
logCu : formula = log(copper)`~`1 ; data dim = 155 x 12
logPb : formula = log(lead)`~`1 ; data dim = 155 x 12
logZn : formula = log(zinc)`~`1 ; data dim = 155 x 12
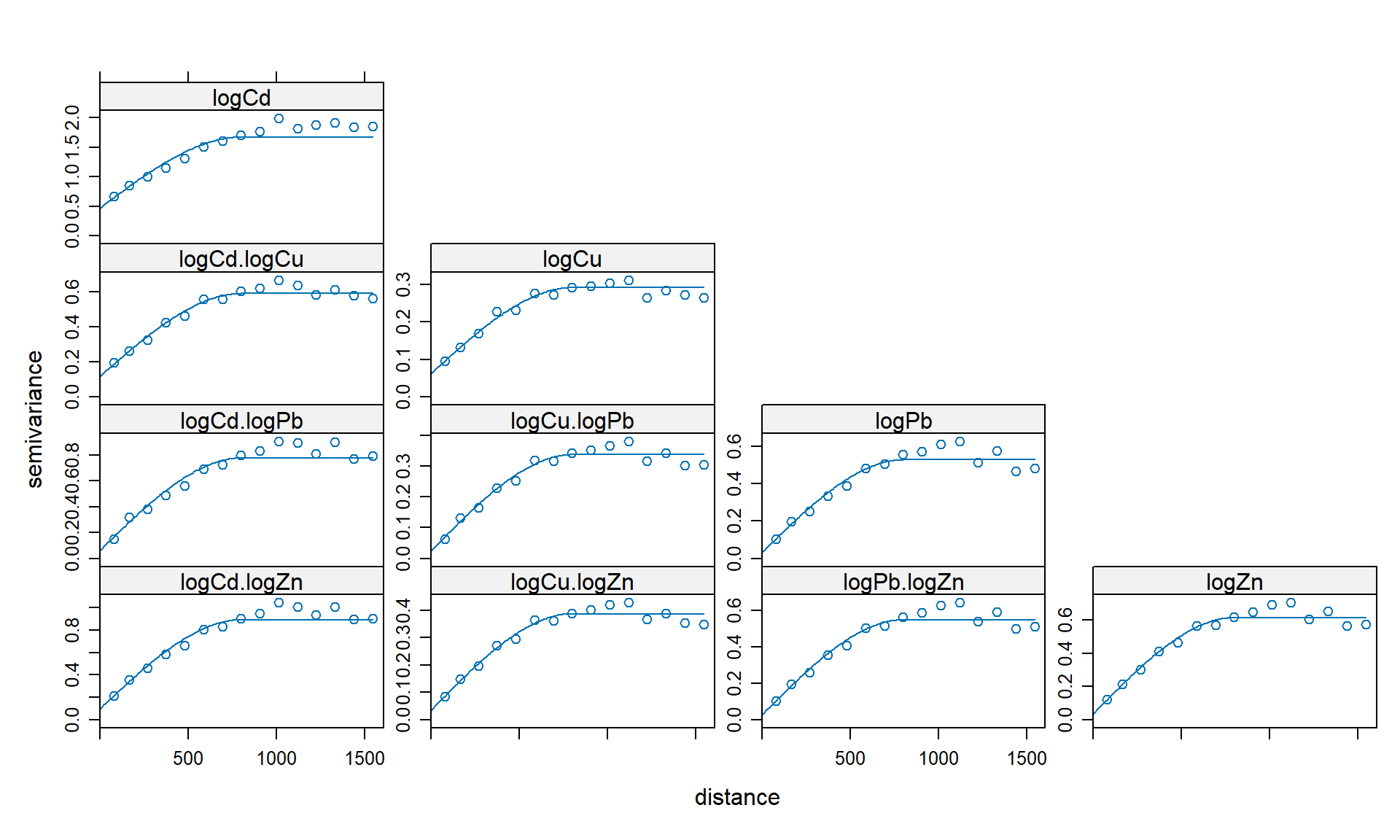
vm <-variogram(g)vm.fit <-fit.lmc(vm, g, vgm(psill=1, model="Sph", range=800, nugget=1))plot(vm, vm.fit)
Por defecto, la función variogram() calcula todos los variogramas directos y cruzados (se puede desactivar). La función fit.lmc() ajusta un modelo lineal de corregionalización, que es un modelo particular que necesita tener componentes de modelo idénticos (en este caso, modelo esférico, rango de 800, etc.).
Como se puede observar en el gráfico anterior, las variables analizadas tienen una fuerte correlación cruzada.
Como estas variables están coubicadas (tenemos datos de las cuatro variables para cada localización), podemos calcular correlaciones directas:
aunque esta información ignora las componentes espaciales.
5.3.2 Predicción multivariable: Cokriging
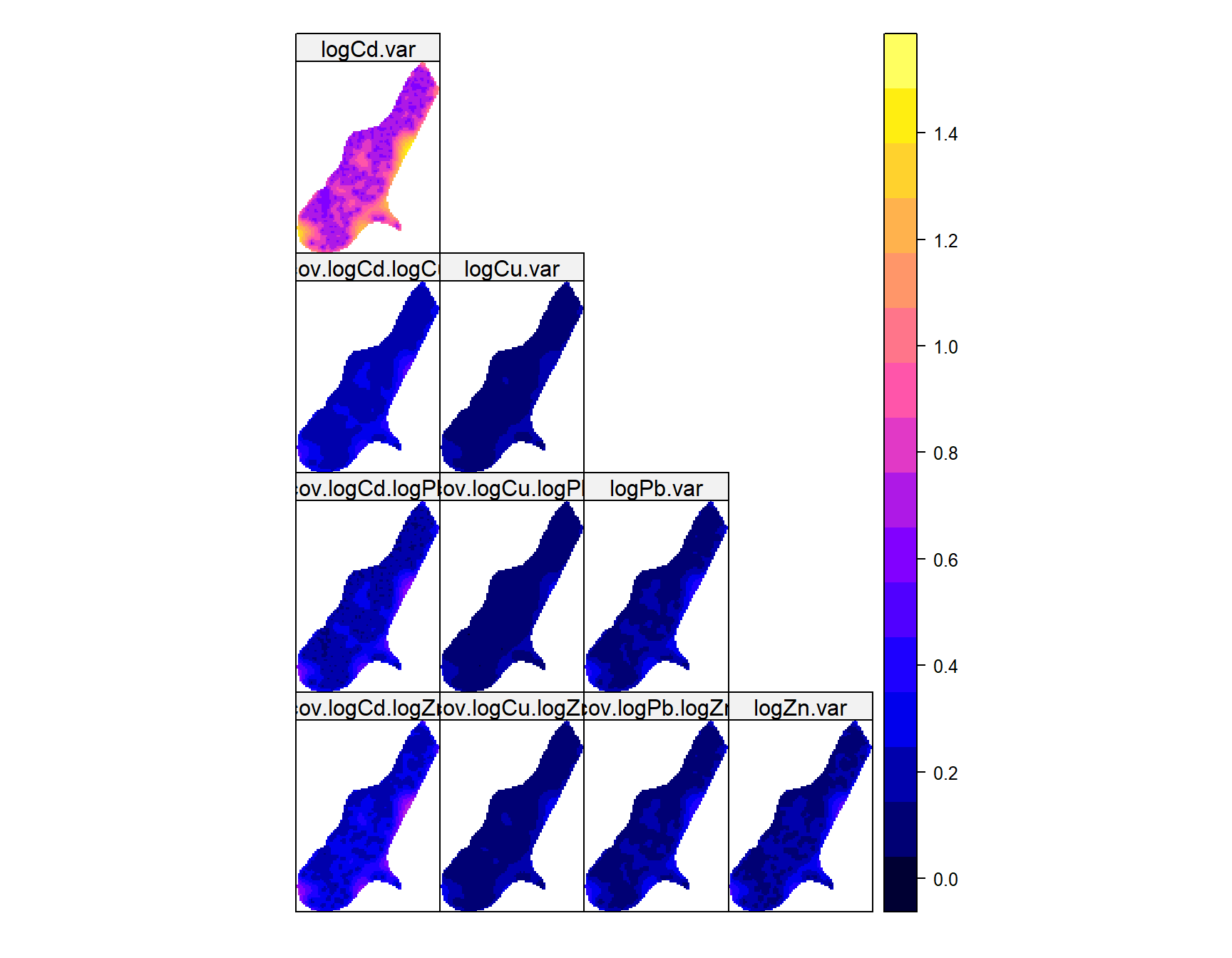
Los métodos de predicción kriging pueden extenderse al análisis multivariable. La idea es observar si múltiples variables pueden tener correlación cruzada, lo que significa que exhiben no solo autocorrelación sino que la variabilidad espacial de la variable \(A\) está correlacionada con la variable \(B\) y, por lo tanto, puede usarse para su predicción, y viceversa. Por lo general, se supone que ambas variables se miden en un conjunto limitado de ubicaciones y la interpolación aborda ubicaciones no medidas.
Esta técnica no se limita a dos variables. Para cada ubicación de predicción, la predicción multivariable para \(q\) variables produce un vector \(q×1\) con una predicción para cada variable y una matriz \(q×q\) con varianzas y covarianzas de error de predicción a partir de las cuales podemos obtener las correlaciones de error:
cok.maps <-predict(vm.fit, meuse.grid)
Linear Model of Coregionalization found. Good.
[using ordinary cokriging]
Las covarianzas de error de cokriging pueden ser valiosas cuando queremos calcular funciones de múltiples predicciones. Supongamos que la variable \(Z_1\) se mide en el momento \(t=1\) y \(Z_2\) en \(t=2\), y ambas variables no están coubicadas. si queremos estimar la diferencia \(Z_2−Z_1\), podemos usar las estimaciones para ambos momentos.
Para el error de predicción de esta diferencia, además de las varianzas del error de predicción para \(\hat{Z}_1\) y \(\hat{Z}_2\), necesitamos la covarianza del error de predicción. La función get.contr() ayuda a calcular el valor predicho y la varianza del error de predicción para cualquier combinación lineal en un conjunto de predictores, obtenidos por cokriging.
5.4 Datos espaciotemporales
5.4.1 Introducción
Como ya hemos visto, y resulta fácil de intuir, los datos espacio-temporales están indexados tanto en el espacio como en el tiempo. Este tipo de datos pueden consistir en un objeto vectorial espacial (puntos, líneas o polígonos) o datos raster, en diferentes momentos.
El primer caso es representativo de los datos de sensores fijos que proporcionan mediciones abundantes en el tiempo pero escasas en el espacio.
El segundo caso encaja con el formato típico de imágenes satelitales, que ofrecen datos de alta resolución espacial dispersos en el tiempo.
Hay varios enfoques de visualización de datos de espacio-temporales que intentan hacer frente a las cuatro dimensiones de los datos \((x,y,z,t)\). Los comentamos a continuación.
Por un lado, los datos pueden concebirse como una colección de instantáneas en diferentes momentos. Estas instantáneas se pueden mostrar como una secuencia de imágenes produciendo una animación (GIF), o se pueden imprimir en una página, mostrando para cada momento del tiempo una instantánea (facet_grid() o facet_wrap()).
Por otro lado, una de las dos dimensiones espaciales se puede colapsar a través de una estadística adecuada (por ejemplo, media o desviación estándar) para producir una gráfica de espacio-tiempo (también conocida como diagrama de Hovmöller).
Finalmente, el objeto espacio-temporal se puede reducir a una serie temporal multivariante (donde cada ubicación es una variable o columna de la serie temporal) y mostrarse con las técnicas de visualización de series temporales vistas en otras asignaturas. Este enfoque es directamente aplicable a los datos espacio-temporales dispersos/escasos en el espacio (por ejemplo, mediciones puntuales en diferentes momentos).
Aquí comentaremos algunos, basándonos en la documentación de las propias librerías. No obstante, para obtener más información se debería hacer una revisión más profunda del paquete R en cuestión.
5.4.2.1 spacetime
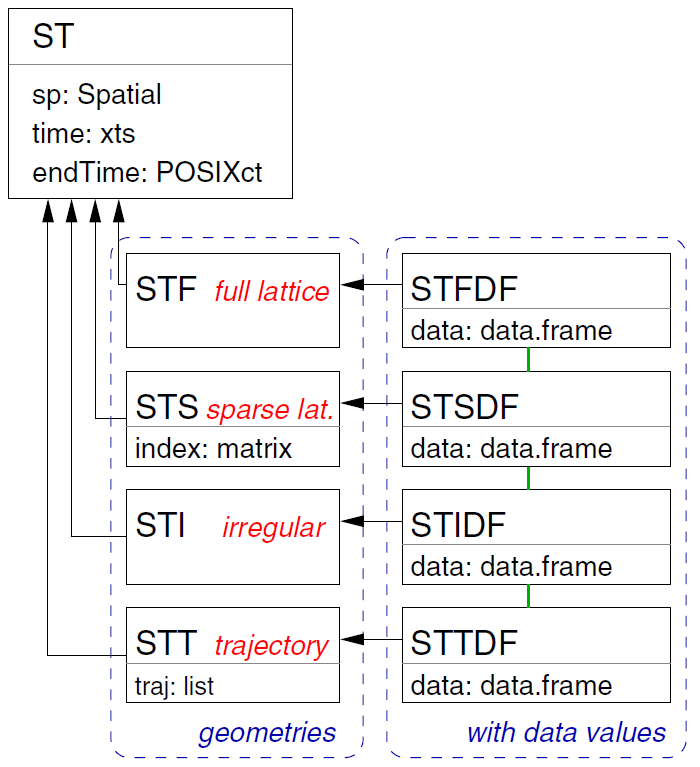
El paquete spacetime(Pebesma, 2022a) se basa en las clases y métodos para datos espaciales del paquete sp, y para datos de series temporales del paquete xts. Define clases para representar cuatro diseños espacio-temporales:
STF, STFDF: malla espacio-temporal completa (full space-time grid) de observaciones para las características espaciales y tiempo de observación, con todas las combinaciones espacio-temporales.
STS, STSDF: disposición de rejilla dispersa (sparse grid layout), almacena sólo las combinaciones no faltantes de datos espacio-temporales en una retícula (lattice).
STI, STIDF: disposición irregular (irregular layout), los puntos temporales y espaciales de los valores medidos no tienen una organización aparente.
El paquete raster(Hijmans, 2023) es capaz de añadir información temporal asociada a las capas de un objeto RasterStack o RasterBrick con la función función setZ(). Esta información puede extraerse con getZ(). Si un objeto Raster incluye esta información, la función zApply() puede puede utilizarse para aplicar una función sobre una serie temporal por capas.
En estos momentos se están desarrollando otros paquetes destinados a ser los sucesores de raster. Se trata de los paquetes terra(Hijmans, 2025) y stars(Pebesma, 2022b).
5.4.2.3 rasterVis
El paquete rasterVis(Perpiñán y Hijmans, 2023) proporciona tres métodos para visualizar objetos raster espacio-temporales:
La función hovmoller() produce diagramas de Hovmöller. Los ejes de este tipo de diagramas suelen ser la longitud o latitud (eje X) y el tiempo (eje Y) con el valor de algún campo agregado representado a través del color.
La función horizonplot() crea gráficos de horizonte, con muchas series temporales en paralelo, cortando el rango vertical en segmentos y superponiéndolos con colores que representan la magnitud y la dirección de la desviación. Cada serie temporal corresponde a una zona geográfica definida con dirXY y promediada con zonal.
La función xyplot() muestra gráficos de series temporales convencionales. Cada serie temporal corresponde a una zona geográfica definida con dirXY y agregada con zonal.
5.4.2.4 rgl
El paquete rgl produce gráficos 3D interactivos en tiempo real. Permite girar, ampliar los gráficos y seleccionar regiones de forma interactiva. Este paquete utiliza la librería OpenGL2 como backend de renderizado, proporcionando una interfaz al hardware de gráficos. Contiene funciones gráficas de alto nivel similares a las de gráficos básicos de R, pero trabajando en tres dimensiones. Además, proporciona funciones de bajo nivel inspiradas en el paquete grid.
5.4.3 Ejemplo
Radiación solar en Galicia (datos disponibles aquí)
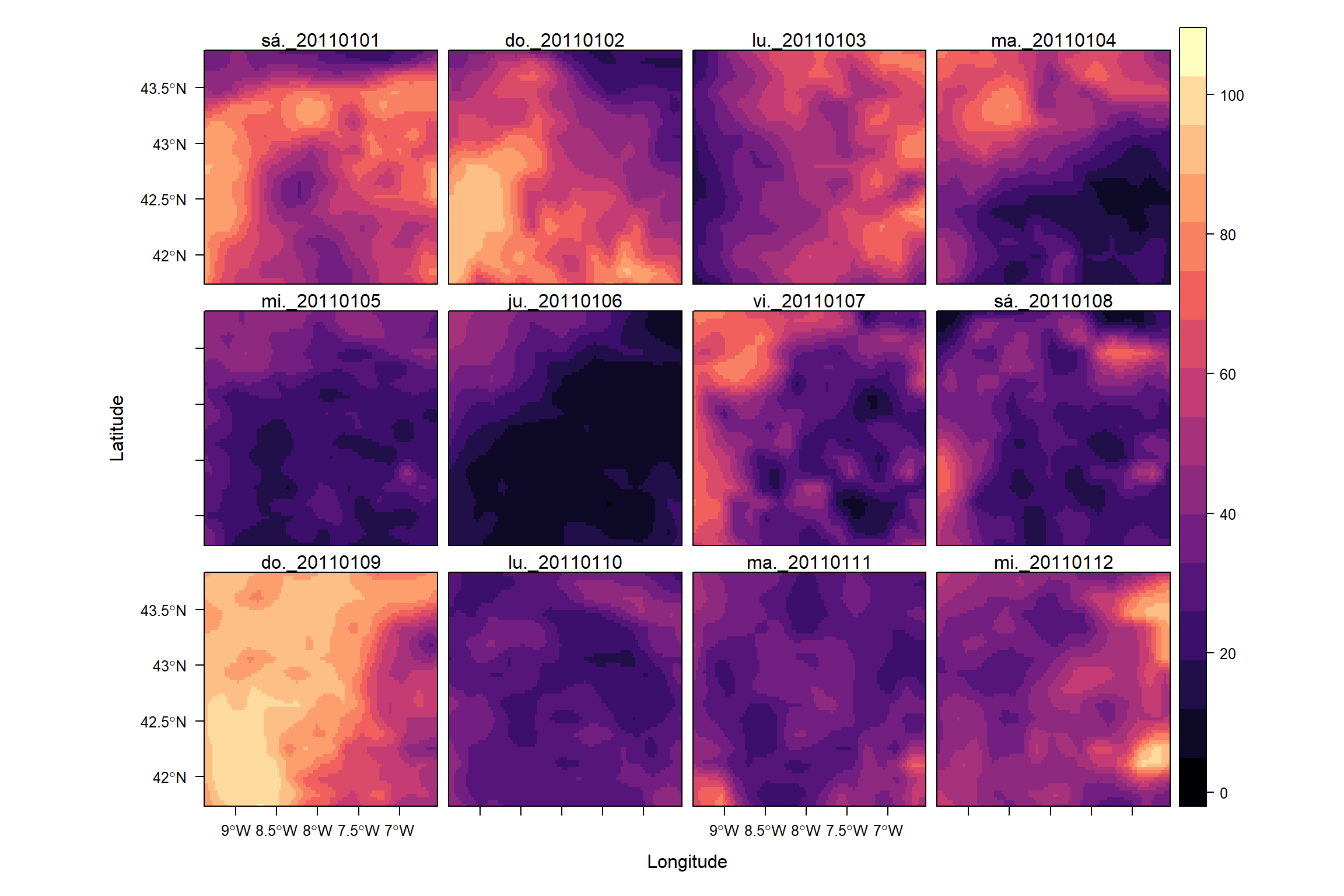
Ahora visualizaremos los métodos descritos anteriormente, basándonos en un objeto raster multicapa de estimaciones de radiación solar diaria en Galicia durante el año 2011.
Estos datos están dispuestos en un Raster-Brick con 365 capas utilizando la función brick() e idexando el tiempo con la función setZ().
Esta objeto multicapa puede mostrarse en un panel mostrando varias instantánea (una para cada momento del tiempo). El problema de este método que sólo podemos mostrar un número limitado figuras. En este caso mostramos los 12 primeros días de la secuencia:
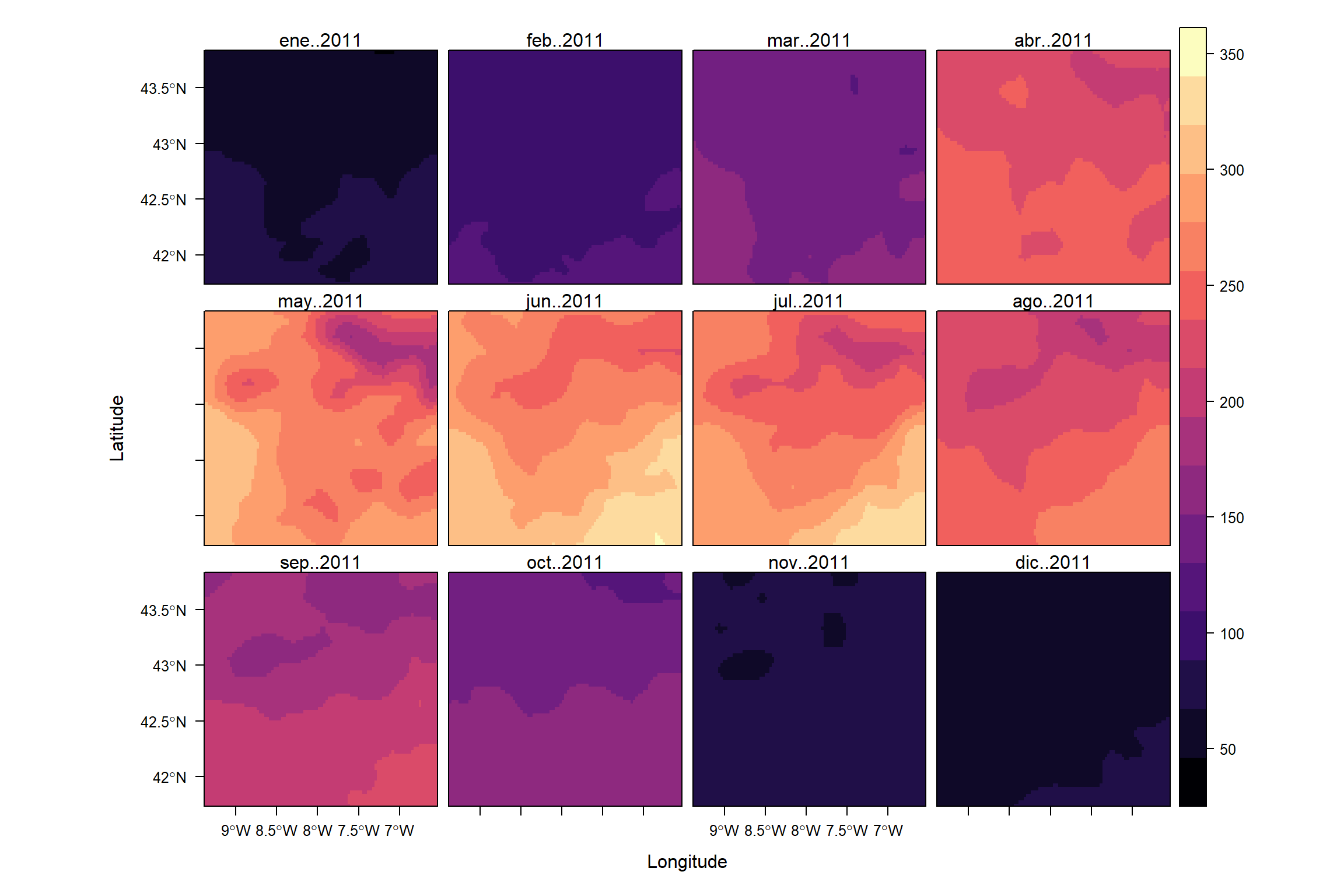
Cuando el número de capas es muy elevado, una solución parcial es agregar los datos, agrupando las capas según una condición temporal. En este caso podemos construir un nuevo raster espacio-temporal con los promedios mensuales utilizando la función zApply() y el parámetro as.yearmon.
SISmm <- raster::zApply(SISdm, by = as.yearmon, fun ='mean')rasterVis::levelplot(SISmm, panel = panel.levelplot.raster)
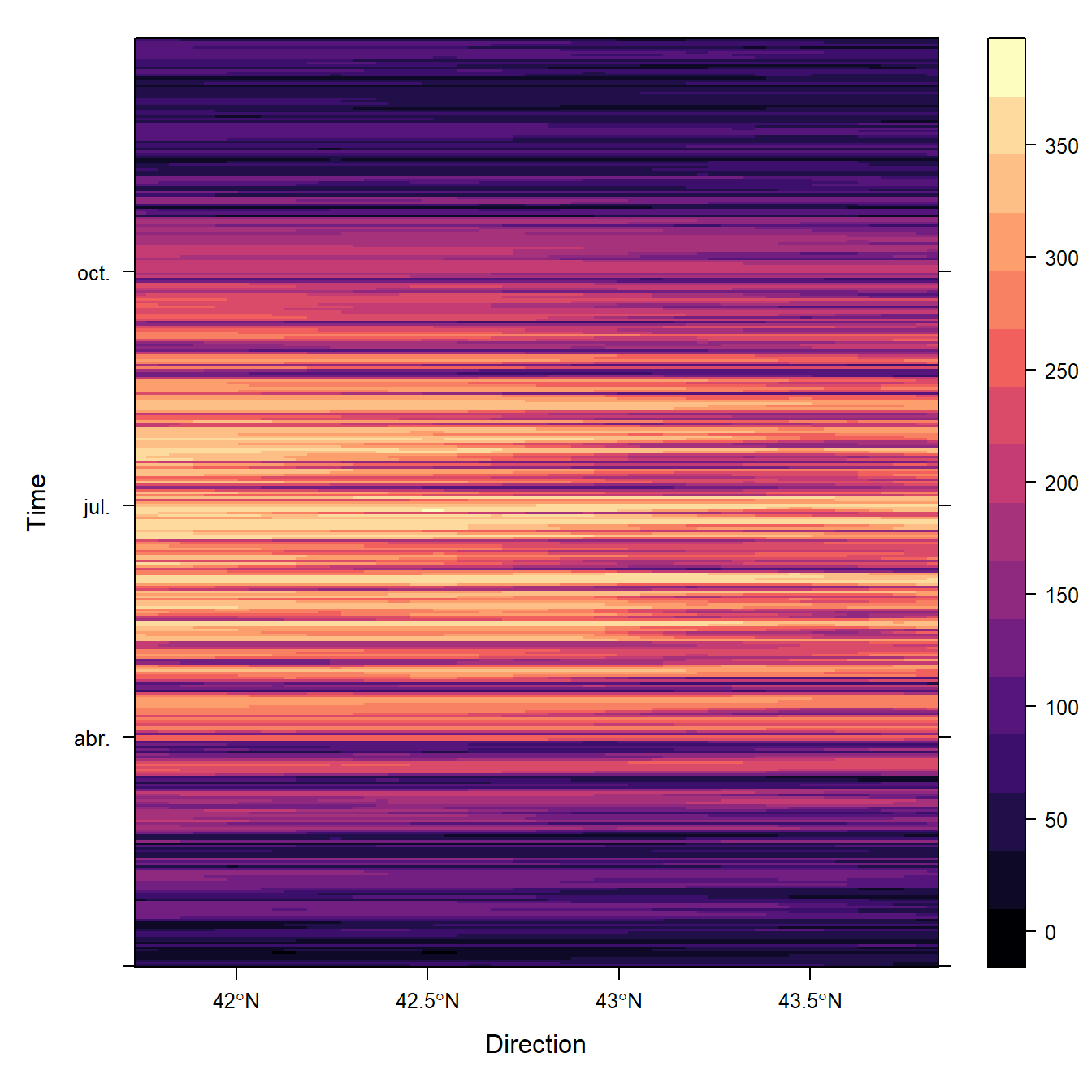
5.4.3.2 Gráfico de Hovmöller
En este gráfico se muestra la evolución temporal de la radiación solar media para cada latitud:
rasterVis::hovmoller(SISdm)
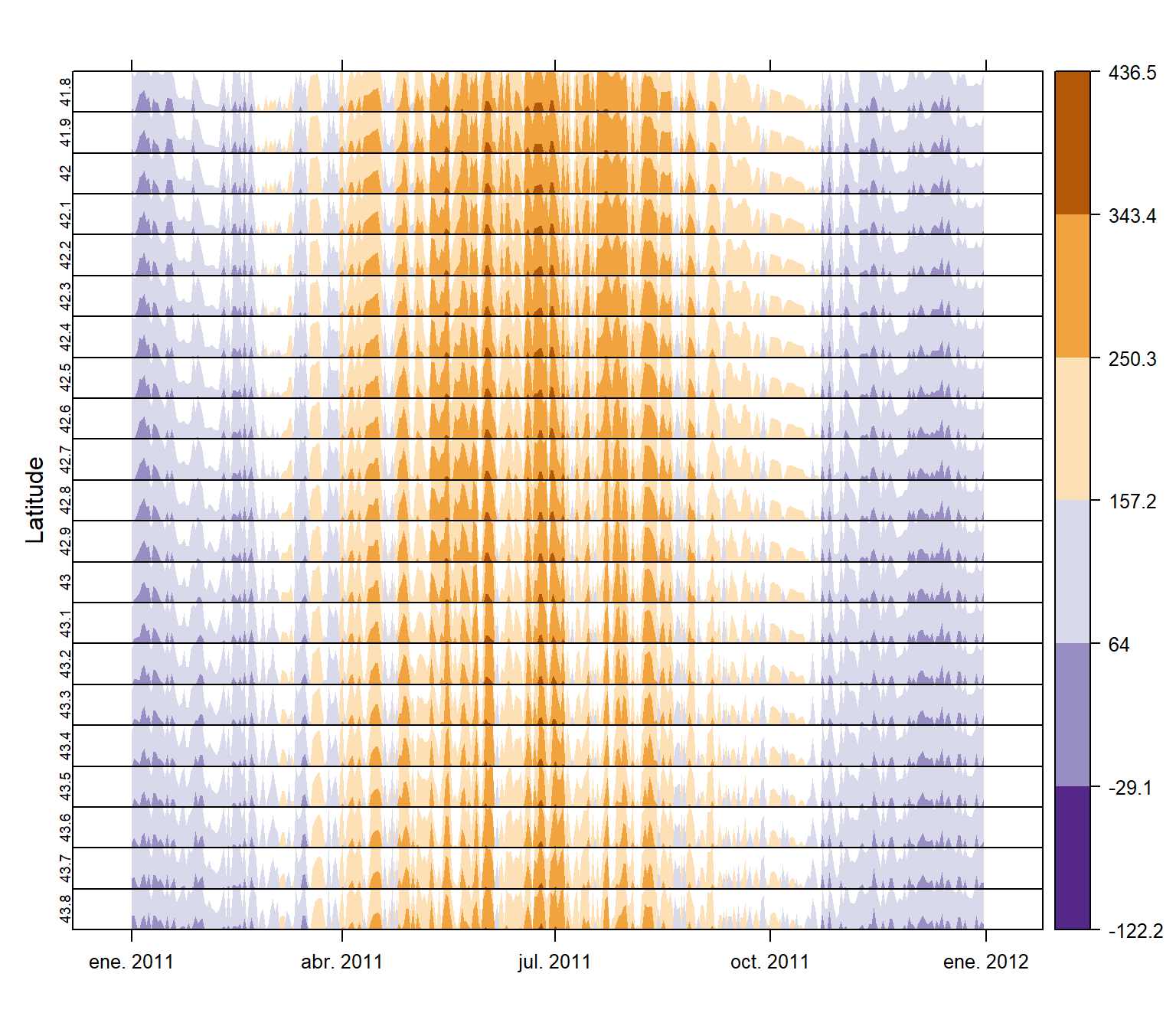
5.4.3.3 Gráfico de horizonte
En este gráfico se muestra, en un gráfico de horizonte, la evolución temporal de la radiación solar para cada latitud:
Los datos espaciotemporales dan para mucho más que una sesión o una unidad didáctica. De hecho, existen manuales dedicados exclusivamente a este tipo de datos, como por ejemplo los que se muestran a continuación (ver Referencias):
Esta asignatura permite conocer e introducir este tipo de datos, si bien queda de parte del lector y de sus propias necesidades, profundizar más en este tipo de datos.
Anselin, L., Li, X., y Koschinsky, J. (2021). GeoDa, From the Desktop to an Ecosystem for Exploring Spatial Data. Geographical Analysis, 54(3), 439-466. https://doi.org/10.1111/gean.12311
Bivand, R., Pebesma, E., y Gómez-Rubio, V. (2013). Applied spatial data analysis with R, Second edition. Springer, NY. http://www.asdar-book.org/
Gelfand, A. E., Schmidt, A. M., Banerjee, S., y Sirmans, C. F. (2004). Nonstationary multivariate process modeling through spatially varying coregionalization. Test, 13, 263-312. https://doi.org/10.1007/BF02595775